












Dolt, une base de données SQL avec des fonctions de contrôle de version, qui peut être forké, cloné, dérivé, fusionné
et DoltHub, un site Web qui héberge les bases de données Dolt, décrit comme un Git pour les bases de données
Dans le monde technologique d'aujourd'hui, les données jouent un grand rôle. Si la façon dont elles sont recueillies, traitées et stockées est importante pour les organisations, la disponibilité de ces données et leur distribution le sont tout autant. Dans le but de permettre une disponibilité et une distribution qui répondent aux exigences actuelles du secteur IT, Tim Sehn, ingénieur des bases données, et son équipe proposent Dolt et DoltHub. Dolt est une base de données relationnelle à version contrôlée et DoltHub est un site qui héberge les bases de données Dolt, en fournissant des outils pour interagir avec ces dernières.
Les données ont changé, les bases de données, par contre, non
Alors, pourquoi Dolt ? Selon l'équipe, les bases de données relationnelles existantes ont été construites à une autre époque de l'informatique. Leur objectif était de saisir l'état de l'application et de la servir de manière performante. Ces bases de données géraient les données "CRUD", c'est-à-dire les opérations de création, de lecture, de mise à jour et de suppression des données, déclenchées par les interactions humaines avec l'application. Mais d'après l'équipe, cela a changé. Désormais, des pipelines automatisés alimentent directement les données dans les processus opérationnels activés par les logiciels.
Des exemples d'applications souvent alimentées par des pipelines de données, ou tout au moins qui nécessitent des ensembles de données d'entrée, seraient : les modèles d'apprentissage automatique utilisés pour prendre des décisions en temps réel, la recherche médicale dans laquelle des sources de données extérieures sont utilisées comme intrants pour les modèles cliniques, les algorithmes de négociation calibrés sur les observations du marché, etc. L'équipe estime que les données en sont venues à ressembler beaucoup plus à une dépendance de production, mais les bases de données classiques ne reflètent pas cette réalité.
Selon elle, dans le cas des applications qui nécessitent des ensembles de données d'entrée, il y a la possibilité d'une défaillance causée par les données. Il s'agirait là d'un risque qu'une base de données à version contrôlée permet d'éviter. Ainsi, elle décrit Dolt comme étant une base de données qui comprend des fonctions de contrôle de version afin que les utilisateurs puissent créer des flux de travail qui réduisent la possibilité que les données provoquent une défaillance du logiciel tout en rendant la récupération plus rapide. L'équipe justifie le choix du langage SQL par le fait qu'il est le langage de description et d'interrogation de données le plus largement adopté.
Dolt implémente un surensemble de MySQL. Il serait compatible avec MySQL et fournit des constructions supplémentaires exposant les fonctionnalités de contrôle de version qui sont étroitement modelées sur Git. « Dolt est le véritable Git pour l'expérience des données dans une base de données SQL, fournissant un contrôle de version pour les schémas et les données au niveau des cellules, le tout optimisé pour la collaboration », explique l'équipe. Selon elle, ces fonctionnalités sont combinées (Git + MySQL) pour créer un nouveau type de base de données relationnelle puissante et idéale pour le paysage des données évoluées.
Dolt est un outil libre et open source, sous licence Apache 2.0. Par ailleurs, DoltHub est un site Web qui héberge les bases de données Dolt, tout en fournissant des outils tels que l'hébergement, les autorisations, l'interface de requête, et plus encore, pour faciliter une collaboration transparente sur les données.
Ajout de fonctions de contrôle de version à une base de données SQL
Selon l'équipe, Dolt ajoute les fonctions de contrôle de version suivantes à une base de données SQL familière :
Lignage
L'équipe de Dolt estime qu'il permet de construire facilement de puissants pipelines de données reproductibles avec des capacités de lignage complètes. Selon elle, la première étape du suivi de la lignée est la reproductibilité. Lorsque les données d'entrée d'un processus proviennent de Dolt, le processus peut être reproduit à tout moment en utilisant l'état exact de la base de données associée à l'exécution originale. Cela rendrait les problèmes de données beaucoup plus faciles à découvrir. Lorsque la sortie d'un processus est écrite sur Dolt, il serait trivial de différencier les sorties d'un cycle à l'autre.
L'équipe estime que ces capacités permettent aux utilisateurs de tester et de déployer plus facilement des pipelines de données et d'isoler les sources de changement entre les données d'entrée et le code. En outre, l'équipe ajoute que, lorsque des processus reproductibles sont combinés dans une séquence d'étapes, il est possible de retracer la lignée complète d'un résultat. Les résultats peuvent être mis à jour selon que les ensembles de données en amont ont été mis à jour sans qu'il soit nécessaire de mettre en place une infrastructure de sondage ou de détection.
Voyage dans le temps
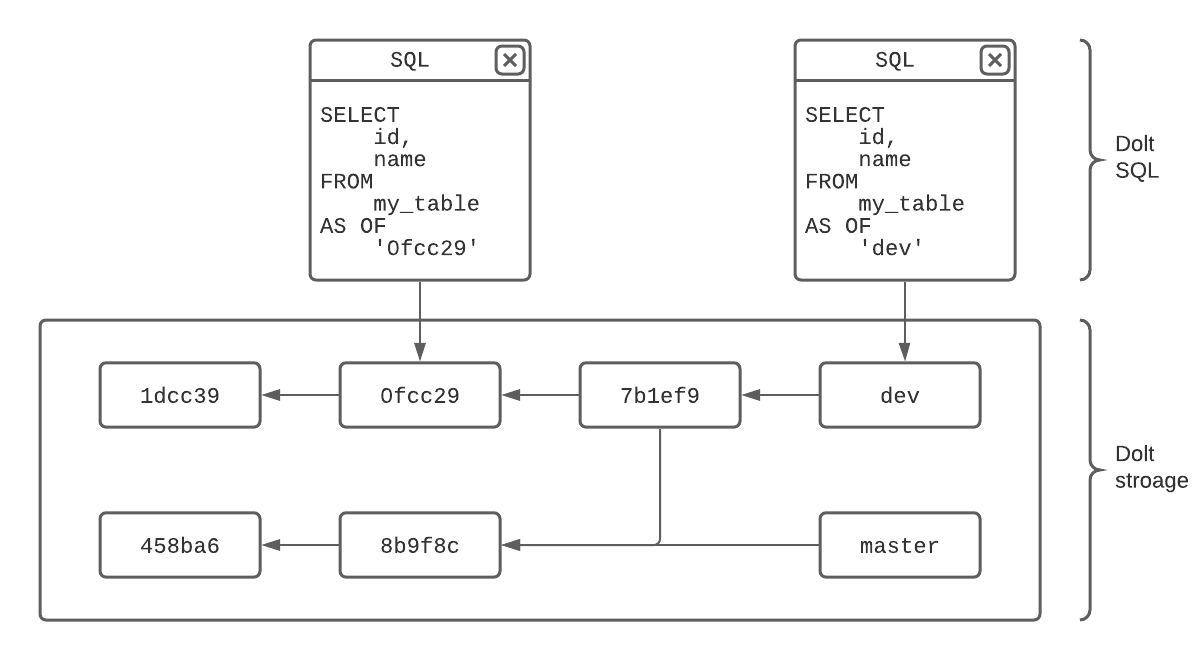
Selon la documentation, la couche de stockage des graphes de commit de Dolt modélise chaque état engagé de la base de données en tant que commit, ainsi que les métadonnées associées. L'historique complet du commit peut être interrogé en SQL. La possibilité d'interroger n'importe quel état de la base de données signifie que les valeurs deviennent implicitement des séries chronologiques.
Si les résultats d'une exécution de modèle sont présentés dans une table, l'équipe estime que vous pouvez facilement suivre les valeurs que ces résultats prennent au fil du temps. Tous les états sont associés à un objet commit, qui stocke les métadonnées.
Collaboration
L'équipe de développement de Dolt a déclaré à ce stade que l'une des principales inspirations pour la construction de Dolt a été la friction associée à la distribution et à la collaboration sur les ensembles de données. Selon cette dernière, les organisations qui utilisent des bases de données relationnelles existantes et qui souhaitent partager des données, librement ou commercialement, doivent extraire ces données de leur(s) base(s) de données interne(s). Elles doivent ensuite choisir d'héberger les données quelque part dans un format consommable.
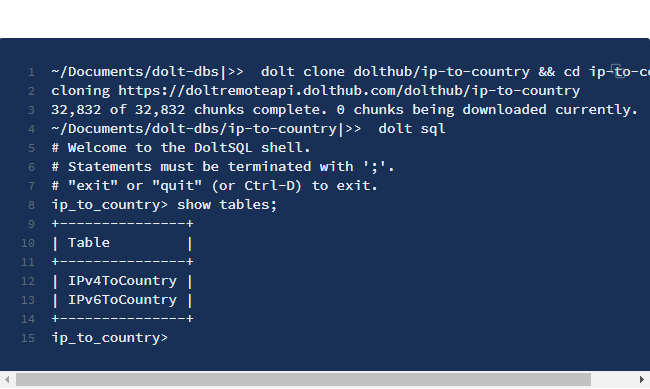
Par exemple, une organisation peut transférer chaque table d'une base de données qu'elle souhaite partager dans une collection de CSV, et les héberger sur un site de téléchargement. Les consommateurs de ces données doivent assembler les données dans l'interface d'interrogation qu'ils utilisent. Cependant, dans son cas, Dolt fait les choses différemment. Dolt prend en charge les commandes de type Git, et les utilisateurs peuvent acquérir et mettre à jour des données par de simples opérations de clonage et d'extraction.
Les bases de données Dolt se partagent comme une base de données standard. Le schéma, la saisie, ainsi que l'historique sont préservés. L'équipe estime que Dolt élimine le travail ETL (Extract, Transform, Load) en réduisant le besoin de nettoyage et de transformation des données. Les tables arrivent prêtes à être interrogées. Selon l'équipe, les scientifiques et les analystes de données se préoccupent, par exemple, de la réalité des données, et non de leur mise en place et de leur nettoyage.
Enfin, la documentation renseigne que Dolt a un soutien natif pour la collaboration à double sens inspirée par Git. Les utilisateurs peuvent créer une nouvelle branche et pousser les changements suggérés aux distributeurs et collaborateurs, sous réserve des autorisations appropriées.
Sources : Page GitHub de Dolt, Dolthub
Et vous ?
Que pensez-vous de Dolt et de DoltHub ?
Voir aussi

 Répondre avec citation
Répondre avec citation
Partager