











Les limites et perspectives des benchmarks pour évaluer les performances de l'IA par rapport aux performances humaines.
Les dernières années ont été marquées par des progrès incessants dans les capacités de l'IA, mais notre capacité à évaluer ces capacités n'a jamais été aussi mauvaise. L'un des principaux responsables ? Les benchmarks. Douwe Kiela,Tristan Thrush, Kawin Ethayarajh, Amanpreet Singh ont publié un article "Plotting Progress in AI" concernant les benchmarks utilisés pour évaluer l'IA. Dans leurs études, ils constatent les limites et les problèmes de ces benchmarks. Voici un extrait de leur article.
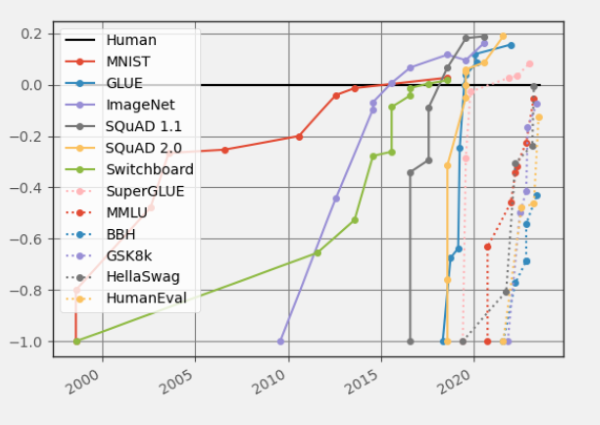
De nouveaux graphiques pour une nouvelle èreNous avons identifié ce problème dès 2021 et avons soutenu que les benchmarks devraient être aussi dynamiques que les modèles qu'ils évaluent. Pour rendre cela possible, nous avons introduit une plateforme appelée Dynabench pour créer des benchmarks vivants et en constante évolution. Dans le cadre de la publication, nous avons créé une figure qui montre la rapidité avec laquelle les benchmarks d'IA "saturent", c'est-à-dire que les systèmes de pointe commencent à surpasser les performances humaines dans une variété de tâches.
Mais aujourd'hui, ce graphique est désespérément dépassé. Compte tenu de la rapidité avec laquelle l'IA a progressé au cours des dernières années, les ensembles de données semblent presque préhistoriques. Il est grand temps de mettre à jour les diagrammes, avec de nouveaux ensembles de données. Les progrès récents ont surtout été réalisés grâce aux modèles de langage, et nous allons donc nous pencher sur des critères d'évaluation de modèles de langage bien connus en particulier :
Lorsque GLUE a été introduit, il a été saturé en l'espace d'un an. La même chose s'est produite encore plus rapidement pour SuperGLUE, qui était censé le remplacer en tant qu'alternative plus durable. Cela a déclenché une réaction dans le domaine : des benchmarks beaucoup plus difficiles ont été créés. Dans le même temps, grâce à la démonstration de l'apprentissage en contexte de GPT-3 (et à l'augmentation du nombre de paramètres), les modèles ont commencé à être évalués dans des contextes de zéro ou de quelques essais. Cela conduit à des courbes comparativement moins raides, quoique légèrement.
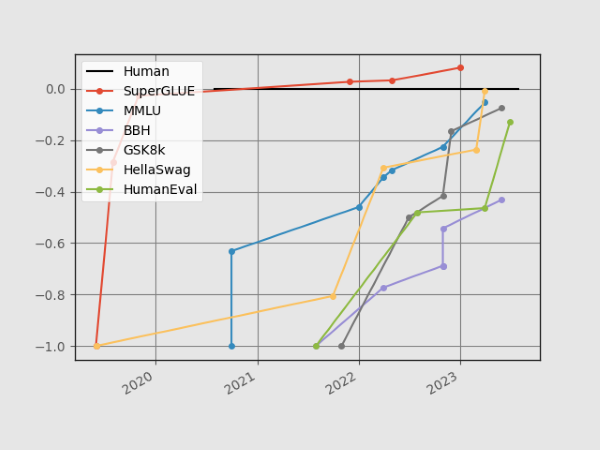
Néanmoins, nous constatons qu'avec les progrès récents, les repères s'approchent à nouveau rapidement de la saturation. Les ensembles de données très difficiles comme HellaSwag sont désormais pratiquement résolus. Seul BigBench-Hard, un sous-ensemble difficile de BigBench, présente encore des performances relativement inférieures à ses chiffres de base initiaux lorsqu'il est comparé aux performances humaines.
Zoom arrière
En superposant les nouveaux chiffres aux anciens, nous pouvons observer que le taux de changement entre l'introduction d'un benchmark et sa résolution est encore très différent de ce qu'il était avant la révolution de l'IA :
L'état de l'analyse comparativeComment ces chiffres ont-ils été calculés ?
Pour chaque critère de référence, nous avons pris comme "point de départ" la ligne de base la plus performante indiquée dans l'article sur le critère, que nous avons fixée à -1. Le chiffre de la performance humaine est fixé à 0. En somme, pour chaque résultat X, nous l'évaluons comme (X-Humain)/Abs(Point de départ-Humain). La recherche de résultats a été grandement facilitée par Paperswithcode.
Il existe aujourd'hui un large consensus sur le fait que l'IA est freinée par une évaluation comparative appropriée. Il s'agit notamment de procéder à une évaluation humaine rigoureuse et à un "red teaming" des modèles afin d'en révéler les faiblesses et d'y remédier. On assiste également à une poussée vers un étalonnage plus holistique, comme dans le HELM de Stanford (et comme le préconisait à l'origine Dynaboard). Le déploiement de modèles au fil du temps est essentiellement un processus d'analyse comparative dynamique et contradictoire à l'échelle de la communauté, dans lequel de nouvelles analyses comparatives sont créées sur la base des modes de défaillance de l'état actuel de la technique, ce qui permet d'améliorer sans cesse les capacités des systèmes.
Dynabench appartient désormais à MLCommons (Meta en a transféré la propriété en 2022), le consortium d'ingénierie ouverte dont la mission est de bénéficier à la société en accélérant l'innovation dans le domaine de l'IA. La plateforme est toujours en activité : en plus des tâches originales, elle a accueilli des défis tels que Flores, DataPerf et BabyLM. Les ensembles de données contradictoires dynamiques introduits par la plateforme sont loin d'être résolus et, plus important encore, la philosophie de l'évaluation contradictoire et holistique inaugurée par Dynabench, Dynaboard et GEM est en train de se généraliser.
Ce n'est que le commencement
L'évaluation n'est jamais un sujet facile. Un exemple récent est la grande différence dans le classement des modèles de langage sur différents tableaux de bord censés rendre compte de la même chose. De minuscules changements dans de simples mesures d'évaluation peuvent conduire à des résultats très différents. Il n'existe pas de cadre normalisé convenu et nous en sommes réduits à utiliser des modèles linguistiques pour évaluer d'autres modèles linguistiques. Des entreprises innovantes, comme Patronus, cherchent à améliorer leur travail dans ce domaine.
L'IA n'en est qu'à ses débuts. Les modèles linguistiques sont une excellente technologie de première génération, mais ils présentent encore des lacunes très importantes. Certains d'entre eux sont confirmés par les critères d'évaluation, mais la communauté des chercheurs ne sait même pas comment évaluer de nombreux aspects des modèles de langage en premier lieu.
Chez Contextual AI, ils résolvent activement les principales limitations pour les entreprises qui cherchent à proposer à leurs clients des produits alimentés par des LLM à grande échelle, notamment les attributions, les hallucinations, l'obsolescence des données et la protection de la vie privée. Après les jeux de tests statiques, le benchmarking dynamique, le red teaming, les classements ELO et les outils de psychologie du développement, il reste encore beaucoup de travail à faire pour évaluer correctement les LLM, en particulier lorsqu'il s'agit d'évaluer la qualité de l'information.
Source : Contextual AI
Et vous ?
Pensez-vous que cette étude est crédible ou pertinente ?
Voir aussi :
 Répondre avec citation
Répondre avec citation










Partager