











DeepMind a trouvé des preuves que l'IA est capable de concevoir des images pour manipuler de manière subliminale la perception humaine.
De nouvelles recherches montrent que même des modifications subtiles d'images numériques, conçues pour confondre les systèmes de vision artificielle, peuvent également influencer la perception humaine.
Les ordinateurs et les humains voient le monde de différentes manières. Les systèmes biologiques humains et les systèmes artificiels des machines ne prêtent pas toujours attention aux mêmes signaux visuels. Les réseaux neuronaux formés à la classification des images peuvent être complètement trompés par de subtiles perturbations d'une image qu'un humain ne remarquerait même pas.
Le fait que les systèmes d'intelligence artificielle puissent être trompés par de telles images contradictoires peut mettre en évidence une différence fondamentale entre la perception humaine et celle des machines, mais cela incite aussi à chercher à savoir si les humains pouvaient, eux aussi, dans des conditions de test contrôlées, se montrer sensibles aux mêmes perturbations. Dans une série d'expériences publiées dans Nature Communications, DeepMind a trouvé des preuves que les jugements humains sont en effet systématiquement influencés par des perturbations adverses.
Cette découverte met en évidence une similitude entre la vision humaine et la vision artificielle, mais démontre également la nécessité de poursuivre les recherches pour comprendre l'influence des images parasites sur les personnes, ainsi que sur les systèmes d'intelligence artificielle.
Qu'est-ce qu'une image contradictoire ?
Une image contradictoire est une image qui a été subtilement modifiée par une procédure qui amène un modèle d'intelligence artificielle à mal classer le contenu de l'image en toute confiance. Cette tromperie intentionnelle est connue sous le nom d'"attaque contradictoire". Les attaques peuvent être ciblées pour amener un modèle d'IA à classer un vase comme un chat, par exemple, ou elles peuvent être conçues pour que le modèle voie tout sauf un vase.
Et ces attaques peuvent être subtiles. Dans une image numérique, chaque pixel d'une image RVB se trouve sur une échelle de 0 à 255, représentant l'intensité de chaque pixel. Une attaque malveillante peut être efficace même si aucun pixel n'est modulé par plus de deux niveaux sur cette échelle.
Les attaques contradictoires contre des objets physiques dans le monde réel peuvent également réussir, par exemple en faisant en sorte qu'un panneau d'arrêt soit mal identifié en tant que panneau de limitation de vitesse. En effet, les préoccupations en matière de sécurité ont conduit les chercheurs à étudier les moyens de résister aux attaques contradictoires et d'en atténuer les risques.
Comment la perception humaine est-elle influencée par des exemples contradictoires ?
Des recherches antérieures ont montré que les gens peuvent être sensibles à des perturbations d'image de grande ampleur qui fournissent des indices de forme clairs. Cependant, on connaît moins bien l'effet d'attaques contradictoires plus nuancées. Les gens considèrent-ils les perturbations d'une image comme un bruit inoffensif et aléatoire, ou peuvent-elles influencer la perception humaine ?
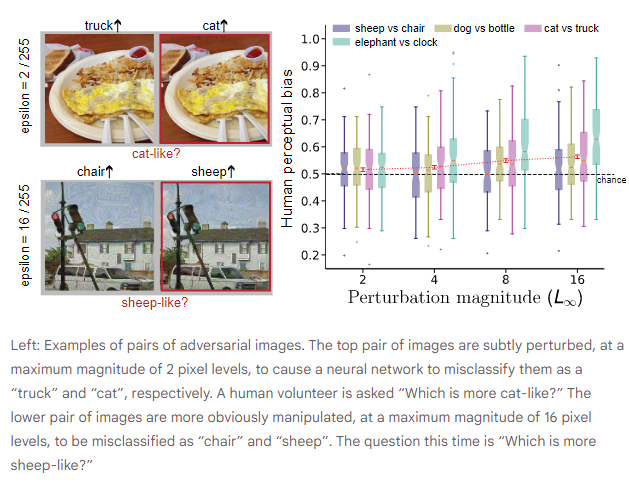
Pour le savoir, DeepMind a réalisé des expériences comportementales contrôlées. Pour commencer, ils ont pris une série d'images originales et effectué deux attaques contradictoires sur chacune d'entre elles, afin de produire de nombreuses paires d'images perturbées. Dans l'exemple ci-dessous, l'image originale est classée comme "vase" par un modèle. Les deux images perturbées par des attaques adverses sur l'image originale sont ensuite mal classées par le modèle, avec une grande confiance, comme étant les cibles contradictoires "chat" et "camion", respectivement.
Ensuite, ils ont montré la paire d'images à des participants humains et leur avons posé une question ciblée : "Quelle image ressemble le plus à un chat ?" Bien qu'aucune des deux images ne ressemble à un chat, les participants ont été obligés de faire un choix et ont généralement déclaré qu'ils avaient l'impression de faire un choix arbitraire. Si les activations cérébrales sont insensibles aux attaques adverses subtiles, on pourrait s'attendre à ce que les personnes choisissent chaque image dans 50 % des cas en moyenne. Cependant, ils ont constaté que le taux de choix - qu'on appelle le biais perceptuel - était de manière fiable supérieur au hasard pour une grande variété de paires d'images perturbées, même lorsque aucun pixel n'était ajusté de plus de 2 niveaux sur l'échelle 0-255.
Du point de vue du participant, on a l'impression qu'on lui demande de faire la distinction entre deux images pratiquement identiques. Pourtant, la littérature scientifique regorge de preuves montrant que les gens s'appuient sur des signaux perceptifs faibles pour faire des choix, des signaux qui sont trop faibles pour qu'ils expriment leur confiance ou leur conscience. Dans l'exemple, on peut voir un vase de fleurs, mais une activité cérébrale nous informe qu'il y a un soupçon de chat dans ce vase.
DeepMind a réalisé une série d'expériences qui ont permis d'écarter les explications artéfactuelles potentielles du phénomène pour son article dans Nature Communications. Dans chaque expérience, les participants ont sélectionné de manière fiable l'image contradictoire correspondant à la question ciblée plus de la moitié du temps. Bien que la vision humaine ne soit pas aussi sensible aux perturbations adverses que la vision artificielle (les machines n'identifient plus la classe d'image originale, mais les gens la voient toujours clairement), ce travail montre que ces perturbations peuvent néanmoins biaiser les humains en faveur des décisions prises par les machines.
L'importance de la recherche sur la sûreté et la sécurité de l'IA
La principale conclusion de DeepMind, à savoir que la perception humaine peut être affectée - bien que subtilement - par des images adverses, soulève des questions cruciales pour la recherche sur la sûreté et la sécurité de l'IA. Mais en utilisant des expériences formelles pour explorer les similitudes et les différences entre le comportement des systèmes visuels de l'IA et la perception humaine, on peut tirer parti de ces connaissances pour construire des systèmes d'IA plus sûrs.
Par exemple, ces résultats peuvent éclairer les recherches futures visant à améliorer la robustesse des modèles de vision informatique en les alignant mieux sur les représentations visuelles humaines. La mesure de la sensibilité humaine aux perturbations contradictoires pourrait aider à évaluer cet alignement pour une variété d'architectures de vision par ordinateur.
Ces travaux démontrent également la nécessité de poursuivre les recherches pour comprendre les effets plus larges des technologies, non seulement sur les machines, mais aussi sur les êtres humains. Cela souligne à son tour l'importance des sciences cognitives et des neurosciences pour mieux comprendre les systèmes d'IA et leurs impacts potentiels, alors qu'on s'efforce de construire des systèmes plus sûrs et plus sécurisés.
Source : "Subtle adversarial image manipulations influence both human and machine perception", DeepMind
Et vous ?
Pensez-vous que cette étude est crédible ou pertinente ?
Voir aussi :


 Répondre avec citation
Répondre avec citation



Partager