



















Microsoft serait en train de réécrire certains de ses outils et logiciels en JavaScript :
Office 365, Teams, Skype, VS Code et probablement d'autres
Quel est l'intérêt d'écrire ou réécrire un logiciel en JavaScript ? Voici une question qui a récemment fait couler beaucoup d'encre dans une discussion sur Developpez.com. Si certains considèrent JavaScript comme un cancer qu'il faut éradiquer, pour d'autres c'est plutôt LE langage de demain.
Cette dernière position peut s'expliquer en partie par le fait que le destin des langages de programmation est lié à leur écosystème et JavaScript bénéficie d'un vaste écosystème. D'abord, les navigateurs Web qui ne jurent que par JavaScript sont des plateformes largement déployées. Mais en plus, des plateformes comme Node et Electron - qui reposent sur JavaScript - sont très largement répandues. Ce qui fait qu'avec JavaScript, vous pouvez facilement cibler certains frontends et backends avec le même code. JavaScript aurait également d'autres avantages à en croire le témoignage de mister3957 :
Ces avantages semblent l'emporter sur le fait que l'écosystème JS évolue très vite ; ce qui nécessite une veille constante et de s'adapter pour ne pas se retrouver rapidement avec du code périmé.Après avoir refait pas mal de services jusqu'alors écrits en C++ pour les passer en JS, j'y ai vu pas mal d'intérêts :
- Plus facile à maintenir
- Les artefacts sont plus rapides à construire (donc time to market plus intéressant)
- Plus facile à déboguer
- Courbe d'apprentissage largement réduite
- Portabilité (sauf dans de rares cas, quand ça utilise des modules natifs spécifiques)
- Ecosystem riche et ouvert
- Compétences accessibles sur le marché
- Asynchrone
Il y en a juste un qui est resté en C++ car demandant pas mal de puissance et de maîtrise entre la mémoire et le CPU, mais consommé au travers de JS.
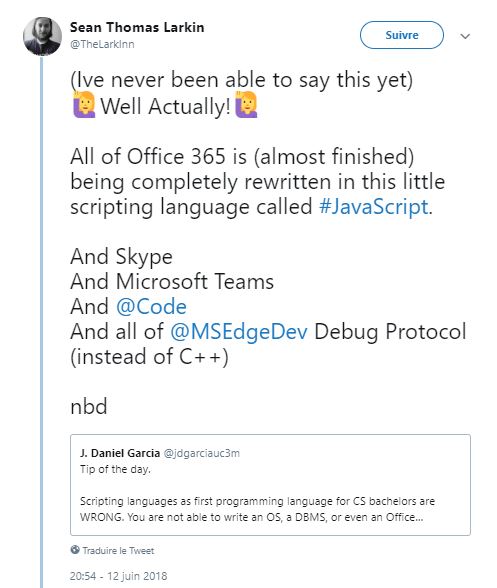
On peut dire aujourd'hui que JavaScript a aussi de grands fans parmi les géants de la technologie, y compris Microsoft, comme le laisse deviner le titre de cette actualité : Microsoft serait en train de réécrire bon nombre de ses outils et logiciels en JavaScript. L'information provient de Sean Thomas Larkin, Technical Program Manager pour la plateforme Web de Microsoft.
« Je n'ai jamais été capable de le dire jusqu'à maintenant. Eh bien, en fait, tout Office 365 est en train d'être complètement réécrit (et c'est presque terminé) dans ce petit langage de script appelé #JavaScript », a-t-il dit dans un message publié il y a quelques heures sur Twitter. Avant de compléter la liste des outils et logiciels de Microsoft qui sont également en train d'être réécrits en JavaScript : « Et Skype, et Microsoft Teams, et Visual Studio Code, et tout le protocole de débogage de Microsoft Edge (au lieu de C ++) », a-t-il ajouté.
Rappelons également que Microsoft a récemment ajouté à Excel la possibilité d'écrire des fonctions personnalisées en JavaScript, ce qui laisse croire que Microsoft a une politique de plus en plus orientée vers JavaScript. Mais quel est le but ?
Source : Sean Thomas Larkin (via Twitter)
Et vous ?
Que pensez-vous de la réécriture des outils et logiciels de Microsoft en JavaScript ?
 Répondre avec citation
Répondre avec citation






















 Mon grand il est temps d'ouvrir la documentation de Javascript ! C'est un langage orienté objet à base de prototypes et non de classes, tu ne dois sans doute pas savoir ce que ça veut dire mais bon je te laisse aller voir par toi même
Mon grand il est temps d'ouvrir la documentation de Javascript ! C'est un langage orienté objet à base de prototypes et non de classes, tu ne dois sans doute pas savoir ce que ça veut dire mais bon je te laisse aller voir par toi même 
Partager