






Je me suis mis en tête de programmer un réseau de neurones (sous Procesing.org). J'ai envie de me mettre à l'IA et je pense donc que c'est un passage obligé. J'étais plein de théories dans ma tête et le fait de réaliser l'existence de ces neurones formels me montrent deux choses :
-Mes théories se vérifient
-La compréhension que l'on a du fonctionnement du cerveau est bien plus avancée que je ne le pensais (tellement d'ailleurs, que je me demande si la l'aboutissement à une vraie IA voire d'une Vie Artificielle, n'est pas qu'un question de capacité de calcul).
Et du coup je lis des articles de Wikipédia, et chaque fois que je tombe sur une notion que je ne connais pas, je me met à lire l'article correspondant et je me perd... Mais j'ai déjà des questions précises. Je m'en vais les poser, et si toi, ou une autre âme charitable de ce forum veut bien y répondre je serai le plus heureux.
La première de mes questions m'est venue après la lecture d'un post sur les réseaux de neurones sur un autre forum.
Un étudiant y demande des infos sur un TP qu'il doit réaliser. La courbe d'erreur d'apprentissage en fonction du nombre de neurones (donc certaines cachées?) est à réaliser. J'imagine donc que cette courbe est croissante. C'est logique, c'est le principe de l'induction.
Sauf que quelqu'un répond que cette courbe est croissante dans un premier temps, puis DECROISSANTE ! Il parle de sur-apprentissage... Qu'est-ce que c'est ?
La deuxième question est en fait un blob de questions, parsemé de conclusions que j'ai tiré afin que quelqu'un puisse m'indiquer si je suis ou pas la bonne voie (Pourquoi est-ce qu'on doit choisir entre un Bac L et un Bac S).
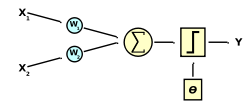
Dans l'article Wikipédia sur le neurone formel, l'auteur explique que la fonction qui "décrit" le neurone commence par faire la somme de toutes les entrées.
Ce que je comprend : On ajoute les valeurs (x) en leur appliquant un coefficient (w). Ces valeurs entrent par un nombre (m) de dendrites virtuels.
Ce que je ne comprend pas : C'est quoi ce coéf. (w) ?
Est-ce que (m) est répartit entre les neurones genre de 1 à 10 pour le neurone 1 puis de 11 à 20 pour le deuxième etc. ?
Ensuite, on explique qu'il faut ajouter une valeur w0, et que cette valeur est le seuil de la fonction et que si on utilise la fonction d'activation de base (en escalier), il vaut mieux, en fait retirer cette valeur.
Elle sort d'où cette valeur ? C'est 1 ou 0 ? C'est le résultat de la fonction d'activation ?
Je me suis arrêté là à la lecture de l'article. Après ça je suis vraiment trop largué... Mais je pense que les réponses à ces quelques questions seraient déjà un grand pas en avant vers le savoir")



 Répondre avec citation
Répondre avec citation















Partager