










Salut,
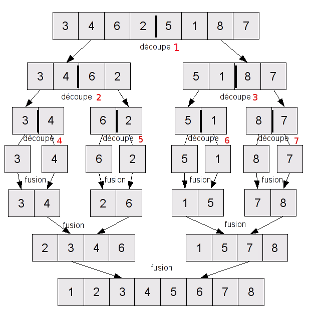
Je ne comprend pas pourquoi la partie découpage(uniquement) dans le tri de fusion a une complexité O(log(n)) et non pas O(n),
par exemple si on veut trié un tableau de n=8 alors on doit faire 7 opérations de découpage :
pour trié un tableau de 100 éléments on doit faire 100 opérations,ce qui doit normalement correspondre a O(n) non?
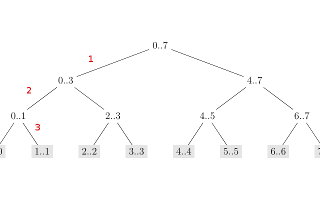
dans le cas de l'algorithme de dichotomie on a aussi une complexité log(n) ce qui est compréhensible car pour trouvé un élément dans une liste trié on effectue k opérations avec n=2^k
par exemple pour n=8 on peut trouvé lélément dans max 3 opérations,par exemple trouvé la valeur 1 :
pour un n=100 on effectue 6 opérations
-alors voila pourquoi les 2 algorithmes on la mème complexité log(n) alors que dans le cas de l'algorithme de dichotomie on effectue uniquement k opérations pour trouvé lélément alors que dans le cas du découpage du tri de fusion on effectue 2^k opérations?
Toute aide est la bienvenu,Merci
 Répondre avec citation
Répondre avec citation
















Partager