













GitHub : des chercheurs estiment que plus de la moitié des codes écrits en Java, Python, C/C++ et JavaScript
sont dupliqués
Une équipe internationale de huit chercheurs n'a pas cherché à mesurer la duplication de GitHub. Leur objectif initial était d'essayer de définir la « granularité » de la copie, c'est-à-dire la quantité de fichiers échangés entre différents clones. Mais en chemin, ils ont atteint un « taux impressionnant de duplication de fichiers. »
Présentée lors de la conférence OOPSLA de cette année à Vancouver, l'université de Californie à Irvine a découvert que sur 428 millions de fichiers sur GitHub, seuls 85 millions sont uniques.
« Des études antérieures ont montré qu'il y a une quantité non triviale de duplication dans le code source. Cet article analyse un corpus de 4,5 millions de projets non forkés hébergés sur GitHub représentant plus de 428 millions de fichiers écrits en Java, C ++, Python et JavaScript. Nous avons découvert que ce corpus ne contient que 85 millions de fichiers uniques. En d'autres termes, 70 % du code sur GitHub est constitué de clones de fichiers créés précédemment. Il existe une variation considérable entre les écosystèmes de langage. JavaScript a le plus haut taux de duplication de fichiers, seulement 6 % des fichiers sont distincts. Java, d'autre part, a le moins de duplication, 60 % des fichiers sont distincts. Enfin, une analyse au niveau du projet montre qu'entre 9 % et 31 % des projets contiennent au moins 80 % de fichiers qui peuvent être trouvés ailleurs. Ces taux de duplication ont des implications pour les systèmes basés sur des logiciels open source ainsi que pour les chercheurs intéressés par l'analyse de bases de code importantes », ont résumé les chercheurs.
Comme lexplique Adrian Colyer, qui a participé au projet, la raison dêtre de l'étude est d'aider les chercheurs à sélectionner des échantillons aléatoires de bases de code dont ils pourraient se servir comme base pour d'autres études (il est courant dans la recherche en génie logiciel d'analyser des projets sur GitHub). En effet, la « sélection aléatoire simple pourrait conduire à des échantillons incluant une duplication élevée, ce qui pourrait fausser les résultats de la recherche », de sorte que l'indice public de duplication de code aide à « comprendre les relations de similarité dans des échantillons de projets, ou à organiser un échantillon pour réduire les doublons. »
Par exemple, selon l'étude, si un chercheur étudie combien de programmes en C et en C ++ utilisent des assertions, la duplication fausse clairement leur résultat. De même, une étude de qualité du logiciel doit prendre en compte la duplication.
Les chercheurs en ont profité pour faire une cartographie des codes dupliqués sur GitHub quils ont baptisée DéjaVu.
Les chercheurs ont évalué la duplication de code en utilisant une variété de techniques de hachage. Identifier le code identique était facile, car ils produisaient des hachages identiques, mais il fallait aussi prendre en compte les logiciels avec de petits changements (espaces ou tabulations), ou même des changements plus importants.
Pour incorporer ces autres doublons dans leur échantillon, les chercheurs ont appliqué un « token hash » appelé SourcererCC qui a capturé des changements mineurs dans les espaces, les commentaires et les commandes pour identifier des clones avec des modifications trop importantes.
Daprès les résultats de leur étude, en termes de pourcentage, cest Java qui sen sort le mieux avec 30 % de ses fichiers qui sont des originaux contre 3 % chez JavaScript.
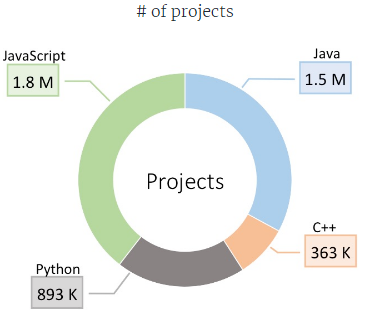
Dans les détails, ils ont analysé 1,8 million de projets non forkés JavaScript, 1,5 million en Java, 893 000 en Python et 363 000 en C++.
Pourquoi une étude portée sur GitHub ?
Les chercheurs ont fait valoir que Github a été l'une des destinations les plus populaires pour les projets de partage, et elle a également gagné en popularité dans la recherche en tant que source d'ensembles de données à extraire pour trouver des modèles d'intérêt. « Lorsque nous expérimentons un logiciel et faisons des déclarations, statistiquement, on pourrait s'attendre à ce que la conclusion soit tirée d'un corpus de logiciels constitué de projets sélectionnés au hasard et indépendants », ont-ils fait valoir.
Selon eux, lindépendance est tenue pour acquise dans plusieurs études, « cependant, il existe plusieurs façons dont un projet peut en influencer un autre, et la réutilisation dun programme en est une façon importante et commune. Un ensemble de données est biaisé s'il y a trop de duplication entre les projets. »
Ils ont mis à la disposition des développeurs une Web App de DéjaVu. Il vous est également possible de télécharger pour chaque langage individuellement les Dumps MySQL.
Web App DéjàVu
Source : résultats de l'étude, billet Colyer

 Répondre avec citation
Répondre avec citation
Partager