










Bonjour à tous,
Je dois faire l'update d'une table et j'ai quelques soucis de performance, cela fait déja 8h que mon script tourne et c'est toujours pas fini.
Pour info:
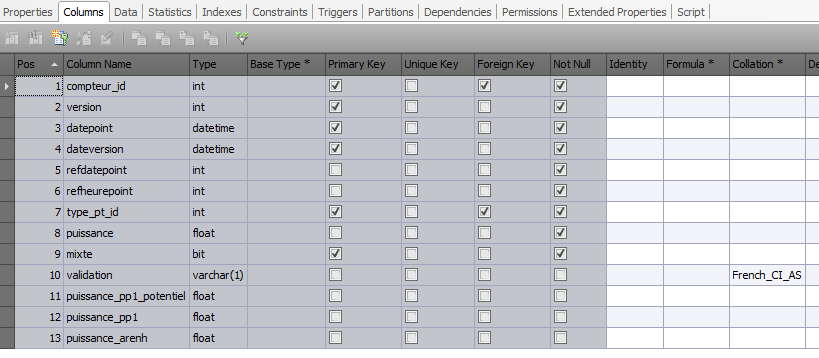
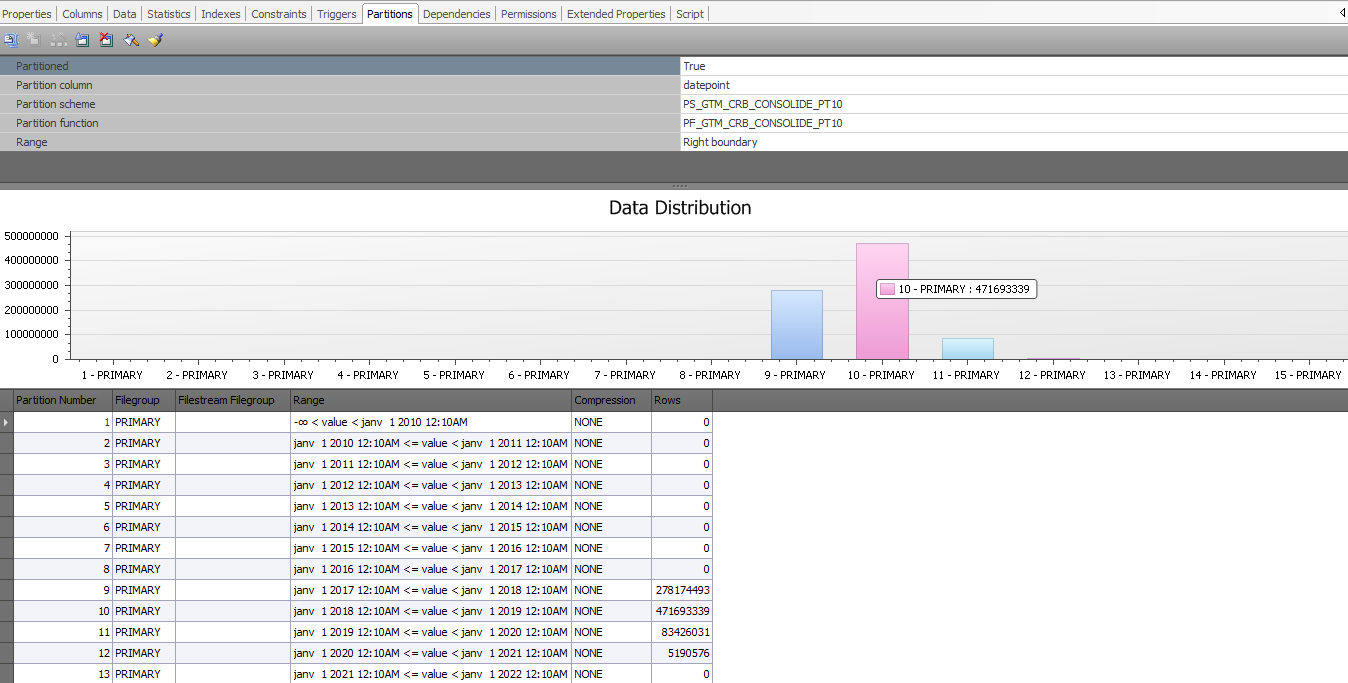
- La table contient plusieurs dizaines de millions de données, partitionnée avec une notion de date.
- Mon update est bien structuré avec une clause Where. C'est un update, tout ce qu'il y a de plus basique.
- La table est convenablement indexée et ne possède aucun trigger.
- Par contre sur ma table, j'ai une douzaine de vue qui pointent dessus.
Questions:
- J'ai lu dans certains forums, qu'il faudrait désactiver les index, et ensuite les reconstruire. Qu'en pensez vous ? Est ce que je vais vraiment gagner en temps ?
- Est ce qu'il faut que je dissocie mes vues et le recrée après mon update ?
Merci pour vos avis.
 Répondre avec citation
Répondre avec citation













Partager