Membre émérite



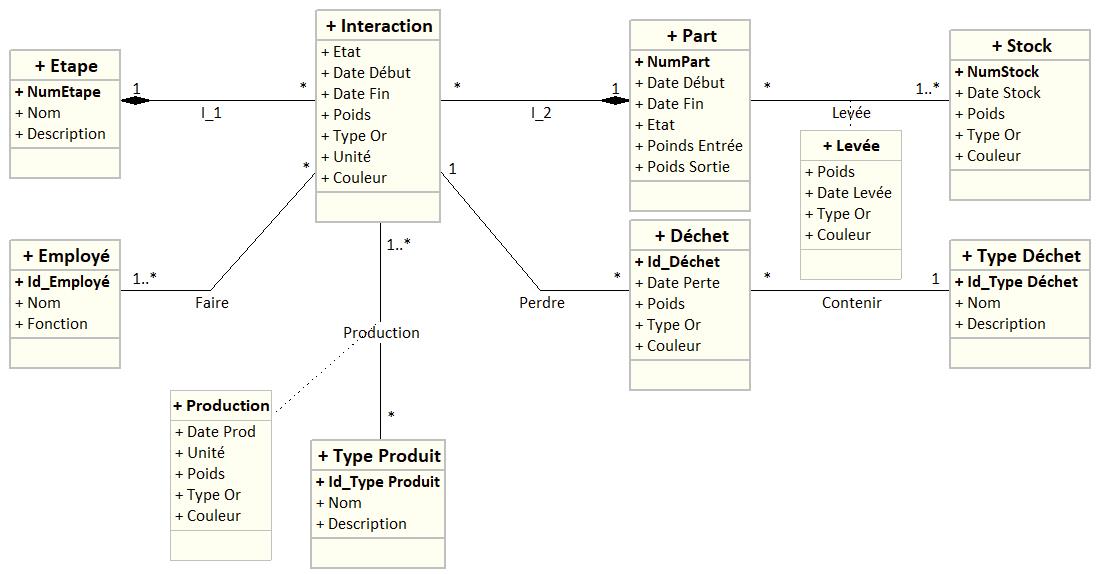
Afin d'illustrer mon propos, j'ai repris votre diagramme de classes et je l'ai modélisé rapidement avec Looping.
J'ai fait une transformation sans aucune vérification de fond du MCD... qui, à mon avis, méritera d'être revu, surtout quand on voit le schéma relationnel que vous avez proposé ensuite

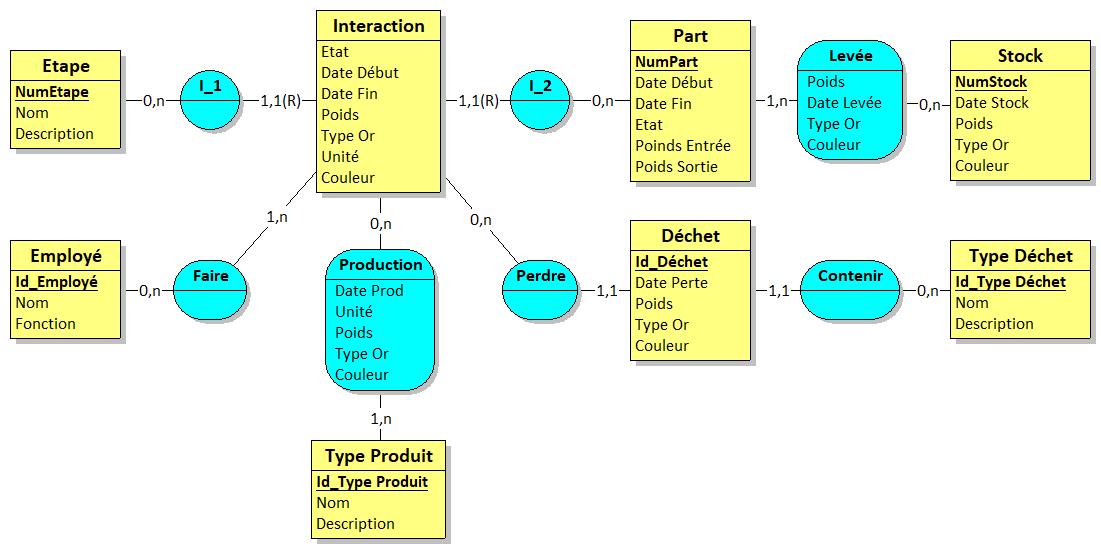
A suivre
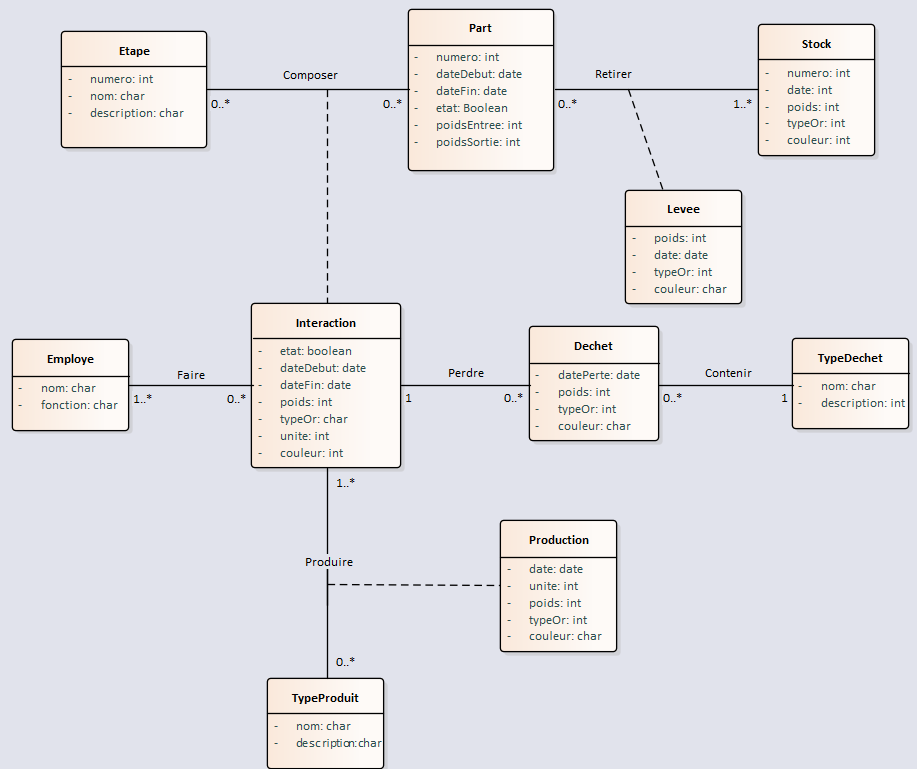
Membre émérite
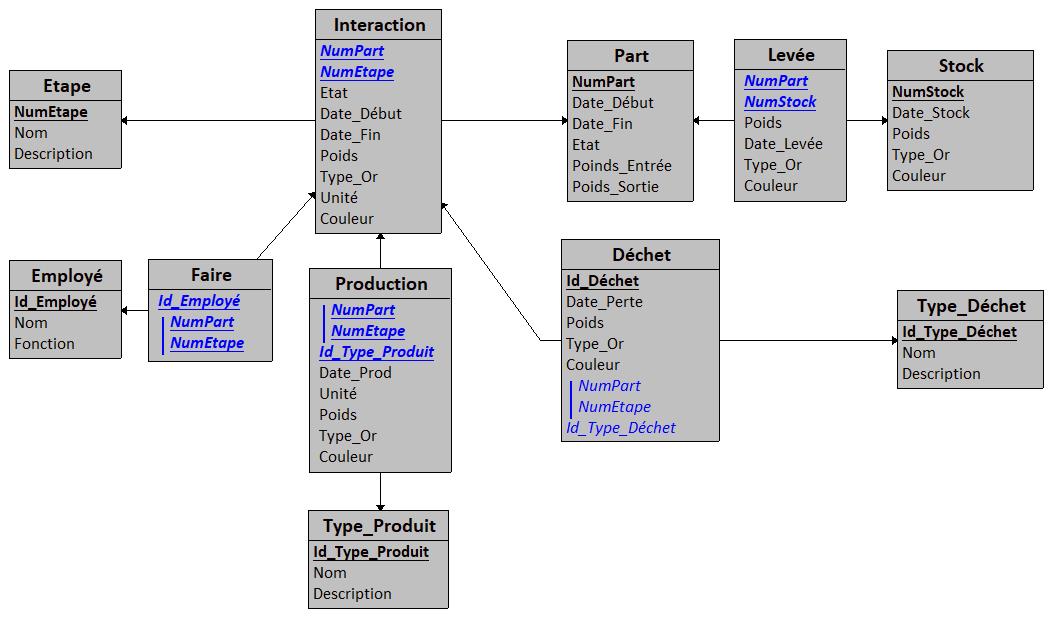
Et voilà ce que ça donne transformé en diagramme de classe UML par Looping :
Futur Membre du Club

Discussion très intéressante. Encore étudiant, j'ai commencé avec Merise et un bon prof. J'ai pleuré du sang mais pour ce qui est de la gestion de bases de données, MCD, MLD, MPD, tout était très clair.
Puis on est passé à un autre prof et UML (soi-disant plus moderne que Merise). J'ai repleuré du sang mais j'arrive à générer un MPD à partir d'un diagramme de classe. En revanche, quid de l'utilisation des méthodes au sein dudit diagramme...
Cela semble ne servir qu'à conceptualiser. Powerdesigner propose bien de générer un projet J2EE mais on est quand même à l'heure de Spring boot depuis quelques années donc autant dire qu'à part bien préparer ses petites méthodes, niveau implémentation ça ne sert à rien.
Petite question subsidiaire à Paprick: tu associes la classe production. Quand je fais ça, moi ça me reparti le contenu de la classe d'association dans les 2 autres classes et ça me donne un résultat très "bordélique". Du coup, j'ai tendance à contourner le problème via une généralisation... as-tu le même genre de résultat?
Membre émérite
Bonsoir,

Envoyé par
MrTypiac

Petite question subsidiaire à Paprick: tu associes la classe production. Quand je fais ça, moi ça me reparti le contenu de la classe d'association dans les 2 autres classes et ça me donne un résultat très "bordélique". Du coup, j'ai tendance à contourner le problème via une généralisation... as-tu le même genre de résultat?
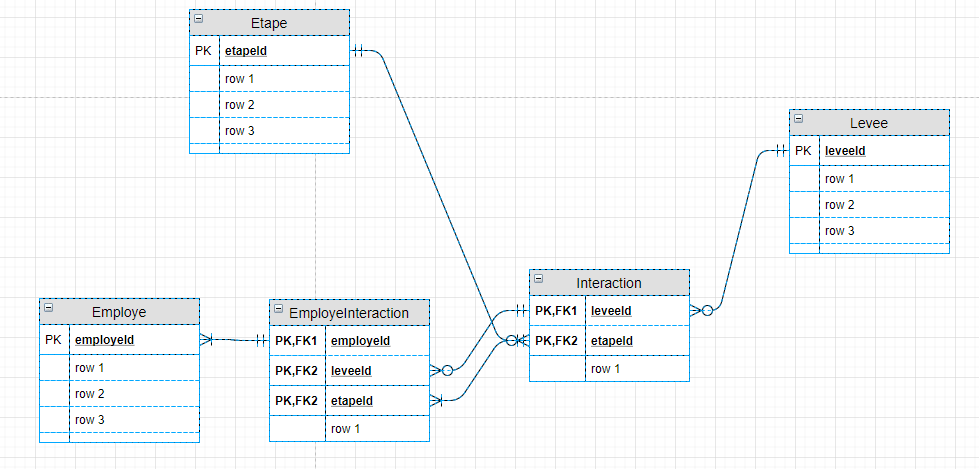
Lorsqu'une association a des cardinalités multiples de part et d'autre comme c'est le cas de "Production", la génération du MLD doit provoquer la création d'une table d'association distincte, et surement pas une "répartition" de son contenu dans les classes associées ! 
Je ne sais pas quel logiciel vous génère ce genre de résultat, mais il y a comme un problème... 
Dans l'exemple ci-dessus, voici le MLD qui doit être généré :
Futur Membre du Club
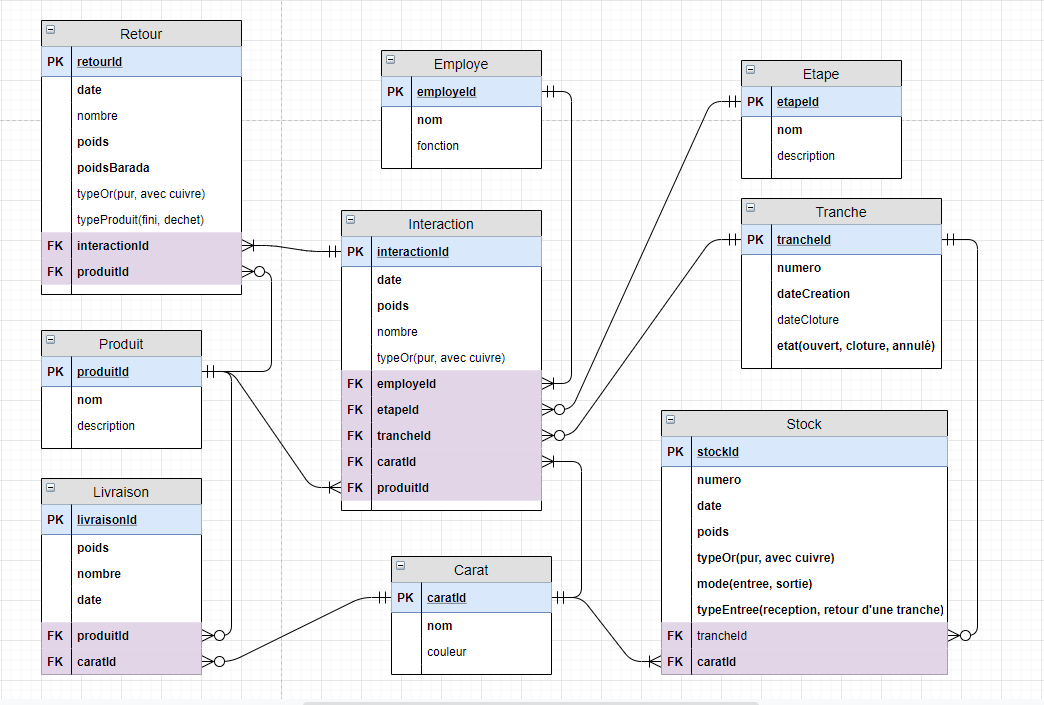
Effectivement, je n'ai pas du tout le même résultat. J'utilise pourtant power designer... Etant donné que j'ai contourné le problème avec une généralisation, je n'ai plus l'exemple mais je vais en refaire un parce qu'effectivement, il m'est arrivé d'avoir deux résultats différents avec 2 associations qui étaient pourtant dans le même cas de figure avec exactement les même cardinalités où j'avais les deux résultats suivants:
- la classe associée devient une classe distincte (mais également ad hoc des deux autres classes)
- les attributs de la classe associées se retrouvent dans les deux classes "mère".
Je vais poster un exemple.
Modérateur


Bonjour,
Je rejoins Cinephil et Paprick quant à la préférence d'un modèle entité-association plutôt qu'un modèle UML.
Cela étant dit
Envoyé par
MrTypiac
la classe associée devient une classe distincte (mais également ad hoc des deux autres classes)
jusqu'ici tout va bien.
Envoyé par
MrTypiac
les attributs de la classe associées se retrouvent dans les deux classes "mère".
Là par contre, je ne pense pas que ce soit power-AMC qui ait produit cette aberration  ...
...
J'ai utilisé par le passé power-AMC sans jamais obtenir (fort heureusement) ce type de résultats.
Discussions similaires
-
Réponses: 1
Dernier message: 09/04/2013, 16h53
-
Réponses: 8
Dernier message: 04/12/2010, 21h51
-
Réponses: 1
Dernier message: 01/04/2010, 17h00
-
Réponses: 3
Dernier message: 03/06/2009, 12h19
-
Réponses: 2
Dernier message: 09/04/2009, 15h56



×
Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité,
merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.










 Répondre avec citation
Répondre avec citation











Partager