












Le langage Julia serait-il plus rapide que Fortran et plus propre que NumPy ?
Oui, selon Martin Maas, un développeur
En dehors de Rust, Julia est l'autre langage de programmation qui a fait l'objet d'une grande publicité au cours de la dernière décennie. Destiné au calcul scientifique, il est le langage plébiscité pour remplacer Python, R et Fortran dans le domaine de la science des données. Dans une comparaison qu'il a faite dernièrement, Martin Maas, mathématicien et informaticien, a déclaré que Julia est plus rapide que Fortran et plus propre que NumPy (Python). Il estime que NumPy est limité au "mono-threading" dans de nombreux cas, est difficile à coder et à lire, et peut être beaucoup plus lent que Python et Fortran.
Julia est un langage de programmation multiparadigme (entièrement impératif, partiellement fonctionnel et partiellement orienté objet) conçu pour le calcul scientifique. Il offre des gains de performance significatifs par rapport à Python (lorsqu'il est utilisé sans optimisation et calcul vectoriel en utilisant Cython et NumPy). Avec Julia, le temps de développement serait réduit d'un facteur 2 en moyenne. Les gains de performance seraient de l'ordre de 10 à 30 fois par rapport à Python (R serait encore plus lent. Les analystes estiment que le langage R n'a pas été construit pour la vitesse).
Des rapports de l'industrie en 2016 indiquaient que Julia est un langage à fort potentiel et peut-être la chance de devenir la meilleure option pour la science des données s'il recevait un plaidoyer et une adoption par la communauté. La version 1.0 de Julia est sortie en août 2018 et il a le plaidoyer de la communauté de programmation et l'adoption par un certain nombre d'entreprises comme le langage préféré pour de nombreux domaines y compris la science des données. En mars, la DARPA l'a choisi pour créer un framework devant permettre de multiplier par 1000 la vitesse de la simulation électronique.
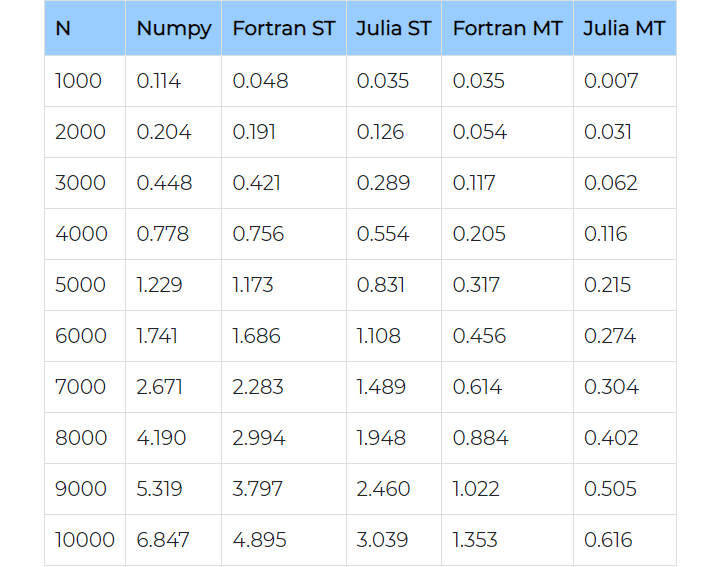
(ST : single-threaded ; MT : multi-threaded)
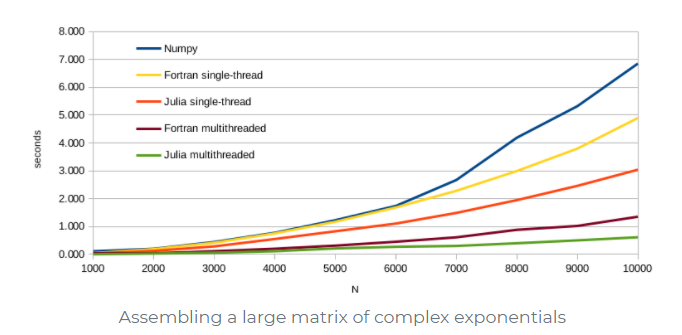
Alors, est-il réellement meilleur que ces concurrents ? Après avoir réalisé quelques benchmarks sur Fortran, NumPy et Julia, Maas a déclaré que Julia était largement supérieur à ces deux outils et qu'il adoptait désormais Julia. Notons que NumPy (Numerical Python) est une bibliothèque Python utilisée pour travailler avec des tableaux. Elle dispose en outre de fonctions permettant de travailler sur l'algèbre linéaire, la transformation de Fourier et les matrices. NumPy a été créé en 2005 par Travis Oliphant. Il s'agit d'un projet open source et vous pouvez l'utiliser librement. Voici ci-dessous les résultats de ces tests.
Julia vs Fortran vs Numpy : la vitesse et la clarté du code
Julia est un langage assez nouveau, qui, entre autres choses, vise à résoudre le soi-disant "problème de ces deux langages" dans le calcul scientifique. En effet, Maas estime que les développeurs testent habituellement des idées dans un langage de prototypage rapide comme Matlab ou Python, mais lorsque les tests sont terminés et qu'il est temps d'effectuer des calculs sérieux, ils doivent utiliser un autre langage de programmation (compilé). « De nombreux outils existent pour faciliter la transition, et l'intégration de bibliothèques Fortran dans Python a été ma préférence jusqu'à présent », a-t-il déclaré.
« Par exemple, envelopper un peu de Fortran avec F2PY semble être un moyen très pratique d'utiliser (et de distribuer) un code Fortran efficace que tout le monde peut exécuter. Je garde également une trace des différentes façons d'utiliser Fortran en Python dans ce post. Maintenant, Julia vise à résoudre ce problème d'une manière radicale. L'idée est d'utiliser un seul langage de programmation, qui a à la fois un mode interactif, adapté au prototypage rapide, mais qui peut aussi être compilé et exécuté à la performance C/Fortran », a ajouté le mathématicien.
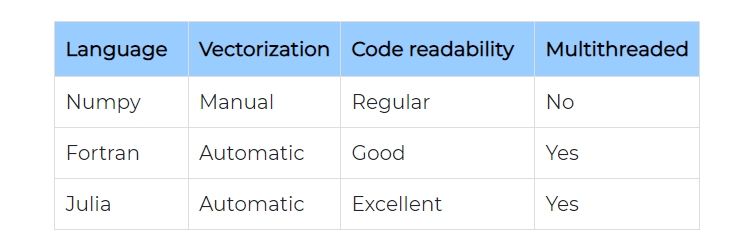
Selon Maas, Numpy serait limité au "mono-threading" dans de nombreux cas, difficile à coder et à lire et plus lent que ces alternatives. En outre, Fortran offrirait d'excellentes performances avec un code assez simple, mais certains habillages seraient nécessaires pour appeler Fortran à partir de langages de haut niveau comme Python. Enfin, Julia serait plus rapide et plus facile à écrire que Numpy et serait même capable de battre les performances de GFortran (compilateur GNU Fortran).
Lisibilité du code : l'impact de la vectorisation manuelle
Ici, Maas a d'abord déclaré que les opinions sur la lisibilité du code sont, bien sûr, subjectives, avant d'expliquer pourquoi il pense que Numpy offre la pire expérience en matière de qualité. Selon lui, jusqu'à présent, les langages interprétés ont nécessité une réécriture manuelle des boucles lors des opérations vectorielles. Avec un peu de pratique, cela devient peut-être une tâche facile, mais, selon Maas, la vectorisation manuelle du code serait une mauvaise pratique. « Je préfère écrire des boucles for et laisser le compilateur les vectoriser pour moi », a déclaré Mass. Considérez le code Numpy suivant, par exemple.
Selon Maas, à première vue, vous ne pourrez pas deviner ce que ce code fait ni raisonner sur les performances du code. En outre, il vous sera également difficile de deviner la dimension de la sortie de M. Voici ci-dessus le même code réécrit avec Julia.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Les deux extraits de code ci-dessus représentent la formule mathématique suivante : M_{ij} = e^{i k \sqrt{a_i^2 + a_j^2}}.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8do j=1,n do i=1,n M(i,j) = exp( (0,1)*k * sqrt(a(i)**2 + a(j)**2) ) end do end do
Selon Mass, il n'est pas étonnant qu'ils [les développeurs du langage] aient appelé Fortran "FORmula TRANslator" en premier lieu. Maas estime qu'il est intéressant de noter que la syntaxe de Julia est exactement similaire à cet égard. « Donc, même si je suis d'accord avec l'idée que Python est un beau langage pour travailler, je ne pense pas qu'il en soit de même pour Numpy. Oui, Numpy nous permet de rester dans un framework Python et de faire des choses avec de simples one-liners [uniligne un paradigme informatique], mais le code Numpy qui en résulte devient difficile à lire par la suite », a-t-il déclaré.
Autres comparaisons entre Python et Julia
Julia possède plusieurs fonctionnalités et ressources avantageuses pour l'apprentissage automatique et la science des données. Il a été conçu en mettant l'accent sur le calcul numérique et scientifique. La syntaxe conviviale de Julia en fait un langage idéal pour les utilisateurs de Matlab, Octave, Mathematica, R, entre autres langages et environnements informatiques. Avec ses propres bibliothèques natives d'apprentissage automatique, Julia devrait attirer davantage d'experts en science des données à l'avenir. Un exemple d'une telle bibliothèque est Flux, et elle est composée de plusieurs modèles idéaux pour des cas d'utilisation standard.
Elle offre un support solide pour l'interopérabilité avec d'autres paquets Julia. Flux est entièrement écrit en Julia, ce qui signifie que les utilisateurs peuvent y apporter des modifications. En revanche, Python est un langage polyvalent. Bien qu'il n'ait pas été conçu spécifiquement pour la science des données, Python offre de nombreux avantages aux spécialistes de l'apprentissage automatique et des données. Les spécialistes de l'apprentissage automatique et les scientifiques des données utilisent Python, par exemple, pour l'analyse des émotions et le traitement du langage naturel (NLP).
En effet, les bibliothèques Python offrent un moyen pratique d'écrire des algorithmes très performants. Python existe depuis environ 30 ans, au cours desquels il a établi des relations solides avec de nombreux paquets tiers. Cela a attiré de nombreux utilisateurs. Toutefois, l'un des inconvénients associés à Python est la vitesse. Python met en uvre de grandes améliorations, notamment au niveau de l'interpréteur Python. Le nouvel interpréteur PyPy v7.1 est rapide et fiable. Les progrès réalisés dans le domaine du traitement parallèle et multicur devraient permettre d'accélérer Python.
Python vs Julia : l'apprentissage automatique
Python est utilisé pour un large éventail de tâches. Julia, en revanche, est principalement développé pour effectuer des tâches d'apprentissage automatique et de statistique. Parce que Julia a été explicitement conçu pour le travail statistique de haut niveau, il a plusieurs avantages sur Python. En algèbre linéaire, par exemple, Julia Vanilla montrerait de meilleures performances que Python Vanilla. Ceci serait principalement dû au fait que, contrairement à Julia, Python ne supporte pas toutes les équations et matrices réalisées en apprentissage automatique.
Alors que Python est un excellent langage, en particulier avec NumPy, Julia serait supérieur à lui lorsqu'il s'agit de l'expérience non packagée, Julia étant plus adapté aux calculs d'apprentissage automatique. Le système d'opérandes de Julia serait seulement comparable à celui de R. En outre, Python serait un peu plus faible en ce qui concerne les performances, et serait un gros revers.
Les performances en matière de vitesse
Selon des analystes, les développeurs de Julia ont voulu créer un langage de programmation rapide. La vitesse de Julia serait égale à celle des langages compilés comme Fortran et C. Parce que ce n'est pas un langage interprété, Julia s'appuie sur les déclarations de type dans l'exécution des programmes impliquant une compilation au moment de l'exécution. Avec Julia, un développeur bénéficierait d'une grande vitesse sans nécessairement appliquer des techniques artisanales de profilage et d'optimisation. Cela ferait de Julia une solution aux problèmes de performance.
Il serait rapide d'exécuter des programmes avec Julia compte tenu de ses fonctions numériques et de calcul complexes. De plus, il serait développé avec une fonction de distribution multiple pour assurer une définition rapide des types de données tels que les tableaux et les nombres. Par rapport à Python, des tests montrent que Julia est plus rapide. Cependant, les développeurs de Python s'efforcent d'améliorer la vitesse de Python. Certains des développements qui peuvent rendre Python plus rapide sont les outils d'optimisation, les compilateurs JIT tiers et les bibliothèques externes.
Utilisation en science des données
Python est utilisé pour effectuer de nombreuses tâches, dont les plus importantes sont l'analyse de données. L'une des raisons pour lesquelles Python est un outil privilégié en science des données est son écosystème favorable comprenant des applications, des outils et des bibliothèques qui rendent l'analyse de données et le calcul pratiques et rapides. Le langage Julia est né avec à l'esprit la demande croissante d'analyse de données et la nécessité de disposer d'un meilleur langage de programmation pour effectuer ces tâches.
Selon les analystes, les développeurs de Julia ont concentré leur attention sur la création d'un langage dédié au calcul scientifique, à l'algèbre linéaire à grande échelle, à l'apprentissage automatique, au calcul parallèle et distribué. Julia aurait amélioré la vitesse de Python et aurait offert aux scientifiques des données la possibilité d'effectuer des calculs et des analyses en toute simplicité.
Polyvalence des deux langages
Avec Julia, les experts en sciences des données peuvent écrire des projets à partir d'autres langages et les compiler en envoyant des chaînes de caractères. Cela se produit parce que Julia est un langage de programmation polyvalent avec un code universellement exécutable en LaTeX, C, Python et R. En outre, il faudrait moins de temps pour exécuter des bouts de code complexes et importants en Julia qu'en Python. RCall et PyCall seraient très importants, étant donné que Julia est désavantagée en matière de paquets. Ainsi, vous pourrez faire appel à R et Python lorsque le besoin s'en fera sentir.
Il est important de noter que Python est un outil fiable pour le développement Web, l'automatisation et les scripts. Ainsi, pour un langage polyvalent, Python est la meilleure option.
Outillage et soutien communautaire
Tout langage de programmation nécessite un soutien en matière d'outils. Au fil des ans, les utilisateurs de Python ont bénéficié d'une communauté de programmation active et solidaire, avec un support d'outils amélioré, des interfaces et des systèmes construits par cette communauté. En revanche, le support pour Julia est encore jeune. Dans son cas, le support pour des ressources importantes et des outils de débogage est minimal. Le soutien de la communauté est tout aussi important pour un langage de programmation. Considérant que Julia est un langage relativement nouveau, la taille de sa communauté est également petite.
Il est intéressant de noter que cette communauté est très enthousiaste et s'agrandit de jour en jour. Python existe depuis des décennies, et au cours de cette période, un important soutien communautaire s'est progressivement développé. Cette grande communauté signifie des solutions adéquates aux problèmes majeurs et de multiples ressources pour répondre aux besoins des développeurs.
Conclusion
Python, un langage bien établi, est très important pour les domaines de la science des données et de l'apprentissage automatique. Bien que Julia soit relativement nouveau, avec moins de communauté et de support d'outils, il présente de nombreux avantages par rapport à Python. Julia a été développé pour surmonter les problèmes de vitesse. Sa familiarité avec C, R, Python et l'environnement de répartition multiple est un atout supplémentaire.
Source : Martin Maas
Et vous ?
Que pensez-vous des arguments avancés par Martin Maas ? Êtes-vous de son avis ou pas ? Pourquoi ?
Voir aussi
 Répondre avec citation
Répondre avec citation











Partager