













Des chercheurs de Google mettent à mal la théorie selon laquelle l'IA est sur le point d'être plus intelligente que l'homme
éloignant ainsi la perspective imminente de l'AGI
Des chercheurs de Google remettent en question la perspective selon laquelle l'intelligence artificielle (IA) est sur le point de surpasser l'intelligence humaine. Dans un nouvel article soumis à ArXiv, publié le 1er novembre, une équipe de chercheurs de Google met en lumière les limitations des transformateurs, la technologie sous-jacente aux grands modèles de langage alimentant des outils tels que ChatGPT.
Ils démontrent que ces transformateurs ont des difficultés de généralisation lorsqu'ils sont confrontés à des tâches en dehors du domaine de leurs données d'entraînement, compromettant ainsi leur capacité à extrapoler même des tâches simples. Cette découverte pose un défi aux aspirations d'atteindre une intelligence artificielle générale (AGI), capable de rivaliser avec les dispositions humaines dans divers domaines. Les chercheurs soulignent que l'IA actuelle excelle dans des tâches spécifiques mais peine à transférer des compétences d'un domaine à l'autre, éloignant ainsi la perspective imminente de l'AGI.
Pedro Domingos, professeur émérite d'informatique à l'université de Washington, estime qu'il est prématuré d'être trop optimiste quant à l'arrivée prochaine de l'IA générale. Les résultats de cette recherche révèlent les limites des modèles de langage, incitant à une réévaluation des attentes envers l'IA et soulignant la nécessité de comprendre plus précisément ses capacités réelles.
Transformateurs et AGI : Évaluer l'Adaptabilité au-delà des Tâches Pré-Entraînées
Les modèles transformateurs, notamment les grands modèles de langage (LLM), ont la possibilité remarquable d'effectuer un apprentissage en contexte (ICL), c'est-à-dire d'exécuter de nouvelles tâches lorsqu'ils sont confrontés à des exemples d'entrée-sortie inédits, sans formation explicite du modèle.
Dans ce travail, les chercheurs ont étudié l'efficacité avec laquelle les transformateurs peuvent faire le lien entre leur mélange de données de préformation, composé de plusieurs familles de tâches distinctes, afin d'identifier et d'apprendre de nouvelles tâches en contexte qui sont à la fois à l'intérieur et à l'extérieur de la distribution de préformation.
« Lorsqu'on leur présente des tâches ou des fonctions qui sont hors du domaine de leurs données de pré-entraînement, nous démontrons divers modes de défaillance des transformateurs et une dégradation de leur généralisation pour des tâches d'extrapolation même simples », écrivent les auteurs Steve Yadlowsky, Lyric Doshi et Nilesh Tripuraneni.
Selon les chercheurs, les transformateurs sont capables d'effectuer des tâches en rapport avec les données sur lesquelles ils ont été formés. Ils ne sont pas très doués pour les tâches qui vont un tant soit peu au-delà.
C'est un problème pour ceux qui espèrent parvenir à l'intelligence artificielle générale (AGI), terme utilisé par les techniciens pour décrire une IA hypothétique capable de faire tout ce que font les humains. À l'heure actuelle, l'IA est plutôt douée pour des tâches spécifiques, mais elle est moins douée pour transférer des compétences d'un domaine à l'autre, comme le font les humains.
L'AGI a été présentée comme l'objectif ultime du domaine de l'IA car elle représente le moment, en théorie, où l'humanité crée quelque chose qui est aussi intelligent qu'elle-même, ou plus intelligent qu'elle. Selon votre point de vue, il s'agit d'un scénario prométhéen alarmant ou d'un scénario définissant une ère. Quoi qu'il en soit, un grand nombre d'investisseurs et de techniciens consacrent beaucoup de temps et d'investissements pour y parvenir. Pour y parvenir, il faut que l'IA soit capable de réaliser une grande partie des tâches de généralisation que le cerveau humain peut accomplir, qu'il s'agisse de s'adapter à des scénarios inconnus, de créer des analogies, de traiter de nouvelles informations ou de penser de manière abstraite.
Mais si la technologie peine à accomplir ne serait-ce que des « tâches d'extrapolation simples », comme le notent les chercheurs, il est clair que nous n'en sommes pas encore là. « Cet article ne porte même pas sur les LLM, mais il semble être la goutte d'eau qui a fait déborder le vase de la croyance collective et qui a amené de nombreuses personnes à accepter les limites des LLM », a écrit Arvind Narayanan, professeur d'informatique à Princeton, sur le site X. « Il était temps ».
Préliminaires
Les chercheurs ont considéré un modèle de génération de données avec des covariables à plusieurs dimensions dessinées xi∼N(0,Id) et une fonction (aléatoire) f∼D(F) est échantillonnée à partir d'une distribution sur les classes de fonctions. Ils encadrent le problème ICL en fournissant une seule séquence d'invite s=(x1,f(x1),x2,f(x2),...xn,f(xn),xn+1) au modèle (c.-à-d. un transformateur) et en générant une prédiction pour f(xn+1) : ils désignent le problème de la prédiction du prochain jeton par l'expression « apprentissage en contexte ». La performance d'un apprenant en contexte est jugée par sa perte prédictive au carré E[( f(xn+1)-f(xn+1))2], l'attente étant prise en compte pour le caractère aléatoire de l'invite et de la requête.
Dans un rapport de recherche intitulé What can transformers learnin-context ? A case study of simple function classes et Advances in Neural Information Processing Systems, Les chercheurs S.Garg, D.Tsipras, P.S.Liang, et G.Valiant ont démontré qu'en entraînant un modèle de transformation sur des profils simulés représentés par de telles séquences, ce modèle est capable d'apprendre en contexte des fonctions inédites tirées de la même classe de fonctions au moment du test.
Les chercheurs E.Aky¨ urek, D.Schuurmans, J.Andreas ont étudié la capacité des transformateurs à comprendre des modèles linéaires en contexte et fournir des interprétations mécanistes de la façon dont ils peuvent effectuer un tel apprentissage. Dans leur rapport intitulé Pretraining task diversity and the emergence of non-bayesianin-context learning for regression, A.Ravent´os, M.Paul, F.Chen, et S.Ganguli montrent le rôle de la diversité des fonctions d'interprétation pour l'apprentissage en contexte dans le cadre de la régression linéaire pure, en soutenant qu'une distribution suffisamment diversifiée sur les tâches linéaires dans l'interprétation est nécessaire pour l'apprentissage en temps réel.
Les chercheurs Y.Bai, F.Chen, H.Wang, C.Xiong, et S.Mei ont effectué un travail sur la sélection de modèles est et qui explore la capacité des transformateurs à opérer une sélection de modèles sur des bases empiriques et fournit des garanties théoriques rigoureuses pour les propriétés de généralisation des transformateurs dans l'entraînement à l'interprétation et les performances de prédiction en contexte.
Les garanties et les principes empiriques de ces chercheurs se limitent à des explorations sur la sélection de modèles parmi différentes familles de classes de fonctions linéaires, à savoir l'étude de la sélection de modèles dans des mélanges de tâches à pondération variable de régression linéaire avec différentes forces de bruit d'étiquette et de régression linéaire. Dans ce cadre, étant donné une source de données D contenant des séquences Si = (xi,1,f(xi,1),...,xi,n,f(xi,n)), on apprend les paramètres θ du(des) modèle(s) de transformation en effectuant une minimisation de la perte sur l'objectif de « renforcement de la fonction formative ».
Pour la perte quadratiqueℓ, où si,1:j est utilisé pour désigner la i-séquence jusqu'à (mais sans inclure) la j-sortie f(xi,j). Ils utilisent un modèle de décodage de 9,5 millions de paramètres avec 12 couches, 8 têtes d'attention et un espace d'encastrement de 256 dimensions.
Phénomènes de sélection des modèles
L'une des questions qui se posent lorsque l'on interprète un mélange de données d'entraînement de différentes classes de fonctions est la suivante : « Comment le modèle sélectionne-t-il entre les différentes classes de fonctions lorsqu'elles sont présentées avec des exemples de contextes internes à l'appui du mélange d'entraînement ? » Les chercheurs ont répondu à cette question d'un point de vue empirique. Ils constatent que les modèles font des prédictions optimales (ou presque) après avoir vu des exemples dans le contexte d'une classe de fonctions qui fait partie du mélange de données d'entraînement à l'interprétation.
Ils observent également comment les modèles fonctionnent sur des fonctions qui ne font pas clairement partie d'une classe de fonctions à composante unique avant d'explorer certaines fonctions qui sont définitivement hors de la distribution de toutes les données d'entraînement à l'interprétation de la section. Ils ont commencé par l'étude des fonctions linéaires, qui n'ont jamais fait l'objet d'une attention significative dans ce domaine de l'apprentissage en contexte.
Les chercheurs S.Garg, D.Tsipras, P.S.Liang, et G.Valiant montrent que les transformateurs formés aux fonctions linéaires ont des performances presque optimales dans l'apprentissage en contexte de nouvelles fonctions linéaires. En particulier, ils considèrent deux modèles : un modèle entraîné sur des fonctions linéaires (où tous les coefficients du modèle linéaire sont non nuls) et un modèle entraîné sur des fonctions linéaires d'espace (où seuls 2 des 20 coefficients sont non nuls).
Les performances de chaque modèle sont équivalentes à celles de la régression linéaire et de la régression de Lassore sur les nouvelles fonctions linéaires denses et linéaires dispersées, respectivement. Les chercheurs de Google ont également comparé ces deux modèles pour obtenir un modèle entraîné sur un mélange de fonctions linéaires dispersées.
Par exemple, ils ont démontré que les transformateurs entraînés par interprétation sont capables d'obtenir des résultats aussi bons que les méthodes LML les plus récentes sur des classes de fonctions linéaires (avec des vecteurs de coefficient à la fois rares et denses) lorsque les données entraînées sont générées à partir de fonctions linéaires, d'arbres de décision lorsque les données entraînées sont générées à partir d'arbres de décision, et de réseaux ReLU lorsque les données entraînées sont générées à partir de réseaux ReLU.
Les chercheurs ont examiné de manière empirique l'impact de la composition des données d'entraînement sur la capacité des transformateurs à apprendre des classes de fonctions à l'intérieur et à l'extérieur de la distribution de leurs données d'entraînement. Leur étude a révélé que, pour les classes de fonctions bien représentées dans le mélange d'entraînement, le coût de sélection de la classe de fonctions appropriée pour l'apprentissage en contexte est pratiquement nul.
Cependant, ils ont constaté que les transformateurs entraînés par interprétation ne peuvent pas prédire efficacement la combinaison de fonctions provenant des classes pré-entraînées. De plus, les transformateurs montrent une capacité de généralisation efficace sur des sections plus larges de l'espace des classes de fonctions, mais ils rencontrent des difficultés lorsque les tâches sortent de la distribution pré-entraînée.
Les chercheurs ont également exploré l'entraînement d'un modèle en langage parlé, soulignant les défis et la nécessité d'évaluer les propriétés de sélection de modèles et de généralisation hors distribution dans ce contexte. Dans le domaine du langage naturel, ils reconnaissent la complexité des émotions liées à la définition des familles de tâches, aux mélanges d'entraînement et aux combinaisons de conversions. Ils concluent en soulignant l'importance de combler le fossé entre ces émotions et la modélisation du langage pour améliorer la compréhension de la puissance de l'apprentissage machine et de son activation efficace.
Source : Chercheurs de Google
Et vous ?
Les conclusions des travaux des chercheurs de Google sont-elles pertinentes ?
Voir aussi :

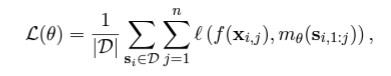
 Répondre avec citation
Répondre avec citation
Partager