













Google construit un modèle d'IA capable de comprendre les 1000 langues les plus parlées dans le monde,
pour battre le chatGPT soutenu par Microsoft
Alors que Microsoft annonce la sortie imminente de GPT-4, Google révèle son projet de construction dun modèle d'IA en 1 000 langues pour battre le ChatGPT soutenu par Microsoft. Les géants du numérique tels que Microsoft et Google auraient déjà un avantage certain dans la course mondiale à lintelligence artificielle. Si ces grandes entreprises nouent aujourdhui de nombreux partenariats avec des organismes de recherche pour alimenter en données les algorithmes et les améliorer, elles conservent néanmoins la main sur leur actif stratégique dont elles déterminent les conditions daccès éventuel et les modalités dutilisation.
Aujourdhui, la question semble être celle de savoir laquelle de ces deux entreprises pourra contrôler lIA dans les prochaines années. La compétition entre ces deux, Google et Microsoft, pour imposer leur propre modèle dintelligence artificielle générative est encore très ouverte. Et les start-up nont pas dit leur dernier mot.
Google développe toutes sortes de technologies d'IA, y compris ce modèle universel de la parole, dans le cadre de sa tentative de construire un modèle capable de comprendre les 1000 langues les plus parlées dans le monde.
En plus de son projet de présenter plus de 20 produits alimentés par l'intelligence artificielle lors de son événement annuel I/O cette année, Google progresse vers son objectif de construire un modèle de langage d'IA qui prend en charge 1 000 langues différentes. Dans une mise à jour publiée lundi, Google a fourni davantage d'informations sur le modèle universel de la parole (USM), un système qu'il décrit comme une « première étape essentielle » dans la réalisation de ses objectifs.
En novembre dernier, l'entreprise a annoncé son intention de créer un modèle linguistique prenant en charge 1 000 des langues les plus parlées au monde, tout en dévoilant son modèle USM. Google décrit USM comme « une famille de modèles vocaux de pointe » avec 2 milliards de paramètres entraînés sur 12 millions d'heures de parole et 28 milliards de phrases dans plus de 300 langues.
Cependant, certaines de ces langues sont parlées par moins de vingt millions de personnes. L'un des principaux défis est donc de savoir comment prendre en charge les langues pour lesquelles il y a relativement peu de locuteurs ou peu de données disponibles.
USM, que YouTube utilise déjà pour générer des sous-titres, prend également en charge la reconnaissance automatique de la parole (ASR). Celle-ci détecte et traduit automatiquement les langues, notamment l'anglais, le mandarin, l'amharique, le cebuano, l'assamais, etc.
À l'heure actuelle, Google affirme que USM prend en charge plus de 100 langues et servira de "base" à la construction d'un système encore plus étendu. Meta travaille sur un outil de traduction IA similaire qui en est encore à ses débuts. Pour en savoir plus sur l'USM et son fonctionnement, consultez le document de recherche publié par Google ici.Envoyé par Google Research
Cette technologie pourrait être utilisée dans des lunettes à réalité augmentée, comme le concept présenté par Google lors de la conférence I/O de l'année dernière, capables de détecter et de fournir des traductions en temps réel qui apparaissent sous vos yeux. Cette technologie semble encore un peu lointaine, cependant, et la mauvaise représentation de la langue arabe par Google lors de l'événement I/O prouve à quel point il peut être facile de se tromper.
Défis actuelle de lASR
Pour atteindre cet objectif ambitieux, Google doit relever deux défis importants dans le domaine de la reconnaissance automatique de caractères. Tout d'abord, les approches conventionnelles d'apprentissage supervisé manquent d'évolutivité. L'un des défis fondamentaux de l'extension des technologies vocales à de nombreuses langues est d'obtenir suffisamment de données pour former des modèles de haute qualité. Avec les approches conventionnelles, les données audio doivent être soit étiquetées manuellement, ce qui prend du temps et est coûteux, soit collectées à partir de sources avec des transcriptions préexistantes, qui sont plus difficiles à trouver pour les langues qui ne sont pas largement représentées.
En revanche, l'apprentissage auto-supervisé peut exploiter les données audio uniquement, qui sont disponibles en quantités beaucoup plus importantes dans toutes les langues. L'auto-supervision est donc une meilleure approche pour atteindre notre objectif de passer à l'échelle de centaines de langues.
Un autre défi réside dans le fait que les modèles doivent s'améliorer de manière efficace sur le plan informatique tout en élargissant la couverture et la qualité des langues. Pour ce faire, l'algorithme d'apprentissage doit être flexible, efficace et généralisable. Plus précisément, un tel algorithme devrait être capable d'utiliser de grandes quantités de données provenant de diverses sources, de permettre des mises à jour de modèles sans nécessiter un réentraînement complet, et de se généraliser à de nouvelles langues et à de nouveaux cas d'utilisation.
Apprentissage auto-supervisé avec réglage fin
USM utilise l'architecture standard codeur-décodeur, où le décodeur peut être CTC, RNN-T ou LAS. Pour le codeur, USM utilise le Conformer, ou transformateur augmenté par convolution. Le composant clé du Conformer est le bloc Conformer, qui se compose de modules d'attention, d'anticipation et de convolution. Il prend en entrée le spectrogramme log-mel du signal vocal et effectue un sous-échantillonnage convolutionnel, après quoi une série de blocs Conformer et une couche de projection sont appliqués pour obtenir les enregistrements finaux.
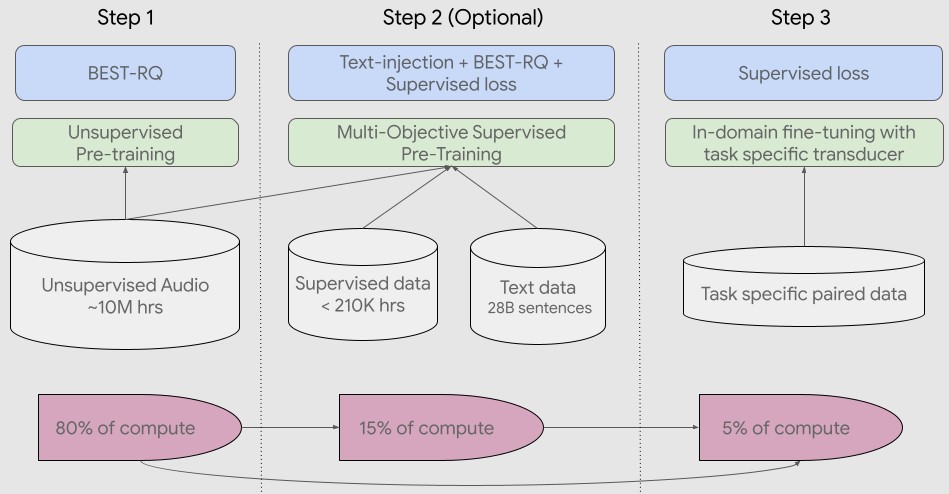
Le pipeline de formation commence par une première étape d'apprentissage auto-supervisé sur des enregistrements audio couvrant des centaines de langues. Lors de la deuxième étape facultative, la qualité du modèle et la couverture linguistique peuvent être améliorées grâce à une étape supplémentaire de pré-entraînement avec des données textuelles. La décision d'incorporer la deuxième étape dépend de la disponibilité des données textuelles. USM obtient les meilleurs résultats avec cette deuxième étape facultative. La dernière étape du pipeline de formation consiste à affiner les tâches en aval (par exemple, ASR ou traduction automatique de la parole) avec une petite quantité de données supervisées.
Pour la première étape, léquipe de Google utilise BEST-RQ, qui a déjà démontré des résultats de pointe sur des tâches multilingues et s'est avéré efficace lors de l'utilisation de très grandes quantités de données audio non supervisées.
Dans la deuxième étape (optionnelle), elle a utilisé un pré-entraînement supervisé multi-objectif pour incorporer des connaissances provenant de données textuelles supplémentaires. Le modèle introduit un module d'encodage supplémentaire pour prendre le texte en entrée et des couches supplémentaires pour combiner la sortie de l'encodage de la parole et de l'encodage du texte, et entraîne le modèle conjointement sur la parole non étiquetée, la parole étiquetée et les données textuelles.
Au cours de la dernière étape, l'USM est affiné pour les tâches en aval. L'ensemble de la chaîne de formation est illustré ci-dessous. Grâce aux connaissances acquises lors de la préformation, les modèles USM atteignent une bonne qualité avec seulement une petite quantité de données supervisées provenant des tâches en aval.
Principaux résultats
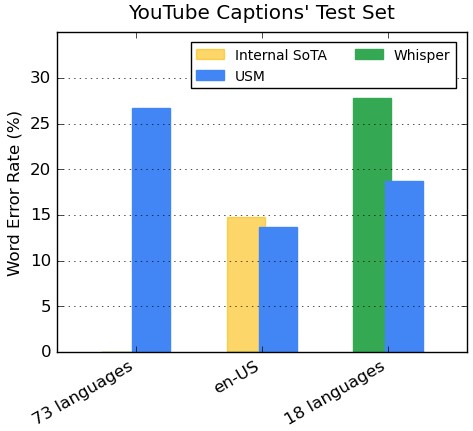
Performances dans plusieurs langues pour les légendes de YouTube
Lencodeur intègre plus de 300 langues grâce à un pré-entraînement. Google démontre l'efficacité de l'encodeur pré-entraîné par un réglage fin sur les données vocales multilingues de YouTube Caption. Les données supervisées de YouTube comprennent 73 langues et ont en moyenne moins de trois mille heures de données par langue.
Malgré des données supervisées limitées, le modèle atteint un taux d'erreur de mots (WER ; plus il est bas, mieux c'est) inférieur à 30 % en moyenne pour les 73 langues, une étape jamais atteinte auparavant. Pour en-US, USM a un WER relativement inférieur de 6 % par rapport au modèle interne de pointe actuel. Enfin, nous comparons avec le grand modèle récemment publié, Whisper (large-v2), qui a été entraîné avec plus de 400 000 heures de données étiquetées.
Pour la comparaison, Google n'utilise que les 18 langues que Whisper peut décoder avec succès avec un WER inférieur à 40 %. Notre modèle a, en moyenne, un WER de 32,7 % inférieur à celui de Whisper pour ces 18 langues.
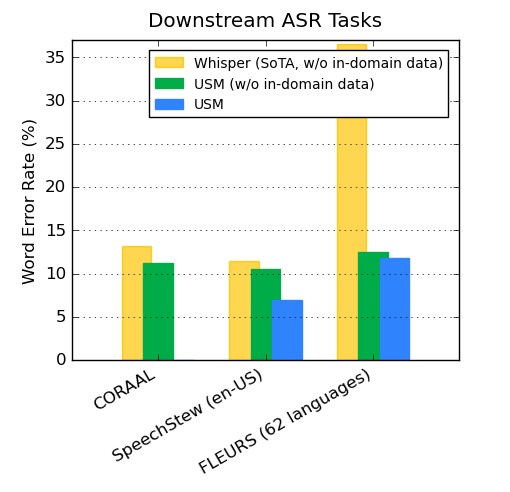
Généralisation aux tâches d'ASR en aval
Sur des ensembles de données accessibles au public, le modèle de Google présente un WER inférieur à celui de Whisper sur CORAAL (anglais vernaculaire afro-américain), SpeechStew (en-US) et FLEURS (102 langues). Il obtient un WER inférieur avec et sans entraînement sur les données du domaine. La comparaison avec FLEURS porte sur le sous-ensemble de langues (62) qui recoupe les langues prises en charge par le modèle Whisper. Pour FLEURS, USM sans données in-domain a un WER inférieur de 65,8 % par rapport à Whisper et a un WER inférieur de 67,8 % avec des données in-domain.
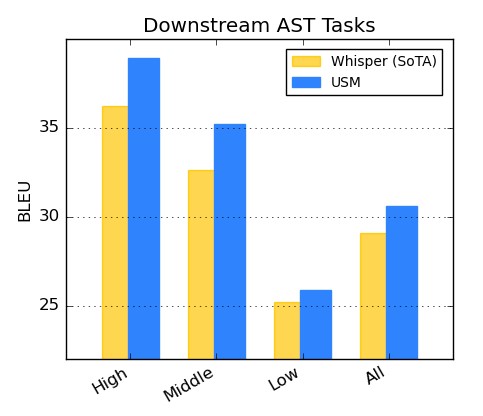
Performances en matière de traduction automatique de la parole (AST)
Pour la traduction vocale, Google a affiné USM sur l'ensemble de données CoVoST. Son modèle, qui inclut le texte via la deuxième étape du pipeline, atteint une qualité de pointe avec des données supervisées limitées. Pour évaluer l'étendue des performances du modèle, léquipe Google segmente les langues de l'ensemble de données CoVoST en trois catégories : élevée, moyenne et faible, en fonction de la disponibilité des ressources, et elle calcule le score BLEU (plus il est élevé, mieux c'est) pour chaque segment. Comme le montre le tableau ci-dessous, USM surpasse Whisper pour tous les segments.
Microsoft, le rival le plus prononcé de Google en matière dIA annonce la sortie imminente de GPT-4
L'intelligence artificielle et son application dans de multiples secteurs progressent à un rythme vertigineux compte tenu des opportunités infinies qu'elle offre aux entreprises de tous types et de tous secteurs. Jour après jour, nous assistons à l'émergence de nouveaux produits d'IA et d'apprentissage automatique sur le marché.
Google et Microsoft en course pour lavenir de lIA. Alors que Microsoft est fermement lié à OpenAI, le créateur de ChatGPT, Google pourrait s'être tourné vers une entreprise moins connue du nom d'Anthropic et fondée par d'anciens employés d'OpenAI. Microsoft, le rival le plus prononcé de Google en matière dIA annonce la sortie imminente de GPT-4. Andreas Braun, directeur technique de Microsoft Allemagne, a indiqué lors d'un événement de lancement de l'IA le 9 mars 2023 la sortie de GPT-4.
Selon Microsoft, l'Intelligence Artificielle Multimodale est un grand trésor à découvrir, car il existe très peu de solutions professionnelles sur le marché capables de travailler dans ce domaine technologique extrêmement innovant. Microsoft a publié son document de recherche, intitulé Language Is Not All You Need: Aligning Perception with Language Models. Le modèle présente un grand modèle de langage multimodal (MLLM) appelé Kosmos-1. L'article souligne l'importance d'intégrer le langage, l'action, la perception multimodale et la modélisation du monde pour progresser vers l'intelligence artificielle. La recherche explore Kosmos-1 dans différents contextes.
Les grands modèles de langage (LLM) ont servi avec succès d'interface polyvalente pour diverses tâches de langage naturel [BMR+20]. L'interface basée sur les LLM peut être adaptée à une tâche tant que nous sommes capables de transformer l'entrée et la sortie en textes. Par exemple, l'entrée du résumé est un document et la sortie est son résumé. Les chercheurs peuvent donc introduire le document d'entrée dans le modèle de langage, puis produire le résumé généré.
KOSMOS-1 est un grand modèle de langage multimodal (MLLM) qui peut percevoir des modalités générales, suivre des instructions (c.-à-d., apprentissage à zéro coup) et apprendre en contexte (c.-à-d., apprentissage à quelques coups). L'objectif est d'aligner la perception avec les MLLMs, de sorte que les modèles soient capables de voir et de parler. Pour être plus précis, nous suivons METALM [HSD+22] pour former le modèle KOSMOS-1 à partir de zéro.
Le modèle montre des capacités prometteuses sur diverses tâches de génération en percevant des modalités générales telles que le NLP sans OCR, l'AQ visuelle, et les tâches de perception et de vision. L'équipe de recherche de Microsoft a également présenté le modèle à un ensemble de données du test de QI de Raven pour analyser et diagnostiquer les possibilités de raisonnement non verbal des MLLM. « Les limites de ma langue signifient les limites de mon monde », Ludwig Wittgenstein.
« Nous présenterons le GPT-4 la semaine prochaine et nous aurons des modèles multimodaux qui offriront des possibilités complètement différentes, par exemple des vidéos », a déclaré Braun. Le directeur technique a qualifié les LLM de « changeurs de jeu », car ils apprennent aux machines à comprendre le langage naturel, ce qui leur permet de comprendre de manière statistique ce qui n'était auparavant lisible et compréhensible que par les humains. Entre-temps, la technologie a tellement progressé qu'elle « fonctionne dans toutes les langues » : Vous pouvez poser une question en allemand et obtenir une réponse en italien. Grâce à la multimodalité, Microsoft(-OpenAI) « rendra les modèles complets ».
Le géant de Mountain View a investi environ 300 millions de dollars dans la startup d'intelligence artificielle Anthropic, ce qui en fait le dernier géant de la technologie à mettre son argent et sa puissance de calcul au service d'une nouvelle génération d'entreprises qui tentent de se faire une place dans le domaine en plein essor de l'"IA générative".
En échange de cet investissement de 300 millions de dollars, Google aurait obtenu une participation de 10 % dans l'entreprise, et Anthropic serait tenu d'acheter des ressources de cloud computing à Google. Cette dynamique est quelque peu similaire au partenariat entre Microsoft et OpenAI. Dans ce dernier cas, OpenAI fournit l'expertise en matière de recherche, tandis que Microsoft fournit non seulement des milliards de dollars d'investissement, mais aussi l'accès à sa puissante technologie de cloud computing, nécessaire pour former les derniers modèles d'IA à forte intensité de calcul.
« Aujourd'hui, nous annonçons la troisième phase de notre partenariat à long terme avec OpenAI par le biais d'un investissement pluriannuel de plusieurs milliards de dollars visant à accélérer les percées de l'IA afin de garantir que ces avantages soient largement partagés avec le monde. Cet accord fait suite à nos précédents investissements en 2019 et 2021. Il étend notre collaboration en cours à travers le supercalculateur et la recherche en IA et permet à chacun d'entre nous de commercialiser indépendamment les technologies avancées d'IA qui en résultent », a déclaré Microsoft dans un billet de blog.
ChatGPT a pris le monde d'assaut depuis son lancement en novembre, avec son habileté à écrire des essais, des articles, des poèmes et du code informatique en quelques secondes seulement. Le PDG d'OpenAI, Sam Altman, a qualifié Google de « monopole de recherche léthargique » dans une interview. Il a entre autre déclaré qu'il voyait un énorme potentiel pour la technologie d'IA de sa société, qui pourrait transformer la façon dont les gens trouvent des informations en ligne.
ChatGPT est un robot à grand modèle de langage (ils permettent de prédire le mot suivant dans une série de mots) développé par OpenAI et basé sur GPT-3.5. Il a une capacité remarquable à interagir sous forme de dialogue conversationnel et à fournir des réponses qui peuvent sembler étonnamment humaines.
Source : Google
Et vous ?
Le de construction d'un modèle d'IA capable de comprendre les 1000 langues les plus parlées dans le monde est-il intéressant ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager