













Bonjour,
mon problème vient de la conceptualisation de la représentation des données en mémoire.
En partant du principe que la mémoire est un ruban de longueur pseudo-infini, je vois deux manières de représenter le code suivant.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
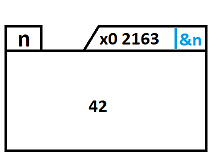
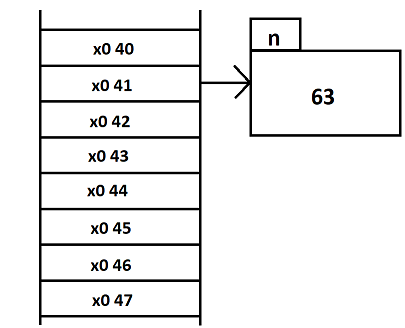
creation d'une zone memoire (n) pour contenir un int
initialisation de n avec la valeur 42
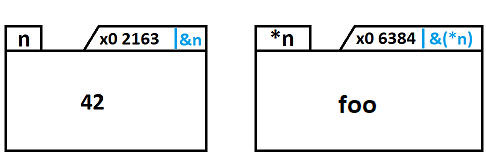
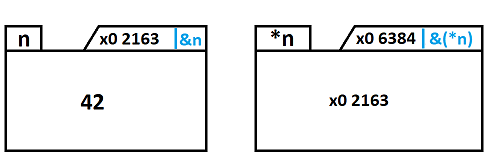
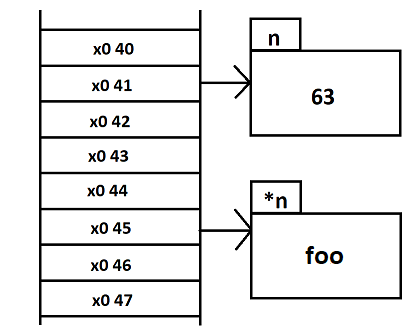
creation d'un pointeur (p) sur int
initialisation de p avec l'adresse de n
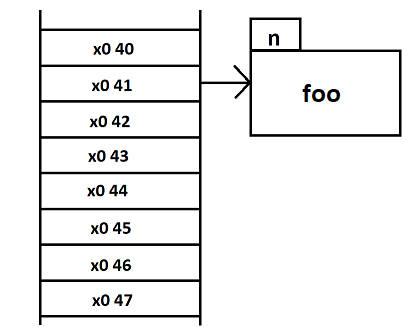
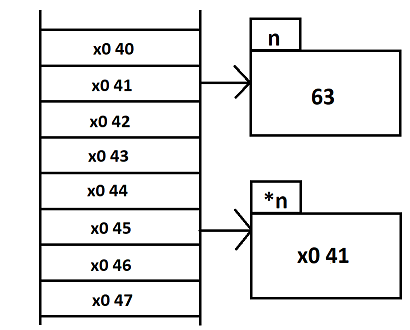
Ou bien de se dire que la mémoire (le ruban) est divisée en une unité atomique (l'octet) et crée un tableau référençant toutes ces cases. C'est-à-dire un tableau contenant les pointeurs de chaque case mémoire. Et à chaque création de zone mémoire, l'adresse de début de cette zone mémoire pointe vers celle-ci.
création d'une zone mémoire (n) pour contenir un int puis initialisation de n avec la valeur 42. Création d'un pointeur (p) sur int
initialisation de p avec l'adresse de n
cette différence de vue, implique la création d'un tableau et éventuellement de drapeaux dans les cases de ce tableau pour indiquer que les cases sont occupées. Il y a là une dissociation entre les données et leur référencement un peu comme dans le cas des disques durs avec les clusters et la table d'allocation du système de fichiers.
Si quelqu'un pouvait me faire savoir qu'elle est la bonne manière de voir, d'avance merci à lui/elle.
PS:Je me rend compte que cette question a largement dérivé vers une question de système informatique/système d'exploitation.

 Répondre avec citation
Répondre avec citation
Partager