











Programming Language Benchmark v2 (plb2) évalue les performances de 20 langages de programmation sur quatre tâches gourmandes en CPU
Introduction
Programming Language Benchmark v2 (plb2) évalue les performances de 20 langages de programmation sur quatre tâches gourmandes en ressources CPU. Il s'agit d'un suivi du plb réalisé en 2011. Dans plb2, toutes les implémentations utilisent le même algorithme pour chaque tâche et leurs goulots d'étranglement en termes de performance ne se situent pas dans les fonctions de bibliothèque. On n'a pas l'intention d'évaluer les différents algorithmes ou la qualité des bibliothèques standard dans ces langages.
Les quatre tâches de plb2 prennent toutes quelques secondes à une implémentation rapide. Ces tâches sont les suivantes :
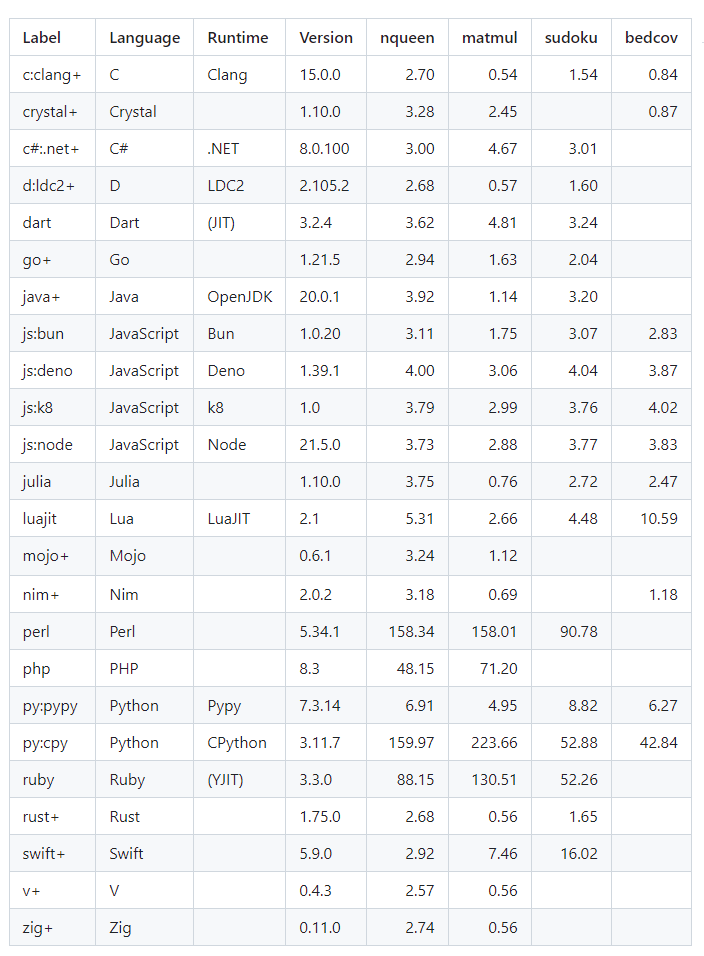
- nqueen : résolution d'un problème de 15 quilles. L'algorithme a été inspiré par la deuxième implémentation en C de Rosetta Code. Il implique des boucles imbriquées et des opérations sur des bits entiers.
- matmul : multiplication de deux matrices carrées de 1500x1500. La boucle intérieure ressemble à l'opération axpy de BLAS.
- sudoku : résolution de 4000 Sudokus difficiles (20 puzzles répétés 200 fois) à l'aide de l'algorithme kudoku. Cet algorithme utilise beaucoup de petits tableaux de taille fixe avec une logique un peu complexe.
- bedcov : recherche des chevauchements entre deux tableaux de 1 000 000 d'intervalles avec des arbres d'intervalles implicites. L'algorithme implique des accès fréquents aux tableaux selon un modèle similaire aux recherches binaires.
Tous les langages ont des implémentations nqueen et matmul. Certains langages n'ont pas d'implémentation sudoku ou bedcov. En outre, on a implémenté la plupart des algorithmes dans plb2 et adapté quelques implémentations de matmul et sudoku dans plb. Comme le développeur ayant fait l'analyse est principalement un programmeur C, les implémentations dans d'autres langages peuvent être sous-optimales et il n'y a pas d'implémentations dans les langages fonctionnels. Les pull requests sont les bienvenues !
Résultats
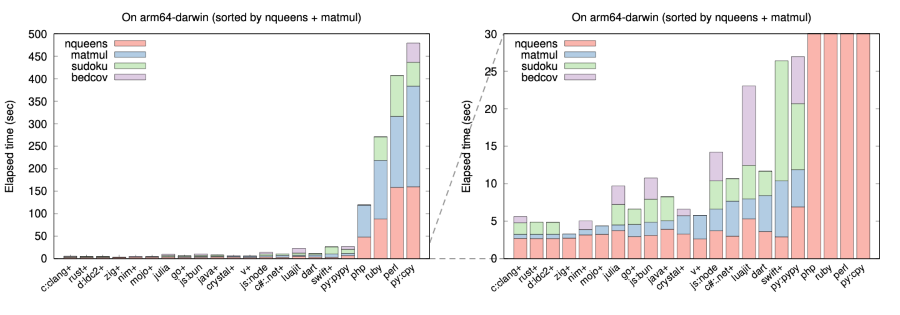
La figure suivante résume le temps écoulé de chaque implémentation mesuré sur un Apple M1 MacBook Pro. Hyperfine a été utilisée pour le chronométrage, à l'exception de quelques implémentations lentes qui ont été chronométrées avec la commande bash "time" sans répétition. Le signe "+" indique une étape de compilation explicite. Les temps exacts sont indiqués dans le tableau en dessous. La figure a été générée par programme à partir du tableau mais peut être obsolète.
Impression générale
Les implémentations de langages de programmation dans plb2 peuvent être classées en quatre groupes en fonction de la manière et du moment où la compilation est effectuée :
- Interprétation pure sans compilation (Perl et CPython, l'implémentation officielle de Python). Sans surprise, il s'agit des implémentations de langage les plus lentes dans ce benchmark.
- JIT compilé sans étape de compilation séparée (Dart, tous les runtimes JavaScript, Julia, LuaJIT, PHP, PyPy et Ruby3 avec YJIT). Ces implémentations de langage compilent le code chaud à la volée, puis l'exécutent. Elles doivent trouver un équilibre entre le temps de compilation et le temps d'exécution pour obtenir les meilleures performances globales.
- Dans ce groupe, bien que PHP et Ruby3 soient plus rapides que Perl et CPython, ils sont toujours un ordre de grandeur plus lent que PyPy. Les deux moteurs JavaScript (Bun et Node), Dart et Julia obtiennent tous de bons résultats. Ils sont environ deux fois plus rapides que PyPy.
- JIT compilé avec une étape de compilation séparée (Java et C#). Avec une compilation séparée, Java et C# peuvent se permettre d'échanger le temps de compilation contre le temps d'exécution en théorie, mais dans ce benchmark, ils ne sont pas manifestement plus rapides que ceux du groupe 2.
- Compilation anticipée (Ahead-of-time compilation) (le reste). Optimisant les binaires pour un matériel spécifique, ces compilateurs, à l'exception de Swift, tendent à générer les exécutables les plus rapides.
Mises en garde
Temps de démarrage
Certains runtimes de langages basés sur la JIT prennent jusqu'à ~0,3 seconde pour compiler et s'échauffer. On ne sépare pas ce temps de démarrage. Néanmoins, comme la plupart des tests s'exécutent pendant plusieurs secondes, l'inclusion du temps de démarrage n'affecte pas beaucoup les résultats.
Temps écoulé vs temps CPU
Bien qu'aucune implémentation n'utilise le multithreading, les moteurs d'exécution des langages peuvent effectuer des tâches supplémentaires, telles que le ramassage des miettes, dans un thread séparé. Dans ce cas, le temps CPU (utilisateur plus système) peut être plus long que le temps écoulé wall-clock. Julia, en particulier, prend sensiblement plus de temps CPU que de temps wall-clock, même pour le benchmark nqueen le plus simple. Dans plb2, on mesure le temps écoulé wall-clock parce que c'est le chiffre que les utilisateurs voient souvent. Le classement du temps CPU peut être légèrement différent.
Optimisations subtiles
Contrôle de la disposition de la mémoire
Lors de l'implémentation de bedcov dans Julia, C et de nombreux langages compilés, il est préférable d'avoir un tableau d'objets dans un bloc de mémoire contigu, de sorte que les objets adjacents soient proches en mémoire. Cela permet d'améliorer l'efficacité du cache. Dans la plupart des langages de script, malheureusement, on doit placer les références aux objets dans un tableau au détriment de la localité du cache. Ce problème peut être résolu en clonant les objets dans un nouveau tableau. Cela permet de doubler la vitesse de PyPy et Bun.
Optimisation des boucles internes
Le goulot d'étranglement de la multiplication matricielle se trouve dans la boucle imbriquée suivante :
Il est évident que c[i], b[k] et a[i][k] peuvent être déplacés hors de la boucle interne pour réduire la fréquence d'accès à la matrice. Le compilateur Clang peut appliquer cette optimisation. L'optimisation manuelle peut en fait nuire aux performances.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4for (int i = 0; i < n; ++i) for (int k = 0; k < n; ++k) for (int j = 0; j < n; ++j) c[i][j] += a[i][k] * b[k][j];
Cependant, la plupart des autres langages ne peuvent pas optimiser cette boucle imbriquée. Si on déplace manuellement a[i][k] vers la boucle située au-dessus, on peut souvent améliorer leurs performances. Certains programmeurs C/C++ affirment que les compilateurs optimisent souvent mieux que les humains, mais ce n'est pas forcément le cas dans d'autres langages.
Discussions
Le test de référence le plus connu et le plus ancien est le Computer Language Benchmark Games. Plb2 diffère en ce sens qu'il inclut des langages plus récents (par exemple Nim et Crystal), davantage de moteurs d'exécution (par exemple PyPy et LuaJIT), plus de tâches, des implémentations plus uniformes et se concentre davantage sur les performances du langage lui-même, sans les fonctions de bibliothèque. Il complète les Computer Language Benchmark Games.
Un domaine important que plb2 n'évalue pas est la performance de l'allocation de la mémoire et/ou du ramasse-miettes. Cela peut contribuer davantage aux performances pratiques que la génération de code machine. Néanmoins, il est difficile de concevoir un micro-benchmark réaliste pour évaluer l'allocation de mémoire. Si l'allocateur intégré dans l'implémentation d'un langage ne fonctionne pas bien, on peut implémenter un allocateur de mémoire personnalisé juste pour la tâche spécifique, mais cela ne représenterait pas des cas d'utilisation typiques.
Lorsque le projet plb a été mené en 2011, la moitié des langages figurant dans la figure ci-dessus n'étaient pas matures ou n'existaient même pas. Il est passionnant de constater que nombre d'entre eux ont franchi le cap de la version 1.0 et gagnent en popularité auprès des programmeurs modernes. D'autre part, Python reste l'un des deux langages de script les plus utilisés malgré ses faibles performances. Cela s'explique par le fait que PyPy ne serait pas officiellement approuvé, tandis que d'autres langages basés sur la technologie JIT ne sont pas suffisamment généraux ou performants. Y aura-t-il un langage pour remplacer Python au cours de la prochaine décennie ? Pas optimiste.
Appendix: Timing on Apple M1 Macbook Pro
Source : GitHuB
Et vous ?
Pensez-vous que cette analyse comparative est crédible ou pertinente ?
Voir aussi :
 Répondre avec citation
Répondre avec citation







Partager