












Quel est le meilleur chatbot d'intelligence artificielle ? Cette étude pourrait apporter la réponse, en attribuant le podium à ChatGPT 4 et à deux versions du chatbot Claude d'Anthropic
Il semble que toutes les grandes entreprises technologiques essaient de mettre au point leur propre chatbot d'IA. Microsoft a mis la main sur OpenAI et ChatGPT, ce qui en fait l'un des plus grands acteurs de cette toute nouvelle arène. Google est également entré en lice avec Bard, et Microsoft fait monter les enchères avec Bing en incorporant un chatbot IA dans sa propre propriété.
La question se pose donc de savoir quel chatbot IA est meilleur que les autres. L'université de Berkeley a tenté d'apporter une réponse appropriée en s'associant à l'université de San Diego et à Carnegie Mellon pour former la Large Model Systems Organization, ou LMSYS Org en abrégé.
Le groupe se compose de quatre membres de la faculté qui s'intéressent tout particulièrement à l'IA et à l'informatique, et qui mènent des recherches dans ces domaines. Ils sont accompagnés de dix étudiants, et ces 14 personnes ont participé à ce que l'on appelle un "Chatbot Arena".
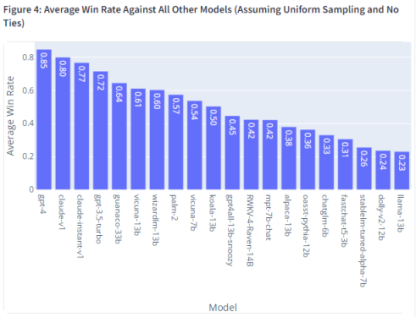
Cela permet aux participants au test de comparer et d'opposer deux chatbots en même temps. Il convient de mentionner que les participants n'ont été informés des chatbots IA avec lesquels ils parlaient qu'après le test. Ils ont voté pour le chatbot qu'ils préféraient en fonction des réponses qu'ils ont reçues, et le fait de ne pas connaître le nom du chatbot avec lequel ils conversaient a sans doute réduit les biais dans une large mesure.
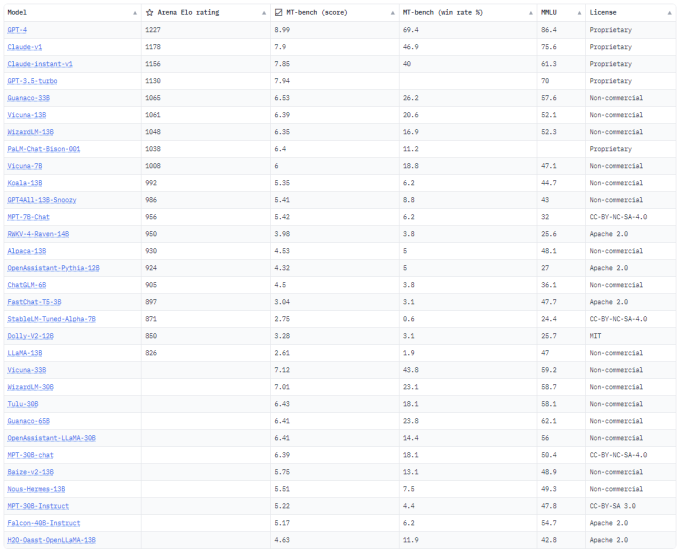
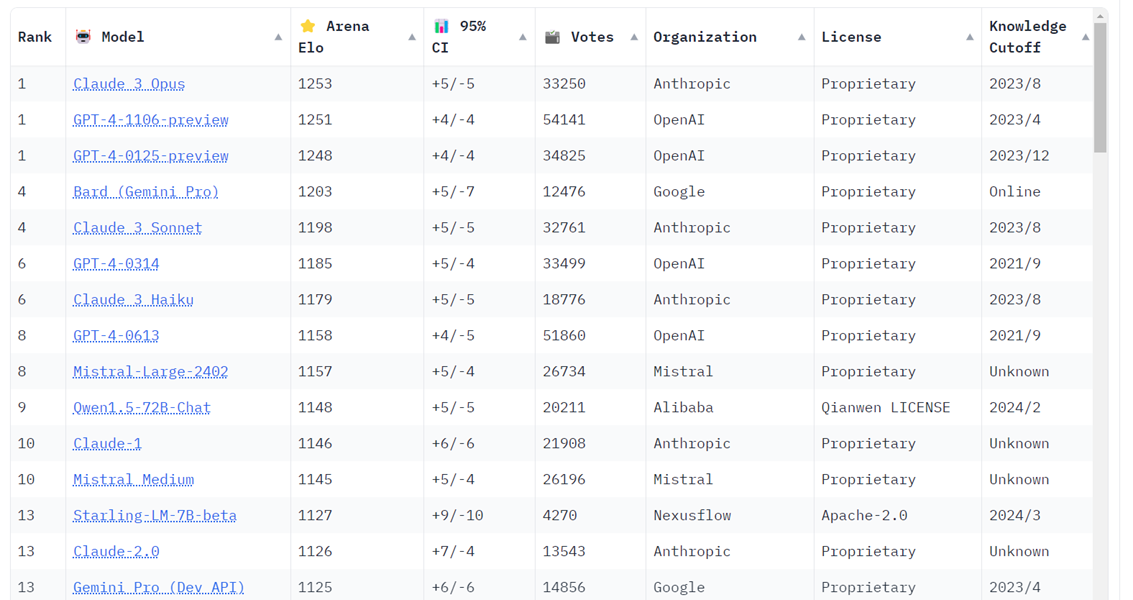
Au final, ChatGPT 4 est arrivé en tête du classement avec un score de 1 225. Claude d'Anthropic est arrivé en deuxième et troisième position, avec une version qui a obtenu un score de 1 195 et une autre qui a reçu une note Elo de 1 153. Si vous ne voulez pas payer 20 $ par mois pour GPT 4, vous pouvez toujours utiliser la version gratuite ChatGPT 3.5 qui s'est classée quatrième avec un score Elo global de 1 143.
Source : Large Model Systems Organization
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi
 Répondre avec citation
Répondre avec citation





Partager