
















Voyager, le tout premier supercalculateur alimenté par les puces d'IA générique d'Intel,
il permettra aux scientifiques doptimiser des algorithmes pour les modèles d'apprentissage automatique
Les scientifiques du monde entier sont inondés de pétaoctets et d'exaoctets de données, qui ont le potentiel de débloquer des idées et des découvertes qui mènent à des percées dans le domaine de la santé, de la physique et de nombreuses autres sciences. Pour passer au crible et donner un sens à ces montagnes de données, les chercheurs se tournent vers l'intelligence artificielle (IA), l'apprentissage profond (DL) et l'apprentissage automatique (ML). Le San Diego Supercomputer Center (SDSC) serait prêt à exécuter des charges de travail de test sur son système expérimental dintelligence Artificiel qui semble être le tout premier superordinateur basé sur la technologie Habana (une société Intel).
La disponibilité d'un plus grand nombre de données dans tous les domaines scientifiques, sous l'impulsion de nouvelles sources d'acquisition, de modèles à plus haute résolution et de dépôts fédérés, donne lieu à des ensembles de données massifs et de plus en plus complexes. Pour trier et synthétiser ces données, les scientifiques appliquent l'IA, en particulier les techniques et algorithmes Deep Learning (DL), en utilisant de nouvelles méthodes de calcul spécialement conçues pour extraire des informations. Mais il y a encore beaucoup à apprendre sur la meilleure façon d'analyser ces ensembles de données massifs et complexes.
Selon Intel, un superordinateur axé sur l'IA, appelé Voyager, au San Diego Supercomputer Center, aidera les scientifiques du monde entier à découvrir et à développer de nouvelles méthodes pour appliquer l'IA à leurs domaines. Financé par la National Science Foundation (NSF) en tant que système expérimental, Voyager permettra aux scientifiques d'essayer de nouvelles approches et de concevoir, construire et optimiser des algorithmes pour la formation et l'inférence accélérées de modèles d'apprentissage automatique.
La deuxième génération d'accélérateurs d'intelligence artificielle (IA) Intel Habana avait déjà été annoncée mais, ce n'est que maintenant que le premier superordinateur d'intelligence artificielle a été achevé et peut être utilisé. Il aurait été construit sur la première génération de ces puces. Pour son superordinateur Voyager, le San Diego Supercomputing Center a choisi les accélérateurs de Habana Labs qui serait racheté par Intel.
Il s'agit en fait du premier système de sa catégorie à n'utiliser que des solutions IA Intel. Le supercalculateur a été construit en collaboration avec les Habana Labs d'Intel et Supermicro dans le cadre d'une subvention de 11,25 millions de dollars sur cinq ans accordée par la National Science Foundation. Bien qu'il soit puissant, Voyager n'a pas pour objectif de remporter des records de performance.
Voyager est destiné à servir de terrain d'essai pour la recherche et le développement de l'informatique AI/ML sur du matériel spécialisé - dans ce cas, les processeurs Goya et Gaudi de Habana, a déclaré Amit Majumdar, directeur de la division DESC (Data Enabled Scientific Computing) au SDSC.
Introduit en 2019, le Goya d'Habana Lab a été conçu pour accélérer les charges de travail d'inférence d'IA à l'aide de huit curs de processeur tensor avec prise en charge de la précision mixte de FP32 à UINT8. Pendant ce temps, Gaudi, introduit quelques mois plus tard, était une puce de 350W conçue avec un travail ML en tête. Elle est dotée de 32 Go de mémoire embarquée fonctionnant à une bande passante de 1 To/s.Intel a acquis le concepteur de la puce à la fin de 2019 après avoir abandonné sa collaboration avec Meta (alors Facebook) dans le cadre de Nervana. Les accélérateurs d'IA Habana sont déployés sur les 42 réseaux Supermicro X12 qui composent Voyager.
Chaque système X12 est équipé d'une paire de processeurs Xeon Scalable de troisième génération d'Intel et de huit processeurs Habana Gaudi AI. Le cluster utilise également une paire de systèmes SuperServer 4029GP-T de l'équipementier avec huit cartes PCIe Goya HL-100 pour l'inférence IA. Le système étant conçu pour prendre en charge de très grands modèles d'intelligence artificielle, chaque serveur est relié à un grand commutateur non bloquant Arista par six ports de 400 Gbit/sec fonctionnant selon le protocole RDMA-over-converged-Ethernet.
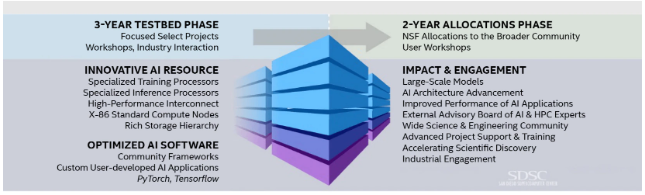
Le système Voyager étant opérationnel, le SDSC est passé à la phase de banc d'essai du projet. Au cours de cette période, le centre de supercalcul dispose de trois ans pour travailler directement avec les chercheurs afin de déterminer les performances du système, les particularités du matériel et les exigences en matière de compatibilité logicielle, a expliqué Majumdar. La recherche explorera également les cas d'utilisation des puces Habana, qui ont traditionnellement ciblé la vision par ordinateur, le traitement du langage naturel et les charges de travail d'apprentissage profond, a déclaré Sree Ganeson, responsable de la gestion des produits logiciels chez Habana Labs.
« Cette communauté de scientifiques et de chercheurs va apporter une classe différente de problèmes et essayer de les appliquer aussi à l'apprentissage profond, a-t-elle déclaré. Les types de modèles qu'ils peuvent apporter pourraient être différents, donc, ce sera un [processus] d'apprentissage ». Les résultats de ces tests seront partagés au cours des prochaines années lors d'ateliers semestriels et de forums d'utilisateurs.
Cependant, tout le monde n'aura pas l'occasion de travailler sur le système. Des groupes de recherche déterminés avec l'aide d'un conseil consultatif externe, et les informations recueillies seront utilisées pour développer les meilleures pratiques et les politiques d'allocation. Cette approche est différente de celle des systèmes de catégorie 1, qui sont ouverts aux projets de recherche évalués par les pairs peu après leur mise en ligne, a précisé Majumdar. Au terme des trois années, le projet passera à une phase d'allocation de deux ans au cours de laquelle l'équipe du SDSC prendra du recul et permettra à des scientifiques indépendants de mener des recherches sur le système.
Bien que Voyager ne soit en ligne que depuis peu, Majumdar affirme que les premiers tests sont prometteurs, les performances étant "meilleures que prévu" et les charges de travail pouvant être portées relativement facilement sur Gaudi et Goya. "La pile logicielle, le portage et l'exécution sur la machine se sont déroulés sans problème", a-t-il déclaré.
Gaudi est un processeur d'apprentissage de l'IA conçu dès le départ pour ses performances et son évolutivité. Gaudi accélère les principales charges de travail de formation en IA, notamment la classification d'images, la détection d'objets, le traitement du langage naturel, la synthèse vocale, l'analyse des sentiments, les systèmes de recommandation, etc. Avec huit curs de processeur Tensor (TPC) entièrement programmables, Gaudi constitue une option performante et rentable pour la formation à l'apprentissage profond.
L'apprentissage de l'IA consomme souvent un très grand nombre de nuds pendant des périodes prolongées. À une telle échelle, les accélérateurs Gaudi offrent une efficacité opérationnelle et de calcul de l'IA pour la formation de modèles DL, que ce soit sur site ou dans le cloud. Amazon Web Services les a ajoutés à ses instances EC2 pour offrir des alternatives moins coûteuses à ses instances GPU. Amazon Web Services s'attend à ce que ses instances équipées de processeurs Gaudi offrent un rapport prix/performance jusqu'à 40 % supérieur à celui de la génération actuelle d'offres GPU.1.
La taille et la complexité croissantes des ensembles de données, des réseaux neuronaux et de la charge de travail de l'IA, combinées à la demande accrue de précision de l'IA, font que les systèmes de formation nécessitent une capacité de calcul massive. Pour répondre à ce besoin, les systèmes doivent fournir une mise à l'échelle haute performance avec des communications efficaces entre les nuds.
Voici, ci-dessous, quelques caractéristiques de Habana Gaudi
- Efficacité : les processeurs d'apprentissage d'IA Habana offrent un avantage substantiel en termes de prix/performance - vous obtenez donc plus d'apprentissage profond, tout en dépensant moins pour vos déploiements sur site. Conçues dès le départ et optimisées pour l'efficacité de la formation en IA, les solutions de formation Gaudi permettent à un plus grand nombre de clients d'exécuter davantage de charges de travail de formation en apprentissage profond avec rapidité et performance, tout en maîtrisant les coûts opérationnels ;
- Facilité d'utilisation : Nous nous attachons à donner aux scientifiques des données, aux développeurs et aux administrateurs informatiques et systèmes tout ce dont ils ont besoin pour faciliter le développement et le déploiement des solutions Habana sur site. Notre plateforme logicielle SynapseAI® est optimisée pour la création et la mise en uvre de modèles d'apprentissage profond sur les processeurs Habana AI avec les frameworks TensorFlow et PyTorch et avec des modèles de vision par ordinateur et de traitement du langage naturel. Le site des développeurs Habana et Habana GitHub offrent un large éventail de contenus - documentation, scripts, vidéos pratiques, modèles de référence et outils - pour vous aider à démarrer et vous permettre de créer facilement de nouveaux modèles ou de migrer des modèles existants vers des systèmes basés sur Habana ;
- Évolutivité : à mesure que les ensembles de données augmentent en taille et en complexité, il est essentiel que les centres de données soient en mesure d'augmenter et de réduire facilement et de manière rentable leur capacité - certains systèmes nécessitant jusqu'à des centaines, voire des milliers de processeurs pour exécuter l'entraînement avec rapidité et précision. Les processeurs d'apprentissage de l'IA Habana Gaudi ont été conçus comme aucun autre - expressément pour répondre à la question de l'évolutivité - avec dix ports 100 Gigabit Ethernet de RDMA over Converged Ethernet (RoCE) intégrés dans chaque processeur Gaudi. Le résultat est une capacité de mise à l'échelle massive et flexible basée sur la norme de mise en réseau déjà utilisée dans pratiquement tous les centres de données.
Voyager est mis en ligne quelques semaines seulement après que Habana Labs d'Intel a dévoilé ses processeurs d'entraînement et d'inférence d'IA de deuxième génération : Gaudi2 et Greco. Intel affirme que ces puces offrent une augmentation substantielle des performances par rapport à la génération précédente et qu'elles dépasseraient les GPU A100 de Nvidia dans ses benchmarks internes.
Le Gaudi2 de 600 W offre 24 curs tenseurs basés sur un processus de fabrication de 7 nm et 96 Go de mémoire HBM2e à large bande passante fonctionnant à 2,45 To/s. Greco, quant à elle, offre 16 Go - la même chose que Goya - de LPDDR5 plus récente dans une carte PCIe plus petite à fente unique, mi-hauteur, mi-longueur, qui consomme moins de la moitié de l'énergie.
« Gaudi2 est plus grand à bien des égards, avec plus de curs de processeur tensor, plus de HBM2e, plus de ports scale-out, donc tout ce que nous avons appris de [Voyager] devrait s'adapter encore mieux à Gaudi2, a déclaré Ganeson. Le travail de pointe est effectué par cette communauté. Ainsi, nous pouvons apprendre et développer ce qui sera en production dans le futur. »
« Nous travaillons avec des scientifiques qui exécuteront à la fois la formation et l'inférence. Certains feront migrer leurs charges de travail construites sur d'autres technologies vers Voyager ; d'autres développeront leurs modèles directement sur Voyager. Ils devront également transférer leurs modèles de la formation à l'inférence, c'est pourquoi il est bon d'avoir les deux dans un seul système », a déclaré Amit Majumdar.
Pendant les trois premières années de Voyager, un petit groupe de scientifiques travaillera avec le système, en étroite collaboration avec les experts en applications du SDSC et du Habana. Certains feront migrer des charges de travail existantes et d'autres en développeront de nouvelles spécifiquement sur Voyager. Après trois ans de recherche, d'expérimentation, de développement et de partage de leurs résultats avec leurs communautés, Voyager sera disponible pour la recherche scientifique générale.
Source : Intel
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :

 Répondre avec citation
Répondre avec citation
Partager