











Bonjour,
j'ai une analyse d'impact à réaliser sur une modification de fichier en terme de katakana single byte et double byte.
Pour ceux qui connaissent pas, il s'agit du même caractère mais écris différemment, l'un prenant deux bytes alors que l'autre n'en prend qu'un.
Par exemple : タ et タ
Ces deux caractères sont les mêmes, mais n'ont pas le même code hexa derrière a priori.
Ma question porte sur la façon dont une base de données va stocker cela.
Quand on précise varchar(15), il s'agit de n'importe quel caractère ? Je pourrais donc avoir 15 double bytes et 15 single bytes dans mes champs ? Ou est-ce que cela peut avoir une influence sur la longueur de mon champ ?
Pour info, je connais déjà la réponse sur Oracle, j'ai pu tester le fait qu'un double byte prenait bien deux caractères. Autrement dit, un varchar(15) ne peut contenir que 7 double bytes... mais est-ce que c'est pareil pour les autres bases ? Vous auriez une idée ?
Merci d'avance pour votre réponse.
Steven
 Répondre avec citation
Répondre avec citation

















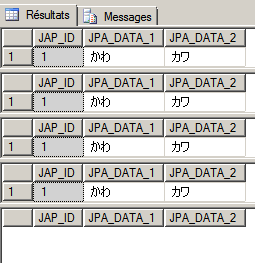
 et que SQL Server offre tant de collations
et que SQL Server offre tant de collations 
Partager