























OpenMP 5.0 est prévu pour novembre 2018,
avec l'ajout d'interfaces pour le débogage et l'analyse poussée de la performance
OpenMP est la norme actuelle pour la programmation parallèle à mémoire partagée, cest-à-dire sur les différents curs dune même machine. Ce genre de technologie permet de tirer parti des machines actuelles, dont le nombre de curs ne cesse daugmenter, même si OpenMP a dabord été développé pour exploiter les supercalculateurs. La version 4.5 de la norme a étendu les possibilités vers un déchargement de lexécution du code sur un accélérateur, comme un processeur graphique, disponible dans la machine.
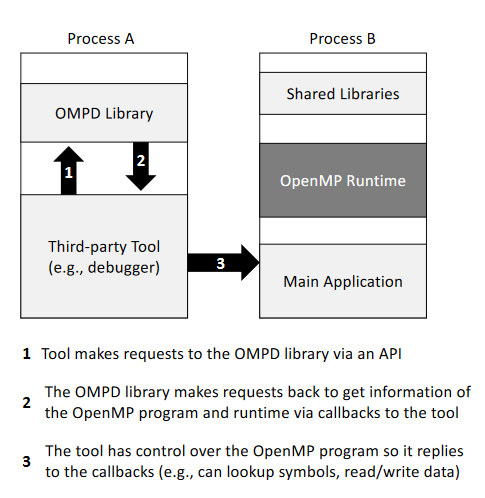
La version 5.0 est annoncée pour la fin de lannée et un nouveau brouillon public est disponible (TR7). Elle apporte bon nombre de nouveautés, comme deux nouvelles interfaces pour la définition doutils : OMPT pour ceux fournis par limplémentation dOpenMP, OMPD pour les outils tiers. Ces outils sont prévus pour inspecter létat dOpenMP pendant lexécution : quand lobjectif dOMPT est de faciliter lanalyse poussée de la performance du code OpenMP (pourquoi un cur doit-il attendre ?), celui dOMPD est plutôt orienté vers le débogage dapplications (pour afficher plus précisément la pile au niveau dun point darrêt, par exemple).
OpenMP 5.0 se focalise aussi sur les accélérateurs. Notamment, la norme introduit des constructions pour gérer les systèmes qui disposent de plusieurs niveaux de mémoire, sous la forme despaces de mémoire différents. La clause map sert à transférer les données entre les banques de mémoire. Également, la synchronisation a été revue afin de gérer plus de mécanismes pour acquérir et libérer les droits décriture.
Toujours au niveau de la mémoire, la programmation orientée objet est mieux gérée, grâce à la directive declare mapper : elle sert à déclarer la manière de transférer les données dune structure complexe, cest-à-dire dun objet, par exemple vers un accélérateur.
La clause depend gère des dépendances entre tâches plus précises : outre les types entrée-sortie, lexclusion mutuelle et des dépendances dynamiques ont été ajoutées.
Sources : Technical Report 6 is a preview of OpenMP 5.0, expected in November 2018, OpenMP ARB Releases Technical Report with Support for a Tool Interface, OMPT and OMPD: Emerging Tool Interfaces for OpenMP.
Et vous ?
Qu'en pensez-vous ?
Voir aussi
 Répondre avec citation
Répondre avec citation
Partager