








Bonjour,
J'ai un problème qui, je pense, n'est pas simple du tout... il y a déjà plusieurs manieres de le resoudre et je n'ai surement pas pensé à chacune.
C'est un script en Perl.
Voici ce que je souhaite:
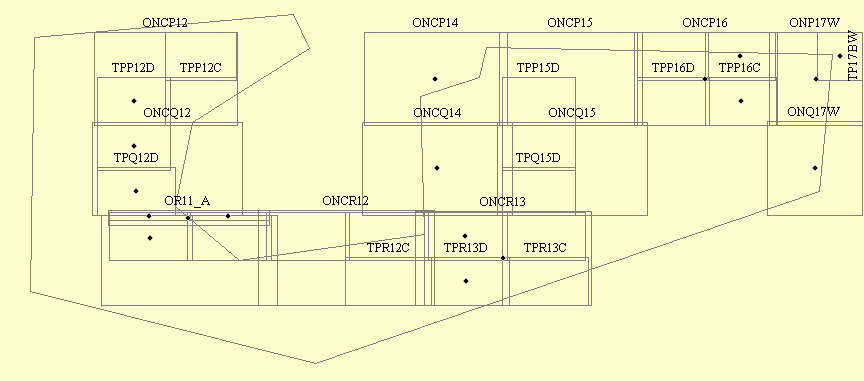
J'ai une série (non finie) de rectangles représentant des images (des cartes!). Les rectangles sont localisés avec des coordonnées X;Y (à chaque coin).
Je connais la taille (en Mo) de chaque carte.
Le but est de préparer intelligemment une compilation sur un support tel qu'un CD ou un DVD, à savoir regrouper au mieux les cartes de façon homogène (quant à leur localisation).
1/ Idée1: Pour chaque nouveau CD, partir d'une carte, chercher les cartes les plus proches, autour, et continuer jusqu'à atteindre la limite du CD, puis prendre une autre carte et refaire la même chose. Le problème: à mon avis l'algo ne pourra pas être des plus rapides et j'aboutirai, à la fin, à ramasser des miettes (des cartes éparpillées).
2/ I2: Considérer chaque rectangle comme un point (le centre), et partir de bas en haut et de gauche à droite (on croit en Y et en X). Je vois à peu près comment faire l'algo de façon pas trop lente, je pense, mais je n'aurai pas un beau résultat car jamais les points ne seront nettement alignés (sur l'axe principal des Y) et donc des cartes proches entre elles, mais dont les points centraux ne sont pas colinéaires, risquent fort de ne pas se retrouver sur le meme CD. Je risque d'avoir un carte au Sud, un gros trou, une au nord, puis sur un nouveau CD une carte plus nord que la toute première mais tout de meme tres proche en X....
==> La capacité à optimiser le stockage sur CD est importante car c'est très souvent des Go de fichiers à organiser (fichiers allant de 20 à 120Mo en general).
Bref, je ne sais pas si je suis clair (j'essaie)... si mon prob vous intéresse, si vous avez des conseils, des idées, des questions, je suis preneur.
Bonne journée.
 Répondre avec citation
Répondre avec citation




Partager