

C'est pas possible !!!
Le temps de prendre un café tu dis ???
Bon, je vais me retirer sur la pointe des pieds...
Et appliquer vos très bons conseils.
En vous remerciant chaleureusement.
À plus, sans doute sur un autre forum.
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter

 Discussion :
Discussion :
 [Lazarus]
[Lazarus]





C'est pas possible !!!
Le temps de prendre un café tu dis ???
Bon, je vais me retirer sur la pointe des pieds...
Et appliquer vos très bons conseils.
En vous remerciant chaleureusement.
À plus, sans doute sur un autre forum.





Yop !
C'est qui, celui-ci ?Envoyé par mm_71

Ah, Charset tu veux dire !





Salut, Yves,
Oh, je crois que tu peux enlever ton point d'interrogation, ça doit surement être ça, quand on suit ton lien, c'est clair.
Mais comment l'as-tu trouvé ? Ou tu le connaissais déjà ?
Ben j'aurais encore appris un truc, aujourd'hui
Moi qui pensais que mm_71 nous avait concocté un ch'tit prog pour récupérer ces infos, voilà qu'il va falloir se mettre au python,
Bonsoir,
Je ne pensais pas revenir aussi vite.
Après avoir ouvert ton exemple dans lequel toutes les lettres accentuées étaient bien là...
J'ai sauvegardé, puis réouvert => Surprise ! Les lettres accentuées étaient remplacées par des "À@"...
Qu'en pensez-vous ? J'ai essayé de sauvegarder en modifiant sans effet.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Cordialement.





Bonsoir c'est possible que ce soit 1254 je suis partie du principe Delphi 3 --> Windows et 1252 est le code page de Windows en générale de plus dans ce mode les caractères accentués sont souvent convertit en "?" lors d'un affichage en UTF-8
C'était un grand café ! Dis-moi !
Chardet ! ca à l'air sympa juste dommage que ce soit en Python et qu'il faut installer tout le tointoin pour le faire fonctionner sous Windows
Bonne soirée
Bonsoir
Comment as tu sauvegardé ?depuis le StringGrid.SaveToFile ou comme le code ta procedure "Enregister" que tu nous avait fourni ?Oups j'ai lu trop vite !
Je mange et je je jette un oeil vite fait
A toute
Re
J'ai fini de manger et je viens de regarder. Tu n'as pas suivis mes recommandations avec le With...do! attention
Tiens voila l'exemple modifié, pour enregistrer tes données en UTF-8 correctement et les charger
memorep2.zip
Bonne soirée

Oui, mais faut le temps qu'il passe, en plus j'ai l'habitude de mettre en signets les messages ou je peux répondre et je fais tout en une fois sans regarder trop si il s'est passé quelque chose entre temps.C'était un grand café ! Dis-moi !
Sous linux c'est natif, il n'y a pas d'équivalent sous windows ? Et dans Lazarus il n'y a pas une fonction qui permet de faire ça ?Chardet ! ca à l'air sympa juste dommage que ce soit en Python et qu'il faut installer tout le tointoin pour le faire fonctionner sous Windows
Es-tu certain que ton système est bien en UTF-8 et pas en ISO-quelque chose ?J'ai sauvegardé, puis réouvert => Surprise ! Les lettres accentuées étaient remplacées par des "À@"
Oups !
Je me disais bien que de recharger avec le même code n'était pas correct. Mais pris par le temps
et la nécessité de faire autre chose...
En ce qui concerne les boucles, et with ... do je vais faire attention...
Pour la sauvegarde du fichier,
La formulation : Identite := StringGrid1.Cells[0,Ligne];
a l'air plus explicite que : Identite := strings[0];
Mais je ne comprends pas pourquoi.
Cordialement.
Il doit sûrement y avoir un truc dans le genre sous Windows mais je n'en connais pas. Pour Lazarus j'ai une fonction dans le genre que j'ai tirée de je ne sais plus où. Mais elle n'est pas aussi avancée que Chardet.
Vu que Chardet est en Python, faire une conversion en Pascal ne devrait pas être trop compliqué à mon avis.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
Il faudrait trouver la liste de tous les BOM's possibles mais là où il y-a un os c'est que si je regarde mes fichiers texte en UTF-8 ils n'ont pas de BOM ou ghex les zappe ?Pour Lazarus j'ai une fonction dans le genre que j'ai tiré de je ne sais plus ou. Mais elle n'ai pas aussi avancé que Chardet
Pour ceux qui se demandent ce qu'est un BOM: il y a au début du fichier texte un BOM (byte order mark) de 2 ou 3 octets.
Pour les BOM il n'y a pas 36000 possibilités. Je viens de regarder vite fait le code de chardet, ce n'est pas trop compliqué mis à part que c'est très éclaté.
Sinon je viens de me souvenir d'un truc que j'avais vu sur le wiki et que j'ai retrouvé (http://wiki.lazarus.freepascal.org/UTF8_Tools). Cette bibliothèque peut-être utile pour la manipulation de caractères ANSI, UTF-8, 16, 32 avec et sans BOM en little et big endian.
En principe la formulation n'est pas en cause, c'est surtout le With..do la cause, mais je vérifierais.
Par exemple dans ton code
Ce n'est pas correct, car la première entité est le stringgrid et non personne. Normalement tu devrais faire
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Mais comme je te l'ai dit cette notation avec le with..do est à proscrire, elle peut induire en erreur, et induire le compilateur en l'erreur. Mieux vaut être plus explicite, c'est plus sûr.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Sinon avec le StringGrid sous Lazarus arf, il faut souvent ruser comparé à Delphi. Mieux vaut rester le plus basique possible.
Bonne fin de soirée et n'hésite pas si tu as d'autres soucis.")
Non, ghex ne zappe rien du tout (et puis quoi encore ? Si les afficheurs hexa décident de ce genre de choses, ça va être le monde à l'envers).
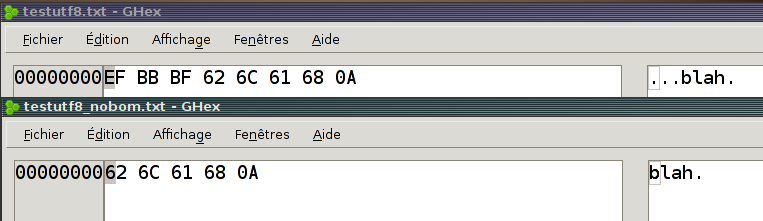
Cool, geany a une option "Ecrire le BOM Unicode" dans son menu "Document", et selon que c'est coché ou pas, ça donne ça :
Et ouvrir ces deux fichiers avec leafpad affiche la même chose : blah
mais "clic droit / propriétés" montre bien que l'un pèse 5 octets (b 1 l 2 a 3 h 4 <ENTREE> 5) quand l'autre monte à 8.
J'ai fouillé un peu plus et j'ai vu que les systèmes Unix/Linux n'écrivaient jamais le BOM dans les fichiers texte.Non, ghex ne zappe rien du tout (et puis quoi encore ? Si les afficheurs hexa décident de ce genre de choses, ça va être le monde à l'envers).
???????????????????????
Et c'est quoi, alors, les 3 octets EF BB BF de ma copie d'écran ?
Il m'a suffi de le demander gentiment à geany et hop !

Bonjour,
UTF8 a été créé pour pouvoir traiter des fichiers en ASCII pur (caractères de 0 à 127) sans les transcoder donc sans BOM (parce que sinon ce n'est pas de l'ASCII)
Cependant on peut y en placer un celui ci est la traduction en UTF8 des BOMs utilisés en UTF16 ce qui permet de traduire directement de UTF16 en UTF8 mais de mon point de vue celui ci n'est pas vraiment utile car il n'y a pas de notion de BOM (Byte order mark) ce qui n'empêche pas la plupart des traitements de texte de pouvoir les y ajouter si besoin
Cordialement
Oui, parce-que tu l'as demandé mais par défaut c'est toujours sans. Si il s'agit de savoir si un fichier est bien en UTF-8 dans un programme de détection de l'encodage tu ne peux donc pas t'en remettre au BOM.Et c'est quoi, alors, les 3 octets EF BB BF de ma copie d'écran ?
Il m'a suffi de le demander gentiment à geany et hop !
Il faudra faire la recherche sur les caractères spéciaux ( Les accentués 2 octets dont le premier est C3, les apostrophes et autre 3 octets dont le premier et E0 etc. )




Sinon il y a Charset Detector.
J'avais proposé il y a quelque temps un projet utilisant cette bibliothèque.

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.
 Répondre avec citation
Répondre avec citation



Partager