











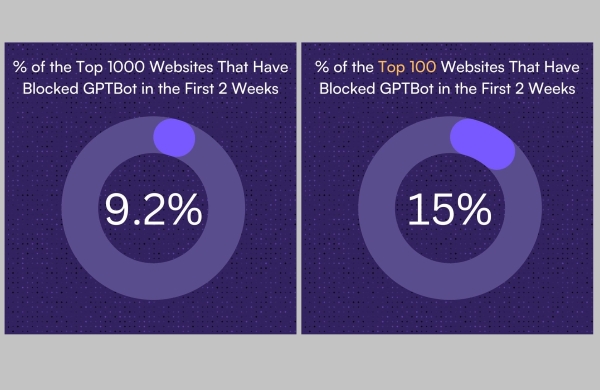
15% du top 100 des sites web ont bloqué GPTBot, le webcrawler d'Open AI, selon une étude d'Originality.AI.
La poussée d'OpenAI dans une variété de services différents a été aidée en grande partie par ChatGPT. Le chatbot d'IA a transformé la façon dont les gens pensent à l'IA en général, et ses dernières tentatives pour capitaliser sur son nouveau succès impliquent l'utilisation d'un webcrawler appelé GPTBot. Ce webcrawler augmentera l'ensemble des données de ChatGPT, ce qui rendra ses réponses plus précises qu'elles ne l'auraient été autrement, mais il s'avère que de nombreux sites web le bloquent.
Ceci étant dit, il est important de noter que 69 des 1000 premiers sites web au monde ont bloqué GPTBot. Cela représente un peu moins de 7 %, et si nous nous concentrons sur les cent premiers sites web, cette proportion s'élève à 15 %. Les sites web agissent de la sorte parce que cela pourrait empêcher GPT de gratter leur contenu à leur insu.
Parmi ces sites figurent des poids lourds tels qu'Amazon, Quora, Shutterstock, le New York Times et CNN. Ce ne sont là que quelques-uns des sites web qui ont bloqué GPTBot jusqu'à présent, et leur nombre augmente de 5 % chaque semaine.
Un autre webcrawler bloqué est CCBot, le robot d'exploration du web lancé par Common Crawl. ChatGPT et OpenAI s'appuient également sur ce webcrawler afin de collecter des données pour leurs systèmes, qui peuvent être utilisées pour former leur IA de manière beaucoup plus efficace, et l'analyse a montré que 62 des 1000 premiers sites web sur l'internet l'ont bloqué jusqu'à présent.
Cela n'augure rien de bon pour l'avenir du secteur, car les entreprises spécialisées dans l'IA dépendront de ces ensembles de données. La plupart des propriétaires de sites web ne souhaitent pas que leurs données soient récupérées, et il sera intéressant de voir comment les choses évolueront à partir de maintenant. OpenAI pourrait être contraint d'acheter des données au lieu de se contenter de les récupérer, ce qui lui ferait perdre beaucoup de revenus.
Source : Originality.AI
Et vous ?
Pensez-vous que cette étude est crédible ou pertinente ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager