














Bonjour à toutes et à tous
J'ai fait un benchmark pour comparer deux politiques pour un algorithme : "identity" et "truncate" (y'en a à qui ça évoquera quelque chose)
J'ai utilisé std::chrono::high_resolution_clock pour mesurer le temps mis par chaque stratégie.
J'ai ré-échantillonné 10000 fois le temps d'exécution pour chaque stratégie.
Comme je benchmark pour différents jeux de variables d'entrée des algos, j'ai commencé par regarder seulement les moyennes des temps d'exécution. Mais après coup j'ai quand même voulu jeter un coup d'oeil aux distributions sous-jacentes.
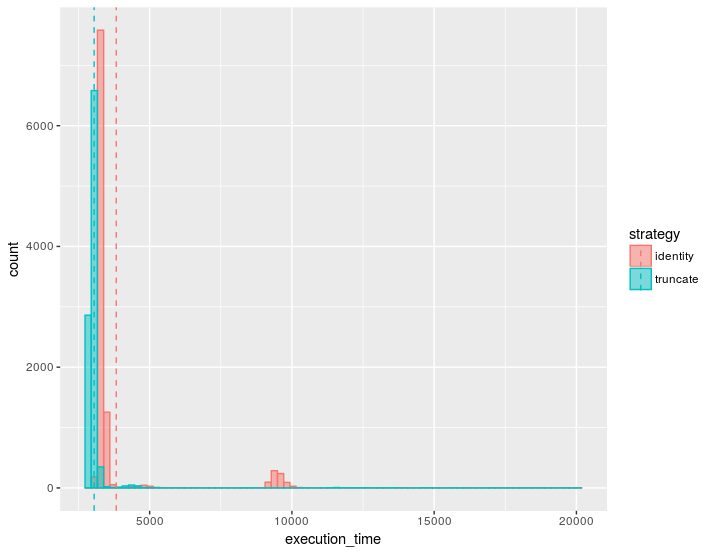
Bizarrement, il y a souvent des distributions bi-modales qui apparaissent, et ça me plaît pas trop. Par exemple, sur la figure suivante, la stratégie rose va être sur-pénalisée si on ne compare les stratégies que sur le critère de la moyenne (traits verticaux).
Je ne sais pas trop d'où ces artefacts peuvent venir (pour un même jeu de variables d'entrée de l'algorithme ils peuvent ou pas apparaître, mais certains paramétrages ont l'air d'être plus susceptibles à ce genre d'incidents).
J'ai lu par ailleurs qu'on est censé benchmarker dans des conditions "optimales" (pas de programmes de fond, pas de GUI ... ). Evidemment, ce n'est pas ce que j'ai fait, pensez-vous.Pensez-vous que le problème puisse venir de là ?
Si ça vient de là, est-ce qu'il vaut mieux prendre le temps de se placer dans ces conditions optimales (Ubuntu sans GUI ? seriously ?) ou bien peut on s'intéresser plutôt au temps CPU (même si j'avais lu qu'il vaut généralement mieux utiliser le temps système, le programme n'est pas multithreadé donc j'imagine qu'on ne prend pas beaucoup de risques ? ).
Est-il de coutume de s'encombrer de ce genre de considérations (ou j'en fais trop) ?
merci à vous")
 Répondre avec citation
Répondre avec citation












Partager