










PartiQL dAmazon : un seul langage de requête pour toutes vos données
Quel que soit le lieu ou le format dans lequel elles sont stockées
Amazon vient dannoncer PartiQL, un nouveau langage de requête compatible avec SQL (Structured Query Language). Ce nouveau langage dinterrogation présenté comme « hautement flexible » est censé faciliter la recherche et lextraction efficace de grandes quantités et variétés de données, quel que soit le lieu ou le format dans lequel elles sont stockées.
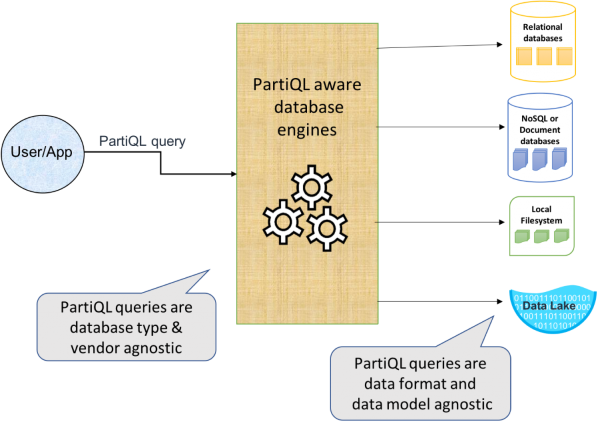
Amazon promet que tant que le moteur de requête utilisé prend en charge PartiQL, vous serez en mesure de traiter (filtrer, assembler, agréger ) de manière intuitive des données structurées à partir de bases de données relationnelles (transactionnelles et analytiques), des données avec ou sans schéma logique défini a priori dans NoSQL et même dans des bases de documents qui autorisent différents attributs pour différentes lignes. Grâce à PartiQL, il serait donc plus facile de fournir un accès cohérent à plusieurs magasins, malgré les différentes hypothèses de schéma des moteurs participants.
PartiQL fournirait une syntaxe et une sémantique qui permettent laccès et le traitement complet et précis des données semi-structurées et imbriquées avec un minimum dextensions dans des formats de données ouverts (tels quun lac de données Amazon S3), tout en composant naturellement avec les fonctionnalités standard du SQL. La syntaxe et la sémantique de PartiQL ne sont liées à aucun format de données particulier. Une requête est écrite de manière identique sur les données sous-jacentes dans les formats JSON, Parquet, ORC, CSV, Ion, ou autres. Les requêtes fonctionnent sur un système de type logique complet qui correspond à divers formats sous-jacents. De plus, même si PartiQL dispose dun nombre dextensions réduit comparé à SQL, celles-ci sont faciles à comprendre, se prêtent à une implémentation efficace et peuvent être associées aisément.
PartiQL est déjà utilisé par Amazon S3 Select, Amazon Glacier Select, Amazon Redshift Spectrum, Amazon Quantum Ledger Database (Amazon QLDB) et les systèmes internes Amazon. En outre, Amazon EMR envoie les requêtes PartiQL vers S3 Select. Les serveurs de Couchbase et davantage de services AWS devraient également prendre en charge PartiQL dans les mois à venir.
PartiQL est entièrement open source sous licence Apache2.0. Amazon indique que nimporte qui peut voir, utiliser, modifier et distribuer le tutoriel, la spécification et une implémentation de référence de son langage de requête « unificateur ». Limplémentation prend en charge lanalyse des requêtes PartiQL par les utilisateurs dans des arbres syntaxiques abstraits que leurs applications peuvent analyser ou traiter et linterprétation directe des requêtes PartiQL. La firme de Seattle estime que le fait de rendre PartiQL open source devrait faciliter lanalyse, lintégration et ladoption de PartiQL par les développeurs. Cest pourquoi elle invite ces derniers à faire part de leurs contributions à lélargissement de la spécification, à lélaboration de la technologie et à laccroissement de son adoption et de son partage au sein de la communauté des utilisateurs. PartiQL nécessite linstallation de Java Runtime (JVM).
Source : Amazon
Et vous ?
Que pensez-vous de cette initiative ?
Voir aussi

 Répondre avec citation
Répondre avec citation





















Partager