











Atlassian accuse un script de maintenance d'avoir accidentellement désactivé plusieurs de ses services cloud pendant une semaine
et estime qu'il faudra deux semaines supplémentaires pour une restauration totale
Le développeur d'outils de développement de logiciels et de collaboration Atlassian accuse un récent script de maintenance d'avoir accidentellement désactivé plusieurs de ses services cloud, qui sont en panne depuis un peu plus d'une semaine :
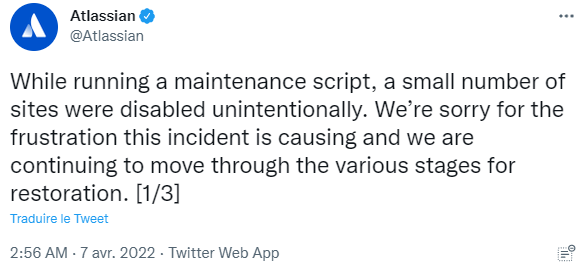
« Lors de l'exécution d'un script de maintenance, un petit nombre de sites ont été désactivés involontairement. Nous sommes désolés pour la frustration causée par cet incident et nous continuons à passer par les différentes étapes de restauration. C'est notre priorité absolue et nous avons mobilisé des centaines d'ingénieurs dans toute l'organisation pour travailler 24 heures sur 24 afin de remédier à l'incident. Pendant que nous nous efforçons de restaurer l'accès, vous pouvez compter sur nous pour continuer à fournir des mises à jour sur : http://status.atlassian.com. Vous pouvez continuer à nous contacter sur https://support.atlassian.com/contact pour toute question, préoccupation ou mise à jour. Si vous rencontrez des problèmes pour ouvrir un ticket d'assistance technique, veuillez ouvrir un ticket de question sur la facturation et nous le transférerons aux équipes d'assistance. Nous nous attendons à ce que la plupart des récupérations de sites se produisent avec une perte de données minimale ou nulle ».
Atlassian a d'abord reconnu la panne sur sa page d'état le 5 avril à 9h03 UTC.
Les services qui continuent d'être impactés incluent Jira Software, Jira Work Management, Jira Service Management, Confluence, Opsgenie Cloud (acquis en 2018), Statuspage et Atlassian Access. Confluence est un wiki d'entreprise basé sur le Web et Jira concerne davantage le suivi des problèmes. Jira Work Management est destiné à la gestion de projet générique tandis que Jira Service Management est apparu l'année dernière dans le cadre d'une vision visant à appliquer les principes agiles et DevOps au service desk informatique. L'ironie de l'effondrement de ce dernier en raison d'un problème avec un script de maintenance n'aura pas été perdue pour les utilisateurs concernés.
Concernant la liste des services Atlassian indisponibles, le service de surveillance des incidents informatiques, OpsGenie (acquis en 2018) et le service de communication des incidents Statuspage d'Atlassian n'auront pas manqué de faire tourner le compteur d'ironie sur les réseaux sociaux.
Atlassian a initialement estimé que ses efforts de restauration ne prendraient pas plus de quelques jours et a confirmé que l'incident n'était pas le résultat d'une cyberattaque qui aurait conduit à un accès non autorisé aux données.
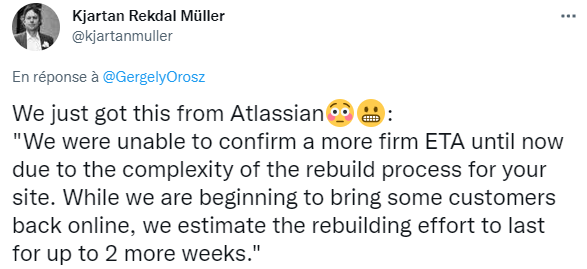
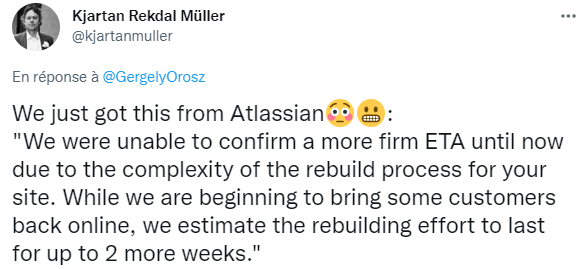
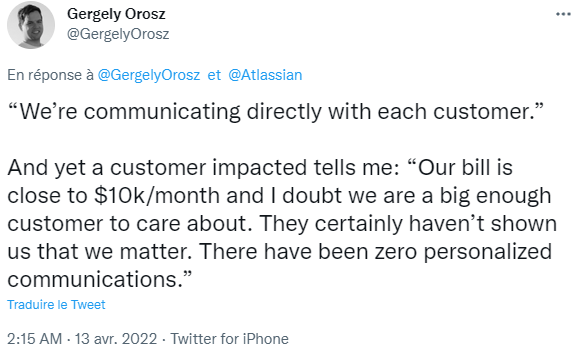
Cependant, dans les e-mails envoyés aux clients concernés, la société a révélé que la restauration des services aux personnes concernées prendra probablement jusqu'à deux semaines supplémentaires : « Nous n'avons pas été en mesure de confirmer un ETA plus ferme jusqu'à présent en raison de la complexité du processus de reconstruction de votre site. Alors que nous commençons à ramener certains clients en ligne, nous estimons que l'effort de reconstruction durera jusqu'à 2 semaines supplémentaires », a rapporté Kjartan Rekdal Müller, Team Lead chez NEP Mediaservices. Il indique que la structure pour laquelle il travaille a reçu ce message de la part d'Atlassian.
« Je sais que ce n'est pas la nouvelle que vous espériez. Nous nous excusons pour la durée et la gravité de cet incident et avons pris des mesures pour éviter qu'il ne se reproduise à l'avenir », a déclaré Atlassian à un autre client concerné.
Bien que l'impact sur les entreprises utilisant ses produits soit indéniable, Atlassian a déclaré vendredi qu'environ 400 de ses plus de 200 000 clients sont concernés.
La société affirme avoir été en mesure de restaurer les fonctionnalités de plus de 35 % de tous les utilisateurs directement touchés par cette panne en cours sans, apparemment, aucune perte de données :
« Un petit nombre de clients Atlassian continuent de subir des interruptions de service et ne peuvent pas accéder à leurs sites. Nos équipes mondiales d'ingénieurs travaillent 24h/24 et 7j/7 pour progresser sur la résolution de cet incident. À l'heure actuelle, nous avons reconstruit les fonctionnalités de plus de 35 % des utilisateurs touchés par la panne de service, sans aucune perte de données signalée. L'étape de reconstruction est particulièrement complexe en raison de plusieurs étapes nécessaires pour valider les sites et vérifier les données. Ces étapes nécessitent plus de temps, mais sont essentielles pour assurer l'intégrité des sites reconstruits. Nous nous excusons pour la durée et la gravité de cet incident et avons pris des mesures pour éviter qu'il ne se reproduise à l'avenir ».
Cette interruption des services cloud survient après que le cofondateur et co-PDG d'Atlassian, Scott Farquhar, a annoncé en octobre 2020 que la société ne vendrait plus de licences pour les produits sur site à partir de février 2021 et interromprait le support trois ans plus tard, le 2 février 2024.
« Le 2 février 2021, heure du Pacifique (PT), les modifications suivantes entreront en vigueur :
- fin des ventes de nouvelles licences de serveur : vous ne pouvez plus acheter ou demander un devis pour un nouveau produit de serveur ;
- mises à jour des prix des serveurs : nous mettrons en place de nouveaux prix pour les renouvellements et les mises à niveau des serveurs.
Le 2 février 2024 PT, le changement suivant entrera en vigueur :
- fin du support pour tous les produits serveur : cela signifie que le support et les corrections de bogues ne seront plus disponibles pour vos produits serveur.
« Pour faciliter une transition en douceur, nous offrirons trois ans de support et de maintenance pour vos produits de serveur et fournirons des remises de fidélité aux clients éligibles pour passer à nos produits cloud ou Data Center à un prix inférieur. Pour ceux qui sont prêts à explorer le cloud, nous avons créé le programme de migration Atlassian (AMP) qui vous fournit des guides étape par étape, des outils de migration gratuits, une équipe d'assistance dédiée à la migration et un essai gratuit de migration vers le cloud pour la durée de votre maintenance restante du serveur jusqu'à 12 mois(...).
« Même avec trois ans pour se préparer à ces changements, nous comprenons que tous les clients ne seront pas prêts à passer de nos produits serveur à nos produits cloud. Et certains d'entre vous ont des exigences commerciales qui pourraient vous empêcher d'opérer dans le cloud.
« Pour ces clients, nous continuerons à proposer notre édition d'entreprise robuste et autogérée, Atlassian Data Center. Cela comprendra de nouvelles fonctionnalités et intégrations qui faciliteront l'utilisation conjointe de nos produits cloud et de centre de données, comme l'unification de l'expérience d'administration pour des domaines tels que la gestion des utilisateurs.
« Nous renforçons également Atlassian Data Center en rendant certaines de nos applications les plus puissantes disponibles en mode natif et en proposant une assistance prioritaire avec des abonnements Data Center pour la plupart des niveaux d'utilisateurs. Pour soutenir cette innovation continue, nous mettrons à jour le prix des abonnements au centre de données le 2 février 2021 PT ».
Sources : Atlassian (1, 2, 3, 4)
Et vous ?
Êtes-vous concernés par cette panne ?
Voir aussi :

 Répondre avec citation
Répondre avec citation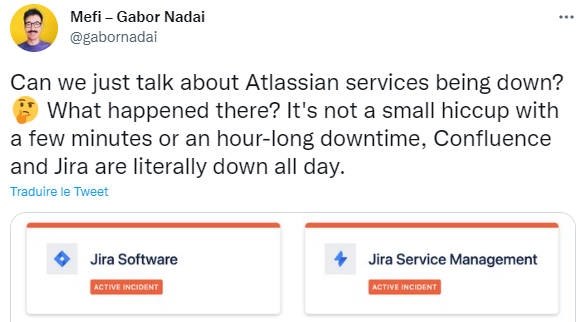









Partager