Correction d'erreurs non naturelles : GPT-4 peut presque parfaitement traiter un texte brouillé non naturel
Bien que les grands modèles de langage (LLM) aient atteint des performances remarquables dans de nombreuses tâches, leur fonctionnement interne reste mal connu. Dans cette étude, nous présentons de nouvelles perspectives expérimentales sur la résilience des LLM, en particulier GPT-4, lorsqu'ils sont soumis à de nombreuses permutations au niveau des caractères. Pour étudier cela, nous proposons d'abord le banc brouillé, une suite conçue pour mesurer la capacité des LLM à traiter des entrées brouillées, en termes de récupération de phrases brouillées et de réponse à des questions dans un contexte brouillé. Les résultats expérimentaux indiquent que les LLM les plus puissants démontrent une capacité similaire à la typoglycémie, un phénomène où les humains peuvent comprendre le sens des mots même lorsque les lettres à l'intérieur de ces mots sont brouillées, tant que la première et la dernière lettre restent en place.
De manière plus surprenante, nous avons constaté que seul GPT-4 traite presque parfaitement les entrées contenant des erreurs non naturelles, même dans des conditions extrêmes, une tâche qui pose des défis significatifs aux autres LLM et souvent même aux humains. Plus précisément, GPT-4 peut presque parfaitement reconstruire les phrases originales à partir des phrases brouillées, en réduisant la distance d'édition de 95 %, même lorsque toutes les lettres de chaque mot sont entièrement brouillées. Il est contre-intuitif que les LLMs puissent montrer une telle résilience malgré une perturbation sévère de la tokenisation d'entrée causée par un texte brouillé.
Conclusion
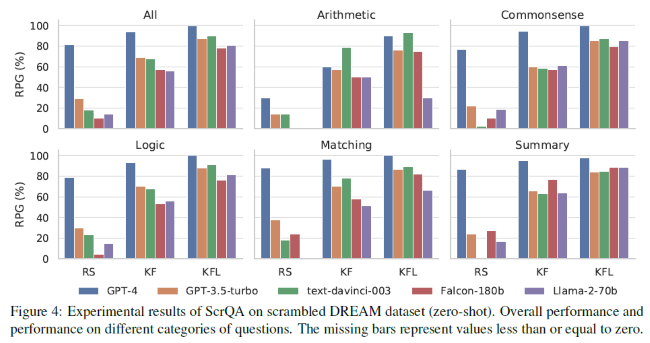
Dans cette étude, nous proposons Scrambled Bench, une suite de tests pour mesurer la capacité des LLMs à gérer le texte brouillé, y compris deux tâches (c'est-à-dire, la récupération de phrases brouillées et la réponse à des questions brouillées) et construire des ensembles de données brouillées basées sur RealtimeQA, DREAM et AQuA-RAT. Bien que le texte brouillé modifie radicalement la tokenisation, nous démontrons que les LLM les plus puissants sont capables de traiter le texte brouillé à des degrés divers.
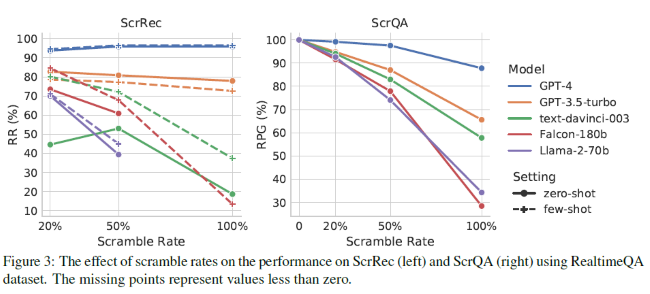
Cependant, la plupart des LLMs ont des difficultés à traiter des textes brouillés à un degré extrême (c'est-à-dire, 100% de brouillage aléatoire). Étonnamment, pour les deux tâches, GPT-4 montre de bons résultats et surpasse les autres modèles par une grande marge. Pour la tâche de récupération de phrases brouillées, GPT-4 peut récupérer les phrases en réduisant la distance d'édition de 95 %, même dans un contexte de brouillage aléatoire à 100 %. Pour la tâche de réponse à des questions brouillées, GPT-4 peut maintenir une proportion très élevée de sa précision originale en utilisant un contexte brouillé.












Pensez-vous que cette étude est crédible ou pertinente ?

 Répondre avec citation
Répondre avec citation


 (Les permutations sur les lettres c'était à la mode au 19e siècle, mais attention, celles décrites par Jules Verne sont bien plus avancées. )
(Les permutations sur les lettres c'était à la mode au 19e siècle, mais attention, celles décrites par Jules Verne sont bien plus avancées. )

Partager