













IBM publie les modèles code de son IA Granite en open-source, afin de résoudre les problèmes des développeurs pour livrer des logiciels fiables, ce modèle serait plus performant que Llama 3, selon IBM.
IBM a annoncé la publication d'une famille de modèles code "Granite" pour la communauté open-source, dans le but de simplifier le codage pour les développeurs de diverses industries. Les modèles code Granite sont conçus pour résoudre les problèmes auxquels les développeurs sont confrontés lorsqu'ils écrivent, testent, déboguent et livrent des logiciels fiables.
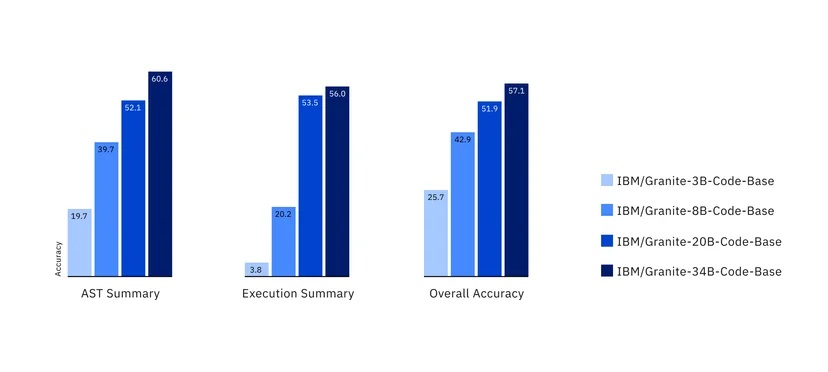
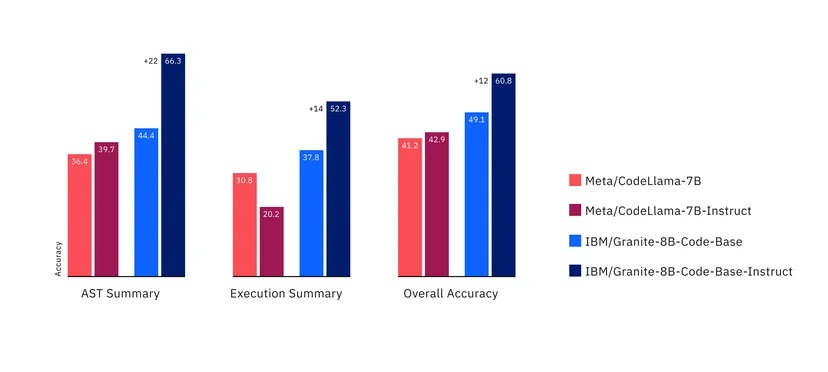
IBM a publié quatre variantes du modèle code "Granite", dont la taille varie de 3 à 34 milliards de paramètres. Les modèles ont été testés sur une série de points de référence et ont surpassé d'autres modèles comparables tels que Code Llama et Llama 3 dans de nombreuses tâches.
Les modèles ont été entraînés sur un ensemble massif de données de 500 millions de lignes de code dans plus de 50 langages de programmation. Ces données d'entraînement ont permis aux modèles d'apprendre des modèles et des relations dans le code, ce qui leur permet de générer du code, de corriger des bogues et d'expliquer des concepts de code complexes.
Les modèles code Granite sont conçus pour être utilisés dans une variété d'applications, y compris la génération de code, le débogage et les tests. Ils peuvent également être utilisés pour automatiser des tâches de routine, telles que la génération de tests unitaires et la rédaction de documentation. Ils répondent à un large éventail de tâches de codage, y compris la modernisation d'applications complexes et les cas d'utilisation à mémoire limitée.
"Nous croyons au pouvoir de l'innovation ouverte et nous voulons toucher le plus grand nombre de développeurs possible", a déclaré Ruchir Puri, responsable scientifique chez IBM Research. "Nous sommes impatients de voir ce qui sera construit avec ces modèles, qu'il s'agisse de nouveaux outils de génération de code, de logiciels d'édition de pointe, ou de tout ce qui se trouve entre les deux."
IBM met en open-source les modèles code de son IA "Granite"
IBM explique le contexte de cette annonce :
Ce que IBM met en open-sourceIBM met à la disposition de la communauté open-source une famille de modèles code Granite. L'objectif est de rendre le codage aussi facile que possible - pour le plus grand nombre de développeurs possible.
Au cours des dernières décennies, les logiciels ont été intégrés dans tous les aspects de notre société. Mais malgré l'augmentation de la productivité que les logiciels modernes ont apportée à notre façon de travailler, l'acte d'écrire, de tester, de déboguer et de livrer des logiciels fiables reste une tâche ardue. Même le développeur le plus compétent doit chercher des astuces et des raccourcis, les langages de code sont constamment mis à jour et de nouveaux langages sont publiés presque tous les jours.
C'est pourquoi IBM Research a commencé à se demander si l'IA pouvait faciliter le développement et le déploiement du code. En 2021, nous avons dévoilé CodeNet, un ensemble de données massif et de haute qualité comprenant 500 millions de lignes de code dans plus de 50 langages de programmation, ainsi que des extraits de code, des problèmes de code et des descriptions. Nous avons vu la valeur qui pourrait être libérée en construisant un ensemble de données qui pourrait former les futurs agents d'IA - ceux que nous avons imaginés pour traduire le code des anciens langages à ceux qui alimentent les entreprises aujourd'hui. D'autres, nous l'avons vu, enseigneraient aux développeurs comment résoudre les problèmes dans leur code, ou même écrire du code à partir d'instructions de base rédigées en anglais simple.
Les grands modèles de langage (LLM) formés sur le code sont en train de révolutionner le processus de développement de logiciels. De plus en plus, les LLM de code sont intégrés dans des environnements de développement de logiciels afin d'améliorer la productivité des programmeurs humains, et les agents basés sur les LLM se révèlent prometteurs dans le traitement autonome de tâches complexes. La réalisation du plein potentiel des LLM de code nécessite un large éventail de capacités, notamment la génération de code, la correction des bogues, l'explication et la documentation du code, la maintenance des référentiels, et bien plus encore.
L'énorme potentiel des LLM qui a émergé au cours des dernières années a alimenté notre désir de transformer notre vision en réalité. Et c'est exactement ce que nous avons commencé à faire avec la famille de produits IBM watsonx Code Assistant (WCA), comme WCA for Ansible Lightspeed pour l'automatisation informatique, et WCA for IBM Z pour la modernisation des applications. WCA for Z utilise une combinaison d'outils automatisés et le propre grand modèle de langage code de Granite de 20 milliards de paramètres d'IBM que les entreprises peuvent utiliser pour transformer les applications COBOL monolithiques en services optimisés pour IBM Z.
Nous nous sommes efforcés de trouver des moyens de rendre les développeurs plus productifs, en leur faisant passer moins de temps à essayer de comprendre pourquoi leur code ne s'exécute pas ou comment faire communiquer une base de code héritée avec des applications plus récentes. C'est pourquoi nous annonçons aujourd'hui que nous mettons en open-source quatre variantes du modèle code d'IBM Granite.
IBM publie une série de modèles code Granite à décodeur seul pour les tâches de génération de code, entraînés avec du code écrit dans 116 langages de programmation. La famille de modèles code Granite se compose de modèles dont la taille varie de 3 à 34 milliards de paramètres, à la fois dans un modèle de base et dans des variantes de modèles de suivi d'instructions. Ces modèles ont un large éventail d'utilisations, allant des tâches de modernisation d'applications complexes aux cas d'utilisation à mémoire restreinte sur les appareils.
L'évaluation sur un ensemble complet de tâches a montré que ces modèles code Granite correspondent systématiquement à l'état de l'art parmi les LLM de code open-source actuellement disponibles. La famille de modèles polyvalents a été optimisée pour les flux de travail de développement de logiciels d'entreprise et donne de bons résultats dans toute une série de tâches de codage, y compris la génération de code, la correction et l'explication.
Ces modèles sont disponibles sur Hugging Face, GitHub, watsonx.ai et RHEL AI, la nouvelle plateforme de modèles de base de Red Hat pour développer, tester et déployer des modèles d'IA génératifs. Les modèles code de base sous-jacents sont les mêmes que ceux utilisés pour entraîner WCA dans des domaines spécialisés.
Tous les modèles ont été entraînés sur des données collectées conformément aux principes éthiques d'IBM en matière d'IA et aux conseils de l'équipe juridique d'IBM pour une utilisation digne de confiance en entreprise. Ces modèles Granite Code sont publiés sous la licence Apache 2.0.
IBM publie également les modèles Granite Code Instruct. Il s'agit de la méthodologie d'instruction utilisée sur les modèles pour les affiner, en utilisant une combinaison de commits Git associés à des instructions humaines et à des ensembles de données d'instructions de code générées synthétiquement en open-source.
Pourquoi IBM met les modèles code Granite open-source ?
IBM répond à cette question en déclarant :
Que permet les modèles code Granite ?Nous croyons au pouvoir de l'innovation ouverte, et pour arriver à un avenir où écrire du code sera aussi facile que de parler à un assistant en permanence, nous voulons toucher le plus grand nombre de développeurs possible. Aucun système efficace n'est jamais créé par un seul individu - le meilleur travail repose sur la connaissance collective de ceux qui nous ont précédés.
Alors que la popularité générale des modèles d'IA générative est montée en flèche ces dernières années, l'adoption par les entreprises a été plus lente, et ce pour de bonnes raisons. Dans le monde plus large de la recherche et du déploiement du LLM, les principaux modèles ont maintenant atteint des dizaines de milliards de paramètres, beaucoup d'entre eux en ayant 70 milliards ou plus. Bien que cela soit utile pour les organisations qui cherchent à construire des chatbots généralisés qui comprennent un large éventail de sujets, ces modèles sont coûteux en termes de calcul à former et à exécuter. Pour les entreprises, les modèles massifs peuvent devenir difficiles à gérer pour des tâches plus spécifiques, car ils sont remplis d'informations non pertinentes et entraînent des coûts d'inférence élevés.
De nombreuses entreprises ont été réticentes à adopter les LLM à des fins commerciales pour plusieurs raisons qui ne se limitent pas au coût. La licence de ces modèles n'est souvent pas claire, et on ignore souvent comment ces modèles ont été formés, et comment les données ont été nettoyées et filtrées pour des éléments tels que la haine, l'abus et le blasphème.
"Nous transformons le paysage de l'IA générative pour les logiciels en publiant les LLM de code les plus performants et les plus rentables, permettant ainsi à la communauté open-source d'innover pour de nombreux cas d'utilisation, sans aucune restriction - pour la recherche, les cas d'utilisation commerciale et au-delà", a déclaré Ruchir Puri, scientifique en chef chez IBM Research, qui dirige les efforts d'IBM pour mettre les assistants de codage à la portée du monde entier. "Je suis très enthousiaste quant à l'avenir des logiciels avec l'IA générative".
Puri pense que pour de nombreux cas d'utilisation en entreprise, la variante du modèle code Granite 8B que nous avons lancée sera la bonne combinaison de poids, de coût d'exploitation et de capacité. Mais nous proposons également des versions plus légères et plus lourdes que toute personne de la communauté open-source peut essayer pour voir si elles répondent mieux à ses besoins.
Pour de nombreux développeurs, l'écriture du code n'est pas vraiment ce qui prend le plus de temps. Il s'agit plutôt de tester ce qu'ils ont écrit, de s'assurer qu'il fonctionne comme prévu, et de trouver et de corriger les bogues éventuels. À l'heure actuelle, le flux de travail d'un développeur peut l'amener à passer constamment du code sur lequel il travaille à divers forums en ligne pour trouver des réponses à ses problèmes. C'est syncopé et cela prend souvent beaucoup de temps.
Avec des outils construits sur les modèles code Granite d'IBM, on peut envisager des cas d'utilisation en entreprise pour les développeurs. Il pourrait s'agir d'agents capables d'écrire du code pour les développeurs, d'outils capables d'expliquer pourquoi le code ne fonctionne pas et comment le réparer. De nombreuses autres tâches quotidiennes mais essentielles qui font partie de la journée d'un développeur - de la génération de tests unitaires à la rédaction de documentation ou à l'exécution de tests de vulnérabilité - pourraient être automatisées à l'aide de ces modèles.
Et on peut voir la valeur de l'utilisation de ces modèles pour moderniser les applications critiques qui doivent rester sécurisées, résilientes et, surtout, en ligne. Grâce aux systèmes génératifs construits sur les modèles Granite, les développeurs peuvent créer de nouvelles façons de traduire les codes hérités, comme COBOL, en langages plus modernes, comme Java. C'est l'une des principales utilisations des modèles de code qu'IBM a vues lorsqu'elle a commencé à plonger dans le monde de l'IA pour le code, et elle reste l'une des plus importantes.
Doubler les paramètres
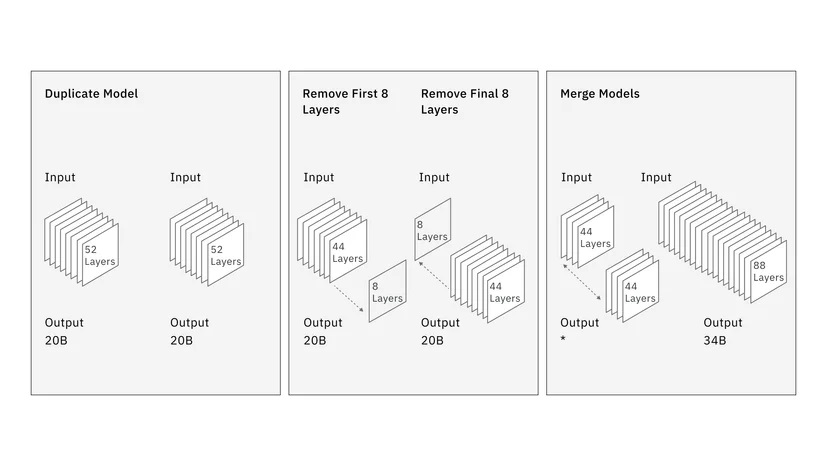
Pour la version 34B du modèle, IBM annonce avoir utilisé une nouvelle méthode appelée "depth upscaling" pour entraîner le modèle. Tout d'abord, ils ont créé une version dupliquée de la variante 20B, qui comporte 52 couches. Ils ont supprimé les huit dernières couches de la première version du modèle 20B et les huit premières de la deuxième version. Ils ont ensuite fusionné les deux versions pour créer un nouveau modèle comportant 88 couches. Ils avons utilisé la même fenêtre contextuelle de 8 192 jetons pour le pré-entraînement des modèles 20B et 34B.
Performances des modèles
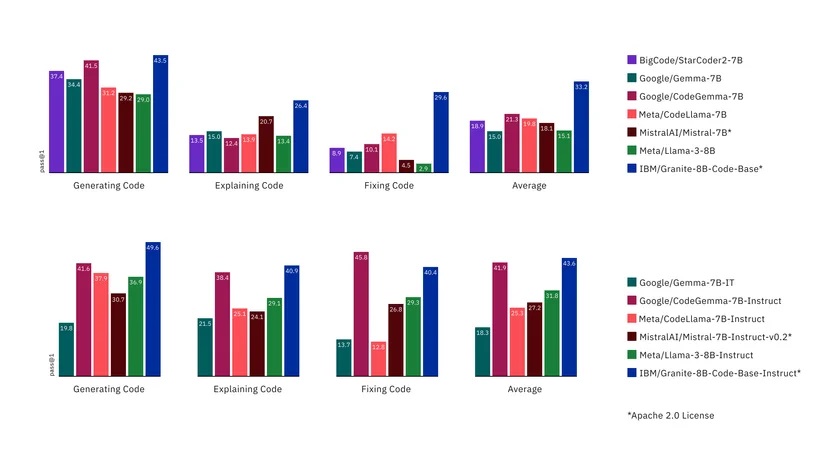
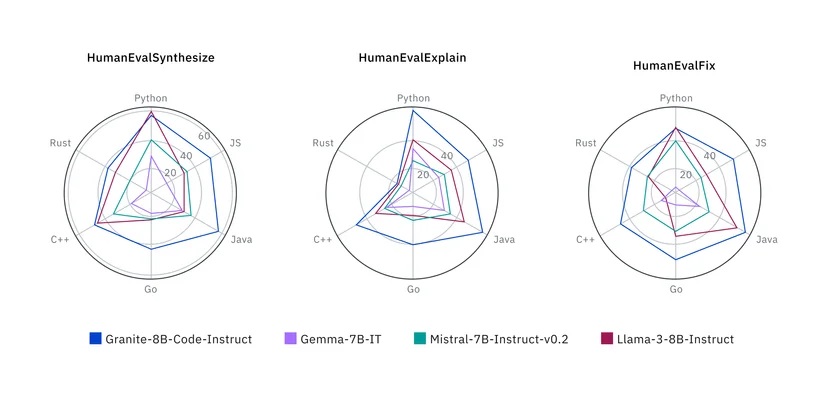
Lors des tests effectués par rapport à une série d'autres modèles, y compris ceux qui ont été ouverts sous licence Apache 2.0, et des modèles plus propriétaires, IBM a constaté que ses modèles étaient capables de rivaliser dans une série de tâches. En testant des benchmarks tels que HumanEvalPack, HumanEvalPlus et RepoBench, ils ont constaté d'excellentes performances en matière de synthèse, de correction, d'explication, d'édition et de traduction de code, dans la plupart des principaux langages de programmation, notamment Python, JavaScript, Java, Go, C++ et Rust.
Selon IBM, ses modèles peuvent surpasser certains modèles deux fois plus grands, comme le Code Llama, et bien que d'autres modèles puissent être légèrement plus performants dans certaines tâches comme la génération de code, aucun modèle n'a pu atteindre un niveau élevé en matière de génération, de correction et d'explication - à l'exception de Granite.
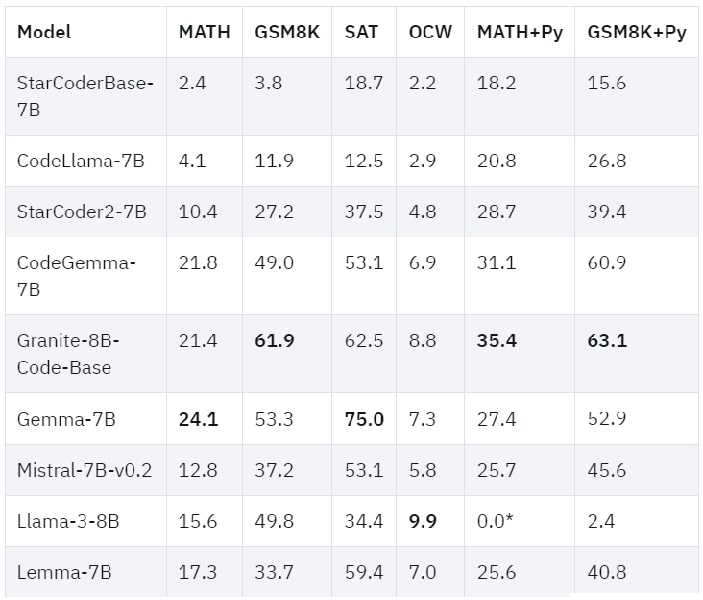
Les modèles disposeraient d'un mélange unique de sources de données qui, selon l'équipe, les distingue. Ils ont utilisé GitHub Code Clean, StarCoderData, ainsi que d'autres dépôts de code publics et problèmes sur GitHub. Combinées aux métadonnées robustes de CodeNet, qui décrivent les problèmes de code en langage clair, elles ont mélangé les sources de code, la documentation en langage naturel et les problèmes de code d'une manière spécifique pour entraîner les modèles.
Les modèles de base ont été entraînés à partir de zéro sur 3 000 à 4 000 milliards de jetons provenant de 116 langages de programmation, ainsi que sur 500 milliards de jetons avec un mélange conçu de données de haute qualité provenant du code et du langage naturel par IBM, ce qui a amélioré la capacité de raisonnement des modèles et leurs compétences en matière de résolution de problèmes, qui sont essentielles pour la génération de code.
Prochaines étapes
IBM concluent :
Source : IBMAvec les modèles code Granite, nous mettons à la disposition de la communauté des modèles qui, selon nous, peuvent rivaliser avec n'importe quel modèle comparable. Nous sommes impatients de voir ce qui sera construit avec ces modèles, qu'il s'agisse de nouveaux outils de génération de code, de logiciels d'édition de pointe ou de tout ce qui se trouve entre les deux.
Il ne s'agit là que d'un aspect de la grande famille des modèles Granite d'IBM qui ont été conçus, incubés et diffusés au sein d'IBM Research. Dans les semaines à venir, nous vous en dirons plus sur d'autres modèles et modalités qui, selon nous, contribueront à façonner l'avenir de l'informatique de manière passionnante.
Et vous ?
Quel est votre avis sur cette annonce ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager