1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
| -- https://www.developpez.net/forums/d2163193/bases-donnees/mysql/requetes/mariadb-11-3-2-left-join-order-by-tres-lent-use-filesort/#post12009843
-- noms multilingues voir https://www.tela-botanica.org/bdtfx-nn-39692-ethnobotanique
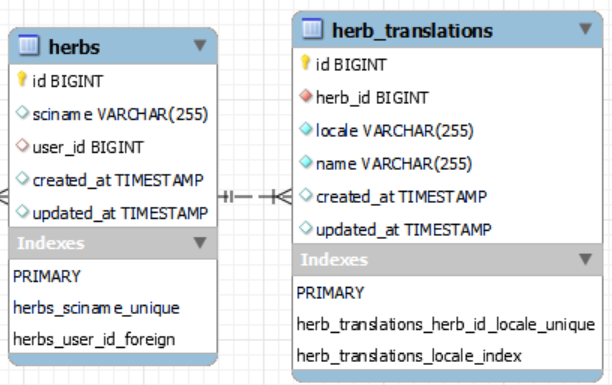
CREATE TABLE HE_herb
( HE_ident bigint unsigned NOT NULL AUTO_INCREMENT
, HE_lib varchar(255) NOT NULL
, HE_cre timestamp NOT NULL
, HE_maj timestamp NOT NULL
, PRIMARY KEY (HE_ident)
, UNIQUE KEY HE_UK01 (HE_lib)
)
;
insert into HE_herb
(HE_lib, HE_cre, HE_maj)
values ('Poa annua', current_timestamp(), current_timestamp())
, ('Cynodon dactylon', current_timestamp(), current_timestamp())
, ('Lolium perenne', current_timestamp(), current_timestamp())
, ('Bellardiochloa variegata', current_timestamp(), current_timestamp())
, ('Arrhenatherum elatius', current_timestamp(), current_timestamp())
, ('Hordeum bulbosum', current_timestamp(), current_timestamp())
, ('Festuca cyrnea', current_timestamp(), current_timestamp())
, ('Lolium rigidum lepturoides', current_timestamp(), current_timestamp())
, ('Pucinellia capillaris', current_timestamp(), current_timestamp())
, ('Puccinellia distans', current_timestamp(), current_timestamp())
, ('Puccinellia fasciculata', current_timestamp(), current_timestamp())
, ('Bromopsis benekenii', current_timestamp(), current_timestamp())
, ('Anisantha diandra', current_timestamp(), current_timestamp())
, ('Bromopsis pannonica', current_timestamp(), current_timestamp())
, ('Bromus hordeaceus jansenii', current_timestamp(), current_timestamp())
, ('Bromus japonicus subsquarrosus', current_timestamp(), current_timestamp())
, ('Bromus pseudosecalinus', current_timestamp(), current_timestamp())
, ('Bromus pseudothominei', current_timestamp(), current_timestamp())
, ('Bromus × gusuleacii', current_timestamp(), current_timestamp())
, ('Bromus × hannoverianus', current_timestamp(), current_timestamp())
, ('Bromus × karlobagensis', current_timestamp(), current_timestamp())
, ('Bromus × laagei', current_timestamp(), current_timestamp())
, ('Anisantha fasciculata', current_timestamp(), current_timestamp())
, ('Anisantha madritensis', current_timestamp(), current_timestamp())
, ('Anisantha rigida', current_timestamp(), current_timestamp())
;
select * from HE_herb
;
CREATE TABLE LG_lang
( LG_ident smallint NOT NULL AUTO_INCREMENT
, LG_code char(2) NOT NULL
, LG_lib varchar(30) NOT NULL
, PRIMARY KEY (LG_ident)
)
;
insert into LG_lang
(LG_code, LG_lib)
values ('DE', 'Deutsch')
, ('EN', 'English')
, ('ES', 'Español')
, ('FR', 'Français')
, ('IT', 'Italiano')
;
select * from LG_lang
;
CREATE TABLE TR_traduc
( HE_ident bigint unsigned NOT NULL
, LG_ident smallint NOT NULL
, TR_lib varchar(255) NOT NULL
, PRIMARY KEY (HE_ident, LG_ident)
-- , INDEX TR_IX02 (HE_ident, LG_ident, TR_lib)
, CONSTRAINT TR_FK01
FOREIGN KEY (HE_ident)
REFERENCES HE_herb(HE_ident)
ON DELETE CASCADE
, CONSTRAINT TR_FK02
FOREIGN KEY (LG_ident)
REFERENCES LG_lang(LG_ident)
ON DELETE RESTRICT
)
;
insert into TR_traduc(HE_ident, LG_ident, TR_lib)
values (01, 1, 'Einjähriges Rispengras')
, (01, 2, 'Annual Bluegrass')
, (01, 3, 'Espiguilla anual')
, (01, 4, 'Pâturin annuel')
, (01, 05, 'Fienarola annuale')
, (02, 1, 'Hundszahngras')
, (02, 2, 'Bermuda Grass')
, (02, 3, 'Grama común')
, (02, 4, 'Chiendent pied de poule')
, (02, 05, 'Gramegna')
, (03, 1, 'Ausdauerndes Weidelgras')
, (03, 2, 'Common Ray-grass')
, (03, 3, 'Raigrás')
, (03, 4, 'Ray-grass anglais')
, (04, 1, 'Violettes Rispengras')
, (04, 2, 'Violet Meadowgrass')
, (04, 3, 'Poa violácea')
, (04, 4, 'Faux-Paturin violacé')
, (05, 1, 'Französiches Raigras')
, (05, 2, 'False Oat-grass')
, (05, 3, 'Avena descollada')
, (05, 4, 'Fromental')
, (05, 5, 'Avena maggiore')
, (06, 2, 'Bulbous Barley')
, (06, 4, 'Orge bulbeuse')
, (06, 5, 'Orzo bulboso')
, (07, 4, 'Fétuque')
, (07, 5, 'Festuca di Corsica')
, (08, 4, 'Ivraie')
, (08, 5, 'Loglio marittimo')
, (10, 1, 'Abstehender Salzschwaden')
, (10, 2, 'European Alkaligrass')
, (10, 4, 'Glycérie à épillets espacés')
, (10, 5, 'Gramignone delle argille')
, (11, 1, 'Büschel-Salzschwaden')
, (11, 2, 'Borrer''s Saltmarsh-grass')
, (11, 4, 'Glycérie de Borrer')
, (11, 5, 'Gramignone delle bonifiche')
, (12, 1, 'Benekens Trespe')
, (12, 2, 'Lesser Hairy Brome')
, (12, 4, 'Brome de Beneken')
, (12, 5, 'Forasacco di Beneken')
, (13, 1, 'Gussones Trespe')
, (13, 2, 'Rip-gut Brome')
, (13, 3, 'Bromo')
, (13, 4, 'Brome à deux étamines')
, (13, 5, 'Forasacco di Gussone')
, (14, 4, 'Brome')
, (15, 4, 'Brome')
, (16, 4, 'Brome')
, (17, 2, 'Smith''s Brome')
, (17, 4, 'Brome')
, (18, 2, 'Lesser Soft-brome')
, (18, 4, 'Brome')
, (19, 4, 'Brome')
, (20, 4, 'Brome')
, (21, 4, 'Brome')
, (22, 4, 'Brome')
, (23, 4, 'Brome fasciculé')
, (23, 5, 'Forasacco insulare')
, (24, 1, 'Madrider Trespe')
, (24, 2, 'Compact Brome')
, (24, 3, 'Bromo madritense')
, (24, 4, 'Brome de Madrid')
, (24, 5, 'Forasacco dei muri')
, (25, 1, 'Rauhe Trespe')
, (25, 2, 'Great Brome')
, (25, 3, 'Bromus rígid')
, (25, 4, 'Brome rigide')
, (25, 5, 'Squala')
;
select * from TR_traduc
;
select count(*) from TR_traduc
;
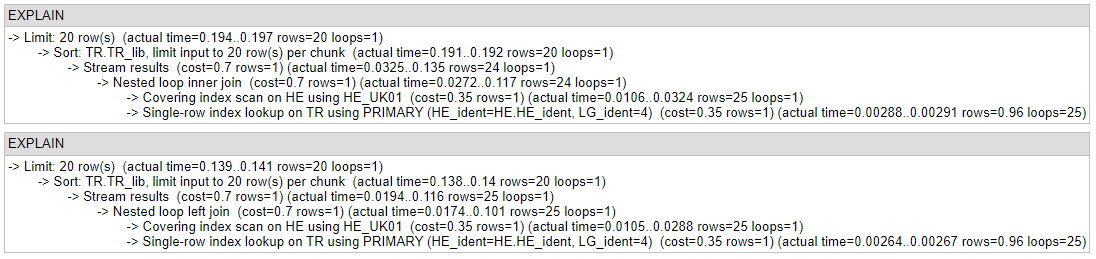
analyze
select HE.HE_ident
, HE.HE_lib
, TR.TR_lib
from HE_herb HE
inner join TR_traduc TR
on TR.HE_ident = HE.HE_ident
and TR.LG_ident = 4
order by TR.TR_lib
limit 20
;
analyze
select HE.HE_ident
, HE.HE_lib
, TR.TR_lib
from HE_herb HE
left join TR_traduc TR
on TR.HE_ident = HE.HE_ident
and TR.LG_ident = 4
order by TR.TR_lib
limit 20
; |









 Répondre avec citation
Répondre avec citation






















Partager