












Construire l'infrastructure GenAI de Meta : la société partage les détails sur deux nouveaux clusters de 24 000 GPU, qui ont été conçus pour soutenir la recherche et le développement en matière d'IA
Afin de marquer un investissement majeur de Meta dans l'avenir de l'IA, la société annonce deux clusters de 24 000 GPU et partage des détails sur le matériel, le réseau, le stockage, la conception, les performances et les logiciels qui lui permettront d'obtenir un débit élevé et une grande fiabilité pour diverses charges de travail d'intelligence artificielle. Ce cluster a notamment été utilisé pour l'entraînement du modèle Llama 3. Meta étant très attachée à l'informatique ouverte et à l'open source, elle a construit ces clusters en s'appuyant sur Grand Teton, OpenRack et PyTorch et continue d'encourager l'innovation ouverte dans l'ensemble de l'industrie. Cette annonce est une étape de l'ambitieuse feuille de route de l'infrastructure de Meta. D'ici à la fin 2024, la société souhaite continuer à développer son infrastructure, qui comprendra 350 000 GPU NVIDIA H100, dans le cadre d'un portefeuille qui disposera d'une puissance de calcul équivalente à près de 600 000 H100.
Pour être à la pointe du développement de l'IA, il faut investir massivement dans l'infrastructure matérielle. L'infrastructure matérielle joue un rôle important dans l'avenir de l'IA. Aujourd'hui, Meta partage des détails sur deux versions de son cluster de 24 576 GPU à l'échelle du centre de données. Ces clusters supportent ses modèles d'IA actuels et de la prochaine génération, y compris Llama 3, le successeur de Llama 2, le LLM qui a été rendu public, ainsi que la recherche et le développement de l'IA à travers la GenAI et d'autres domaines.
Un aperçu des clusters d'IA à grande échelle de Meta
La vision à long terme de Meta est de construire une intelligence artificielle générale (AGI) ouverte et construite de manière responsable afin qu'elle soit largement disponible pour que tout le monde puisse en bénéficier. Alors que Meta travaille à l'élaboration de l'AGI, elle a également travaillé sur la mise à l'échelle de ses clusters afin de concrétiser cette ambition. Les progrès qui sont réalisés vers l'AGI permettent de créer de nouveaux produits, de nouvelles fonctionnalités d'IA pour la famille d'applications de Meta et de nouveaux dispositifs informatiques centrés sur l'IA.
Alors que Meta construit depuis longtemps une infrastructure d'IA, elle a présenté pour la première fois en 2022 les détails de son SuperCluster de recherche en IA (RSC), doté de 16 000 GPU NVIDIA A100. Le RSC a accéléré la recherche ouverte et responsable sur l'IA en aidant l'entreprise à construire sa première génération de modèles d'IA avancés. Il a joué et continue de jouer un rôle important dans le développement de Llama et Llama 2, ainsi que de modèles d'IA avancés pour des applications allant de la vision par ordinateur, du NLP et de la reconnaissance vocale à la génération d'images et même au codage.
Sous le capot
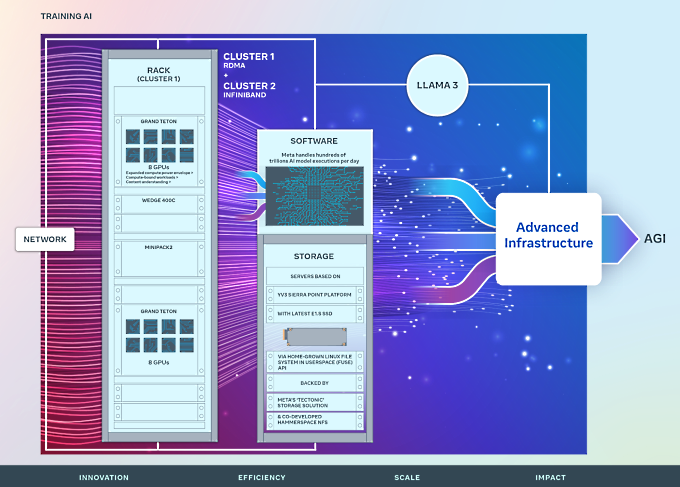
Les nouveaux clusters d'IA de Meta s'appuient sur les succès et les leçons tirées de RSC. L'entreprise s'est concentrée sur la construction de systèmes d'IA de bout en bout, en mettant l'accent sur l'expérience et la productivité des chercheurs et des développeurs. L'efficacité des réseaux haute performance au sein de ces clusters, certaines décisions clés en matière de stockage, associées aux 24 576 GPU NVIDIA Tensor Core H100 dans chacun d'eux, permettent aux deux clusters de prendre en charge des modèles plus grands et plus complexes que ceux qui pouvaient être pris en charge dans le RSC et ouvrent la voie à des avancées dans le développement de produits GenAI et la recherche en IA.
Réseau
Chez Meta, des centaines de billions d'exécutions de modèles d'IA sont traitées chaque jour. La fourniture de ces services à grande échelle nécessite une infrastructure très avancée et flexible. La conception sur mesure d'une grande partie du matériel, des logiciels et des réseaux permet à Meta d'optimiser l'expérience de bout en bout de ses chercheurs en IA, tout en garantissant l'efficacité de ses centres de données.
Dans cette optique, Meta a construit un cluster avec une solution d'accès direct à la mémoire à distance (RDMA) sur Ethernet convergé (RoCE) basée sur l'Arista 7800 avec des commutateurs rack OCP Wedge400 et Minipack2. L'autre cluster est équipé d'une structure InfiniBand NVIDIA Quantum2. Ces deux solutions interconnectent des points d'extrémité à 400 Gbps. Grâce à ces deux solutions, Meta est en mesure d'évaluer l'adéquation et l'évolutivité de ces différents types d'interconnexion pour la formation à grande échelle, ce qui lui permet de mieux comprendre la manière dont il concevra et construira à l'avenir des clusters encore plus grands et plus évolutifs. Grâce à une co-conception minutieuse du réseau, du logiciel et des architectures de modèles, Meta a réussi à utiliser les clusters RoCE et InfiniBand pour de grandes charges de travail GenAI (y compris l'entraînement en cours du Llama 3 sur le cluster RoCE) sans aucun goulot d'étranglement au niveau du réseau.
Calcul
Les deux clusters sont construits à l'aide de Grand Teton, la plateforme matérielle GPU ouverte de Meta, conçue en interne, que l'entreprise a contribué à l'Open Compute Project (OCP). Grand Teton s'appuie sur les nombreuses générations de systèmes d'IA qui intègrent les interfaces d'alimentation, de contrôle, de calcul et de structure dans un châssis unique pour améliorer les performances globales, l'intégrité des signaux et les performances thermiques. Elle offre une évolutivité et une flexibilité rapides dans une conception simplifiée, ce qui lui permet d'être rapidement déployé dans les parcs de centres de données et d'être facilement entretenu et mis à l'échelle. Associé à d'autres innovations internes telles que l'architecture d'alimentation et de rack Open Rack de Meta, Grand Teton permet de construire de nouveaux clusters d'une manière adaptée aux applications actuelles et futures de Meta.
Meta a conçu ouvertement ses plateformes matérielles GPU, en commençant par la plateforme Big Sur en 2015.
Stockage
Le stockage joue un rôle important dans la formation à l'IA, et c'est pourtant l'un des aspects dont on parle le moins. Au fur et à mesure que les tâches de formation à la GenAI deviennent plus multimodales, consommant de grandes quantités d'images, de vidéos et de données textuelles, le besoin de stockage de données augmente rapidement. La nécessité d'intégrer tout ce stockage de données dans une empreinte performante et économe en énergie ne disparaît pas pour autant, ce qui rend le problème encore plus intéressant.
Le déploiement du stockage de Meta répond aux besoins des clusters d'IA en matière de données et de points de contrôle par le biais d'une API Linux Filesystem in Userspace (FUSE) développée en interne et soutenue par une version de la solution de stockage distribué "Tectonic" de Meta optimisée pour les supports Flash. Cette solution permet à des milliers de GPU de sauvegarder et de charger des points de contrôle de manière synchronisée (un défi pour toute solution de stockage) tout en fournissant un stockage flexible et à haut débit à l'échelle du gigaoctet requis pour le chargement des données.
Meta s'est également associée à Hammerspace pour co-développer et mettre en place un système de fichiers réseau parallèle (NFS) afin de répondre aux exigences de l'expérience des développeurs pour ce cluster d'intelligence artificielle. Entre autres avantages, Hammerspace permet aux ingénieurs d'effectuer un débogage interactif des travaux utilisant des milliers de GPU, car les modifications du code sont immédiatement accessibles à tous les nuds de l'environnement. L'association de la solution de stockage distribué Tectonic de Meta et de Hammerspace permet d'accélérer la vitesse d'itération sans compromettre le passage à l'échelle.
Les déploiements de stockage dans les clusters GenAI de Meta, soutenus par Tectonic et Hammerspace, sont basés sur la plateforme de serveur YV3 Sierra Point, mise à niveau avec le dernier SSD E1.S de haute capacité que l'on peut se procurer sur le marché aujourd'hui. Outre la capacité SSD plus élevée, le nombre de serveurs par rack a été personnalisé afin d'atteindre le bon équilibre entre la capacité de débit par serveur, la réduction du nombre de racks et l'efficacité énergétique associée. En utilisant les serveurs OCP comme des blocs de construction de type Lego, la couche de stockage de Meta est capable de s'adapter de manière flexible aux exigences futures de ce cluster ainsi qu'aux futurs clusters d'IA plus importants, tout en étant tolérante aux pannes lors des opérations quotidiennes de maintenance de l'infrastructure.
Performances
L'un des principes appliqués par Meta dans la construction de ses clusters d'IA à grande échelle est de maximiser simultanément les performances et la facilité d'utilisation, sans compromettre l'un pour l'autre. Il s'agit d'un principe important pour créer les meilleurs modèles d'IA de leur catégorie.
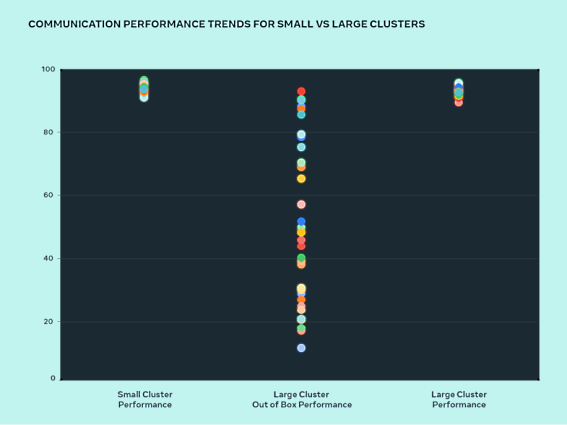
Alors que Meta repousse les limites des systèmes d'IA, la meilleure façon de tester sa capacité à faire évoluer ses conceptions est de construire un système, de l'optimiser et de le tester (les simulateurs sont certes utiles, mais ils n'ont qu'une portée limitée). Au cours de cette phase de conception, Meta a comparé les performances de ses petits clusters à celles des grands clusters afin de déterminer où se situent les goulets d'étranglement. Dans le graphique ci-dessous, les performances collectives d'AllGather sont indiquées (en tant que bande passante normalisée sur une échelle de 0 à 100) lorsqu'un grand nombre de GPU communiquent les uns avec les autres à des tailles de message où l'on s'attend à des performances de type "roofline".
Les performances prêtes à l'emploi de Meta pour les grands clusters étaient initialement médiocres et incohérentes, comparées aux performances optimisées des petits clusters. Pour y remédier, plusieurs changements ont été apportés à la façon dont le planificateur de tâches interne planifie les tâches en tenant compte de la topologie du réseau, ce qui a permis d'améliorer la latence et de minimiser le trafic vers les couches supérieures du réseau. Meta a également optimisé sa stratégie de routage réseau en combinaison avec les modifications de la bibliothèque de communications collectives de NVIDIA (NCCL) afin d'optimiser l'utilisation du réseau. Cela a permis aux grands clusters d'atteindre les performances attendues, tout comme pour les petits clusters.
Outre les changements de logiciels visant l'infrastructure interne de Meta, un travail en étroite collaboration a été effectué avec les équipes chargées de créer des frameworks et des modèles de formation afin de s'adapter à l'évolution de l'infrastructure. Par exemple, les GPU NVIDIA H100 permettent d'exploiter de nouveaux types de données tels que la virgule flottante 8 bits (FP8) pour la formation. L'utilisation complète de clusters plus importants a nécessité des investissements dans des techniques de parallélisation supplémentaires et de nouvelles solutions de stockage ont permis d'optimiser le point de contrôle sur des milliers de rangs pour qu'il s'exécute en quelques centaines de millisecondes.
Meta reconnaît également que le débogage est l'un des principaux défis de l'entraînement à grande échelle. L'identification d'un GPU problématique qui bloque tout un travail de formation devient très difficile à grande échelle. Meta construit des outils tels que desync debug, ou un enregistreur de vol collectif distribué, afin d'exposer les détails de l'entraînement distribué et d'aider à identifier les problèmes de manière beaucoup plus rapide et plus facile.
Enfin, Meta continue à faire évoluer PyTorch, le framework d'IA fondamental qui alimente ses charges de travail d'IA, afin de le rendre prêt pour des dizaines, voire des centaines de milliers d'entraînements sur GPU. Plusieurs goulets d'étranglement ont été identifiés pour l'initialisation des groupes de processus, et le temps de démarrage a été réduit de plusieurs heures à quelques minutes.
Engagement en faveur de l'innovation ouverte en matière d'IA
Meta maintient son engagement en faveur de l'innovation ouverte dans les logiciels et le matériel d'IA. Elle estime que le matériel et les logiciels open-source seront toujours un outil précieux pour aider l'industrie à résoudre des problèmes à grande échelle.
Aujourd'hui, Meta continue de soutenir l'innovation en matière de matériel ouvert en tant que membre fondateur de l'OCP, où elle met à la disposition de la communauté de l'OCP des conceptions telles que Grand Teton et Open Rack. Meta reste également le principal contributeur de PyTorch, le framework logiciel d'intelligence artificielle qui alimente une grande partie de l'industrie.
L'entreprise poursuit également son engagement en faveur de l'innovation ouverte au sein de la communauté de recherche sur l'IA. Elle a lancé la Communauté de recherche sur l'innovation ouverte dans le domaine de l'IA, un programme de partenariat pour les chercheurs universitaires afin d'approfondir notre compréhension de la manière de développer et de partager les technologies de l'IA de manière responsable, en mettant particulièrement l'accent sur les LLM.
L'approche ouverte de l'IA n'est pas nouvelle pour Meta. En effet, elle a également lancé l'AI Alliance, un groupe d'organisations de premier plan dans le secteur de l'IA, dont l'objectif est d'accélérer l'innovation responsable en matière d'IA au sein d'une communauté ouverte. Les efforts de Meta en matière d'IA reposent sur une philosophie de science ouverte et de collaboration croisée. Un écosystème ouvert apporte la transparence, le contrôle et la confiance dans le développement de l'IA et conduit à des innovations dont tout le monde peut bénéficier et qui sont construites avec la sécurité et la responsabilité en tête.
L'avenir de l'infrastructure d'IA de Meta
Ces deux clusters de formation à l'IA font partie de la feuille de route de Meta pour l'avenir de l'IA. D'ici à la fin 2024, la société souhaite poursuivre le développement de son infrastructure, qui comprendra 350 000 NVIDIA H100 dans le cadre d'un portefeuille qui disposera d'une puissance de calcul équivalente à près de 600 000 H100.
En se tournant vers l'avenir, Meta reconnait que ce qui a fonctionné hier ou aujourd'hui peut ne pas être suffisant pour répondre aux besoins de demain. C'est pourquoi elle évalue et améliore constamment chaque aspect de son infrastructure, des couches physiques et virtuelles à la couche logicielle et au-delà. L'objectif de Meta est de créer des systèmes flexibles et fiables pour soutenir l'évolution rapide des nouveaux modèles et de la recherche.
Source : Meta
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager