










Python 3.11 et C++ : quelles sont les performances de ces deux langages en matière de simulation ?
Comparaison de vitesse à l'aide d'une simulation scientifique
Python 3.11, la dernière version langage, serait significativement plus rapide que les versions précédentes. Python 3.11 présenterait des améliorations de performance spectaculaires par rapport à Python 3.10 et aux versions antérieures. Après un test réalisé récemment, Bram Wasti, ingénieur système chez Meta, affirme que Python 3.11 est 3 fois plus rapide que la version 3.8. Wasti pense tout de même qu'il y a encore du chemin à faire en matière d'améliorations des performances.
Si Python a gagné en popularité, en particulier dans le domaine de la science des données, que représente ce gain de vitesse face à des langages comme C++ dans le même domaine ? C'est la question à laquelle a tenté de répondre un développeur en proposant un benchmark spécialement conçu pour cette discipline (science des données).
Un langage qui gagne en popularité, en particulier dans le domaine de la science des données
Depuis un an déjà, Python occupe la première place de l'index TIOBE. Lors de son arrivée en pole position, Paul Jansen, PDG de Tiobe, notait déjà que c'était une première en 20 ans :
« Pour la première fois depuis plus de 20 ans, nous avons un nouveau chef de file : le langage de programmation Python. L'hégémonie de longue date de Java et C est terminée. Python, qui a commencé comme un simple langage de script, comme alternative à Perl, est devenu mature. Sa facilité d'apprentissage, son énorme quantité de bibliothèques et son utilisation répandue dans toutes sortes de domaines en ont fait le langage de programmation le plus populaire d'aujourd'hui. Félicitations Guido van Rossum ! Proficiat ! »
Python est un langage de programmation interprété, multi-paradigme et multi-plateformes. Il favorise la programmation impérative structurée, fonctionnelle et orientée objet. Il est doté d'un typage dynamique fort, d'une gestion automatique de la mémoire par récupérateur de mémoire et d'un système de gestion d'exceptions ; il ressemble ainsi à Perl, Ruby, Scheme, Smalltalk et Tcl.
Python gagne en popularité ces temps-ci, en partie à cause de l'essor de la science des données et de son écosystème de bibliothèques logicielles d'apprentissage automatique comme NumPy, Pandas, TensorFlow de Google et PyTorch de Facebook.
En effet, Python continuerait d'être la norme et la compétence la plus recherchée dans le domaine de la science des données, dépassant de loin les autres technologies et outils, comme R, SAS, Hadoop et Java. C'est ce que suggère une analyse réalisée par Terence Shin, un spécialiste des données, qui a indiqué que l'adoption de Python pour la science des données continue de croître alors même que le langage R, plus spécialisé, est en déclin. Bien entendu, cela ne veut pas dire que les spécialistes des données vont abandonner R de sitôt. L'on continuera probablement à voir Python et R utilisés pour leurs forces respectives.
Entre Python 3.11, Cython et C++, qui est le plus rapide ?
Multi-Agent AI s'est amusé à comparer les performances de Python 3.11, Cython vs C++ pour les simulations, indiquant que son approche est adaptée aux scientifiques des données et aux personnes ayant des connaissances dans le domaine qui souhaitent créer une simulation ou quelque chose de similaire : « il devrait être clair à l'avance que C++ est toujours plus rapide que Python. La question est de savoir de combien ? »
Pour mémoire, Cython est un langage de programmation et un compilateur qui simplifient l'écriture d'extensions compilées pour Python. La syntaxe du langage est très similaire à Python mais il supporte en plus un sous-ensemble du langage C/C++. Le premier intérêt de Cython est qu'il produit du code nettement plus performant.
Comme exemple de simulation scientifique, voici les résultats d'une simulation de Multi-Agent AI :
Un système de simulation à grande échelle ne doit pas être un programme monolithique où tout se fait au même endroit. Il est logique de séparer par exemple la simulation de base à partir de la visualisation ou de l'analyse des données. Pour cet exercice, Multi-Agent AI s'est intéressé uniquement aux performances de la simulation, et la visualisation est donc déplacée vers un autre programme qui n'est pas traité ici.
De toute évidence, un système de simulation doit communiquer avec la visualisation, soit hors ligne à l'aide de fichiers de données de sortie, soit en ligne à l'aide de flux réseau, par exemple. Ces deux méthodes sortent du cadre de cet exercice. En fait, toutes les sorties sont simplement désactivées à cet effet.
Python 3.10 et Python 3.11
La simulation est une simple simulation spatiale de la relation prédateur-proie. Tous les animaux, prédateurs et proies, sont modélisés comme des agents. La programmation orientée objet est un choix naturel. Chaque agent est un objet, et nous avons différents types d'agents. Multi-Agent AI définit le comportement générique d'un agent dans la classe Agent(). C'est la responsabilité de la méthode update() de calculer la nouvelle position d'un agent. L'ensemble de la simulation est assez simple, mais elle montre un comportement assez complexe.
Code Python : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
Comment mesurer le temps
Une fois que nous avons décidé de mesurer la rapidité d'un programme, nous devons définir exactement comment nous allons le faire. Au début, cela semble être une tâche triviale. Exécutez simplement le programme et mesurez le temps qu'il a fallu.
La simulation test est initialement peuplée de prédateurs, de proies et de plantes. Ils ont chacun une position aléatoire. Or, il est connu d'ensemencer le générateur de nombres aléatoires à l'aide d'une valeur fixe. Cela garantit que si vous exécutez le même programme deux fois, le résultat sera le même.
Si vous écrivez un programme dans deux langages différents, il peut y avoir de subtiles différences de comportement. Dans le cas de simulations comme celle que nous utilisons ici, par exemple, les erreurs d'arrondi peuvent faire la différence. Un langage peut utiliser une méthode différente pour faire de l'arithmétique ou utiliser une notation interne et une précision différentes pour les nombres à virgule flottante.
Même avec exactement le même point de départ, le résultat peut être complètement différent, et donc aussi le temps d'exécution.
Une approche possible consiste à amorcer le générateur de nombres aléatoires en utilisant une valeur aléatoire, comme l'heure actuelle. Exécutez ensuite l'expérience plusieurs fois et utilisez un temps d'exécution moyen.
Code Python : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
Il existe une commande UNIX appelée time qui mesure le temps d'exécution d'un autre programme. C'est très pratique pour des estimations rapides. Les valeurs qu'il rapporte sont :
- real : Temps réel écoulé (horloge murale) ;
- user : Temps total utilisé directement par le processus (en mode utilisateur) ;
- sys: temps total utilisé par le système pour le compte du processus (en mode noyau).
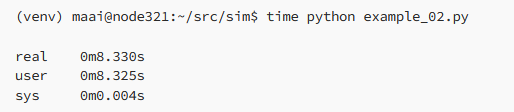
Pour notre propos, c'est le temps réel qui nous intéresse. L'exécution du programme a pris 8,33 secondes dans l'exemple ci-dessous :
Voici le code pour les plus curieux :
Code Python : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
Résultats du côte de Python 3.10, Python 3.11, Cython et C++
Résultats Python 3.10
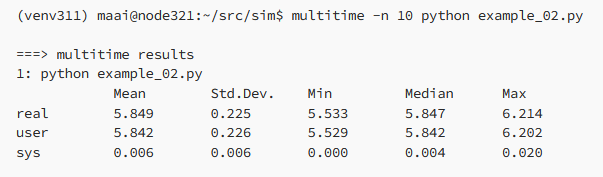
Jusqu'à présent, les tests ont été effectués avec Python 3.10. Ainsi, lorsque nous examinons la sortie de synchronisation ci-dessus, nous constatons que l'exécution de la simulation dans Python 3.10 a pris 9,5 secondes.
C'est la valeur de base pour une expérimentation ultérieure. C'est la valeur que nous voulons battre.
Une note sur l'ordinateur utilisé pour effectuer ces mesures. Il a une spécification raisonnablement normale qui devrait être représentative d'un système utilisé pour effectuer de petites simulations scientifiques.
- Processeur Intel Core i78700 à 3,20 GHz
- 6 curs de processeur
- 32 Go de RAM
Résultats Python 3.11
Il y avait beaucoup de bruit autour de la nouvelle version Python 3.11. On dit qu'elle est beaucoup plus rapide que les versions précédentes de Python. De nombreux articles confirment ce fait. La raison, cependant, est profondément enfouie dans les notes de version de la nouvelle version de Python :
Fort de cette information, Multi-Agent AI a exécuté à nouveau la même simulation, cette fois en utilisant Python 3.11. Et voici les résultats :L'idée générale est que bien que Python soit un langage dynamique, la plupart du code a des régions où les objets et les types changent rarement. Ce concept est connu sous le nom de stabilité de type.
Au moment de l'exécution, Python essaiera de rechercher des modèles communs et la stabilité du type dans le code d'exécution. Python remplacera alors l'opération en cours par une autre plus spécialisée. Cette opération spécialisée utilise des raccourcis disponibles uniquement pour les cas/types d'utilisation, qui surpassent généralement leurs homologues génériques.
Le résultat est plus impressionnant qu'avec la version précédente : 5,8 secondes, ce qui est beaucoup plus rapide que les 9,5 secondes mesurées auparavant. Les améliorations fonctionnent mieux si le programme passe la plupart du temps dans une fonction ou une boucle de base interne. Si vous le pouvez, utilisez la dernière version de Python, cela peut potentiellement vous faire gagner beaucoup de temps.
Les simulations typiques passent la plupart de leur temps à calculer la même formule mathématique encore et encore - c'est exactement là que cette spécialisation des opérations mentionnée ci-dessus est la plus importante.
Résultats Cython
Normalement, le code Python est interprété à chaque fois qu'une ligne est exécutée. Cython, cependant, compile une fonction en code machine rapide (via C, d'où son nom). Il utilise la même syntaxe de base que Python, est entièrement interopérable et ajoute quelques fonctionnalités de langage supplémentaires pour optimiser les performances.
Le langage Cython est un sur-ensemble du langage Python qui prend également en charge l'appel de fonctions C et la déclaration de types C sur des variables et des attributs de classe. Cela permet au compilateur de générer du code C très efficace à partir du code Cython. Le code C est généré une fois, puis compilé avec tous les principaux compilateurs C/C++.
Apprendre Cython n'est pas difficile, mais cela nécessite un peu d'effort supplémentaire par rapport à Python. C'est plus compliqué à écrire, et plus d'étapes sont nécessaires pour exécuter le code.
Il existe différentes techniques d'optimisation disponibles dans Cython. La plus simple, et probablement la plus efficace, est la déclaration des types de variables. Cette étape simple libère le programme de la vérification du type d'une variable à chaque étape (exactement ce qui rend Python 3.11 si rapide).
Code cython : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25cdef class Agent(): cdef readonly double x cdef readonly double y cdef double dx cdef double dy cdef Agent target # here: more definitions def __init__(self, x=None, y=None, world_width=0, world_height=0): # here: agent initialization cpdef void update(self, list food) except *: cdef double min_dist cdef double squared_dist cdef double fx cdef double fy self.age = self.age + 1 # here: agent position update logic
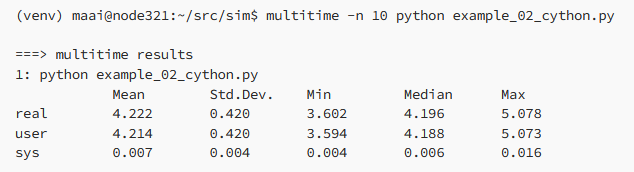
Cette nouvelle version de l'exemple de simulation s'exécute maintenant en 4,2 secondes. C'est deux fois plus rapide que le programme original, et toujours plus rapide que Python 3.11. La seule partie réécrite dans Cython était la classe Agent() comme indiqué ci-dessus. Le reste du programme a été laissé en Python normal.
Pour les plus curieux, voici le code :
Code Cython : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78""" python setup.py build_ext --inplace """ import random from datetime import datetime random.seed(datetime.now().timestamp()) WORLD_WIDTH = 2560 WORLD_HEIGHT = 1440 from agent import Agent class Predator(Agent): def __init__(self, x=None, y=None, world_width=0, world_height=0): super().__init__(world_width=world_width, world_height=world_height) self.vmax = 2.5 class Prey(Agent): def __init__(self, x=None, y=None, world_width=0, world_height=0): super().__init__(world_width=world_width, world_height=world_height) self.vmax = 2.0 class Plant(Agent): def __init__(self, x=None, y=None, world_width=0, world_height=0): super().__init__(world_width=world_width, world_height=world_height) self.vmax = 0 def main(): # open the ouput file f = open('output.csv', 'w') print(0, ',', 'Title', ',', 'Predator Prey Relationship / Example 02 / Cython', file=f) # create initial agents preys = [Prey(world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT) for i in range(10)] predators = [Predator(world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT) for i in range(10)] plants = [Plant(world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT) for i in range(100)] timestep = 0 while timestep < 10000: # update all agents #[f.update([]) for f in plants] # no need to update the plants; they do not move [a.update(plants) for a in preys] [a.update(preys) for a in predators] # handle eaten and create new plant plants = [p for p in plants if p.is_alive is True] plants = plants + [Plant(world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT) for i in range(2)] # handle eaten and create new preys preys = [p for p in preys if p.is_alive is True] for p in preys[:]: if p.energy > 5: p.energy = 0 preys.append(Prey(x = p.x + random.randint(-20, 20), y = p.y + random.randint(-20, 20), world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT)) # handle old and create new predators predators = [p for p in predators if p.age < 2000] for p in predators[:]: if p.energy > 10: p.energy = 0 predators.append(Predator(x = p.x + random.randint(-20, 20), y = p.y + random.randint(-20, 20), world_width=WORLD_WIDTH, world_height=WORLD_HEIGHT)) # write data to output file #[print(timestep, ',', 'Position', ',', 'Predator', ',', a.x, ',', a.y, file=f) for a in predators] #[print(timestep, ',', 'Position', ',', 'Prey', ',', a.x, ',', a.y, file=f) for a in preys] #[print(timestep, ',', 'Position', ',', 'Plant', ',', a.x, ',', a.y, file=f) for a in plants] timestep = timestep + 1 print(len(predators), len(preys), len(plants)) if __name__ == "__main__": main()
Résultat C++
Python est un langage interprété avec typage dynamique. Cela signifie que chaque ligne de code est interprétée pendant l'exécution du programme et traduite en code machine à la volée. Le type de variables n'est pas connu à l'avance et peut même changer.
Le C++, quant à lui, est compilé et utilise le typage statique. Cela a des avantages de vitesse. Le compilateur peut analyser l'ensemble du programme et optimiser le code machine à l'avance. Et il n'est pas nécessaire de vérifier le type des variables pendant l'exécution du programme.
Les deux langages sont des langages orientés objet, et la structure de notre programme est identique.
Code C++ : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Lorsque nous compilerons ceci, nous pourrions être surpris. Le temps d'exécution peut être assez lent, dans la région de la vitesse de Python. La raison en est que, par défaut, le compilateur laisse de nombreuses vérifications dans le code. C'est un peu comme Python alors et ralentit vraiment la simulation.
L'activation des indicateurs d'optimisation oblige le compilateur à tenter d'améliorer les performances et/ou la taille du code au détriment du temps de compilation et éventuellement de la possibilité de déboguer le programme. Le compilateur effectue une optimisation basée sur la connaissance qu'il a du programme.Si nous activons l'optimisation du temps de compilation à l'aide de l'indicateur -O3, le résultat est différent :g++ example_02.cpp -o example_02 -O3
La même simulation qu'avant s'exécute maintenant en 0,78 seconde, soit 10 fois plus rapidement que l'équivalent Python.
Voici le code pour les plus curieux :
Code C++ : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
Et Multi-Agent AI d'aller de ce commentaire :
ConclusionC++ est la norme de facto pour les simulations basées sur la physique. Pour de bonnes raisons; il est bien connu, capable de gérer des structures de données complexes et l'un des langages les plus rapides disponibles.
Il est environ 10 fois plus rapide que Python, selon la taille et la complexité de la simulation. Ces exemples de jouets prennent ici quelques secondes à s'exécuter, donc le gain de performances n'a pas vraiment d'importance. Pour des simulations à grande échelle, un gain de performances de cet ordre de grandeur est très important. C'est vraiment important si une simulation dure une journée ou une semaine.
Voici le résumé des résultats obtenus par langage :
Langage Temps (en secondes) Python 3.10 9,5 Python 3.11 5,8 Cython 4,2 C++ 0.78
Cette approche suggère que Python 3.11 peut être deux fois plus rapide que les anciennes versions de Python. Pourtant, il existe un écart important par rapport aux performances du C++ optimisé. Toutefois, il faut prendre ces résultats avec du recul, étant donné que cela dépend vraiment de vos besoins. D'ailleurs, Multi-Agent AI fait les recommandations suivantes aux professionnels dans le domaine des data science :
- Si vous voulez un prototype de simulation, faites-le en Python. Il est propre et facile à lire à la fois par les développeurs et les personnes connaissant le domaine.
- S'il y a une partie qui est au cur de la simulation, envisagez de la réécrire dans Cython. Surtout si elle est utilisée par d'autres personnes comme module stable.
- Si vous construisez une simulation à grande échelle ou travaillez sur un projet de plus longue durée, divisez la simulation en parties significatives, comme la simulation, la journalisation, la visualisation et l'analyse des données.
- Ensuite, réécrivez la simulation réelle en C++, par exemple. Pour les autres parties, utilisez les langages qui conviennent le mieux*; comme Python pour l'analyse des données.
- Pour obtenir les meilleures performances, utilisez toutes les techniques ensemble. Une simulation vectorisée en C++ s'exécutant sur plusieurs processeurs est la plus rapide. De plus, c'est le plus difficile à programmer et à maintenir.
Source : Muti-Agent AI
Et vous ?
Lequel de ces langages utilisez-vous ?

 Répondre avec citation
Répondre avec citation































Partager