







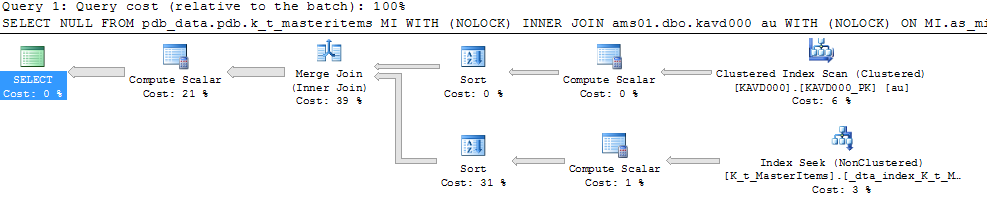
Lorsque j'exécute un Query "SELECT NULL...MyQuery...", le résultat est instantané. (0 seconde!)
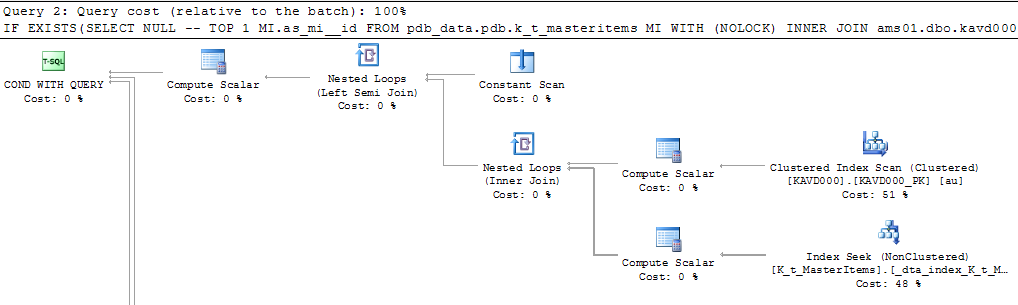
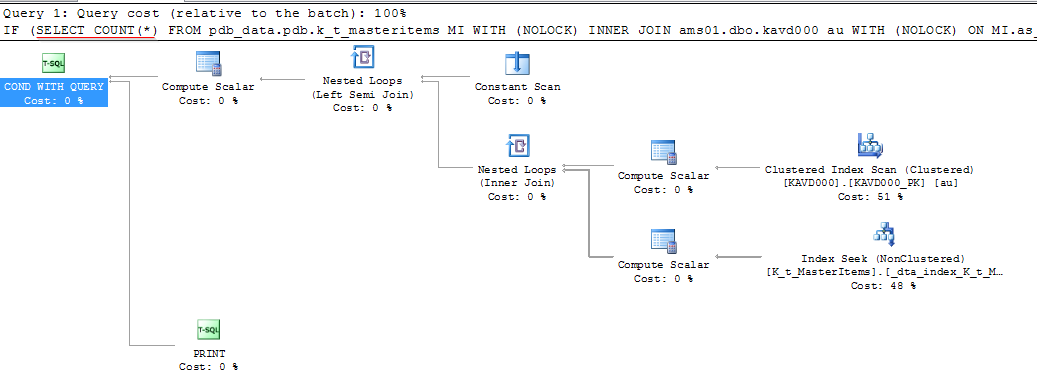
Lorsque j'exécute ce même Query dans un IF (EXISTS ou COUNT > 0...), l'exécution prend plusieurs minutes.
Mon Query travaille sur deux tables se trouvant sur deux bases de données différentes (même instance; lecture en "WITH (NOLOCK)")
Je ne comprends pas pourquoi il y a une telle différence... ou plutôt pourquoi il y a une différence d'intérprétation.
Merci d'avance pour votre avis sur la question
Détails SQL:
=> 220 ms
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
=> 4minutes 30s!!!
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
=> 4minutes 36s!!!
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
=>406 ms
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
Execution plan Part 0 & Part 1:
 Répondre avec citation
Répondre avec citation















Partager