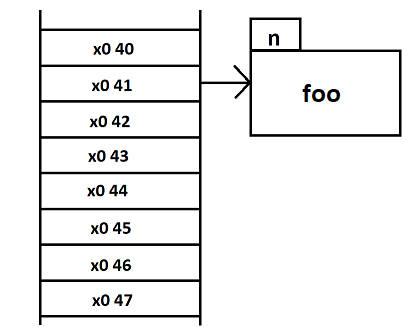
De la réponse de foetus si ce n'est pas sous forme tabulaire serait-ce donc que la case mémoire porte l'ensemble des informations.
maintenant que le choix est arrêté me viens une question à propos de la cohérence (c'est peut-être cette question que je n'arrivais pas à formuler).
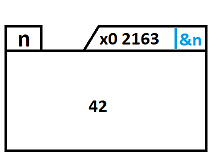
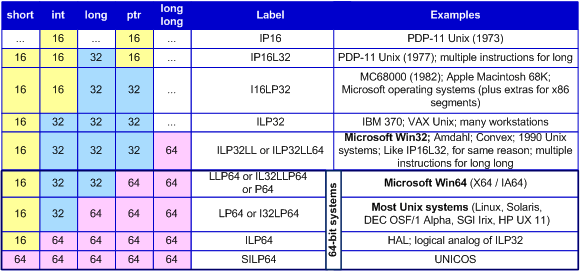
Dans le cas d'un float (4 octets, 32 bits) repartie sur 4 cases mémoire, si c'est la 1er case mémoire qui "porte" le type, un float n'aurait que 2^31 bits de valeurs.
Or dans la littérature les floats ont 2^32 valeurs.
Mais où est donc écrit l'information à propos du type contenu dans chaque case/ensemble de cases.
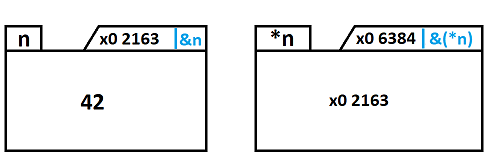
même question pour l'adresse, si elle est "porter" par la case mémoire cette valeur empiète sur la plage de valeur possible du float.
Une possibilité aurai été, une case mémoire est constituée d'une "pre-case" de taille fixe, contenant le type. Cela me parait peu probable vu la perte de place occasionner.
dans le cas d'un float:

Car ces choix/concepts, en tant qu'utilisateur ne me sont pas connus.
D'ailleurs quelqu'un sait-il ou trouver ces informations, si toutefois elles sont disponibles?
PS: sur
wikipedia les valeurs signées ont toutes pour plages [-a ; a]. C'est moi qui me trompe où il manque la place pour ce pauvre zéro ?
PSS: je n'ai pas compris l'explication de foetus.
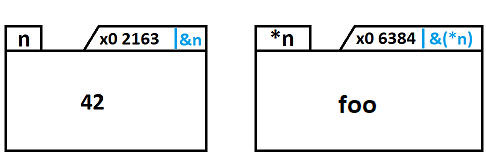
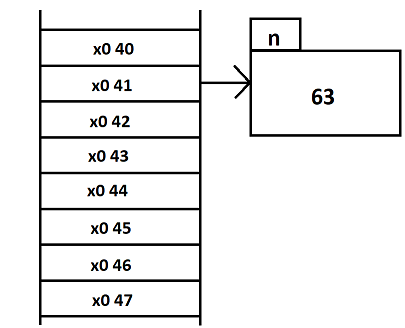
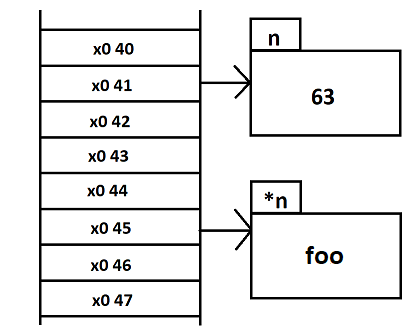
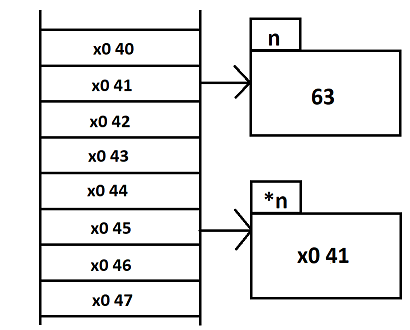
pour moi "foo" signifier la valeur aléatoire contenu, j'aurai du mettre rand.











 Répondre avec citation
Répondre avec citation








 je pensais que
je pensais que









 Consultez nos FAQ :
Consultez nos FAQ : 

Partager