







Bonsoir,
sous 2008 R2 je rencontre le problème suivant, une requête qui mettait une minute à tourner en met maintenant 20 depuis que nous avons épuré les tables de la base (suppression d'enregistrements historisés dans une autre base par ailleurs). Je fait les essais sur la même machine, avec deux bases (une avant/après épuration).
Après recherches j'ai procédé à une réindexation de la base et à une mise à jour des statistiques, mais rien n'y fait.
Je suis à court d'idées, merci par avance pour votre aide.
Edit : je me rends compte que j'ai posté ça par erreur dans la partie développement je voulais poster dans administration
 Répondre avec citation
Répondre avec citation















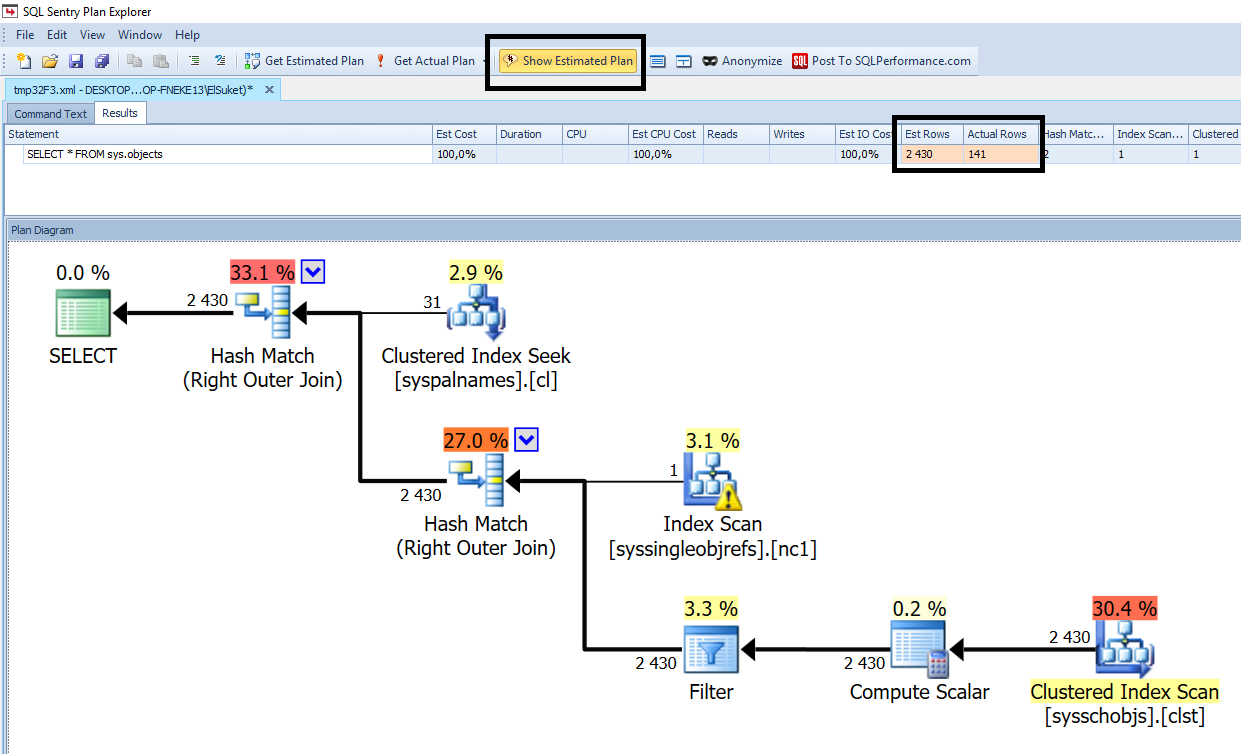
 ) représentaient 40% des enregistrements d'une table au lieu de 5% avant.
) représentaient 40% des enregistrements d'une table au lieu de 5% avant. 
Partager