







Bonjour,
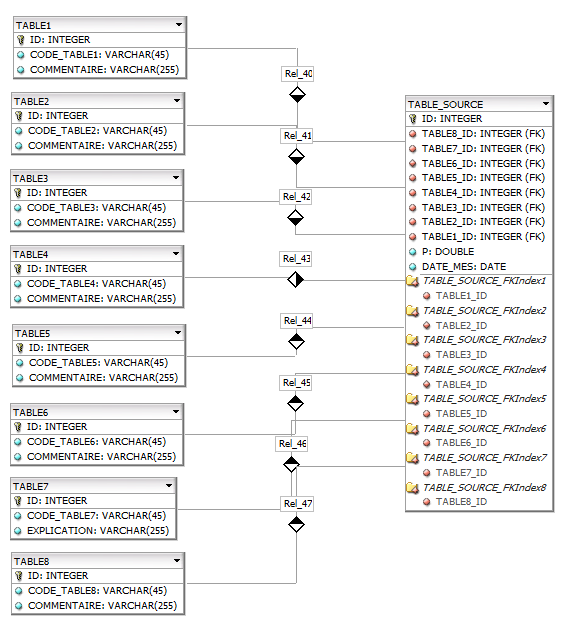
Pour mon premier projet SQL, je dois migrer une base de données DBF en base Firebird 3 sous Delphi. J'ai récupéré la modélisation faîtes sous DBF, certaines tables sont identiques (cf. image ci-dessous) et je pense qu'il doit exister une méthode pour regrouper et optimiser l'ensemble sous FB. Est-ce que je peux externaliser chaque champ code_table et commentaire de toutes les tables ? Si oui, comment représenter l'ensemble ? Comment optimiser les requêtes ?
Merci pour vos conseils
 Répondre avec citation
Répondre avec citation
















Partager