





















La mode actuelle, en informatique de haute performance, est de viser des processeurs plus spécifiques pour réaliser des tâches particulières très vite et sans consommer trop dénergie. Par exemple, les cartes graphiques ne sont que des processeurs spécialisés dans certains traitements en parallèle. Plus récemment, les cryptomonnaies ont pu bénéficier de puces qui implémentent spécifiquement les instructions requises et rien dautre ou encore lapprentissage profond, notamment avec les TPU de Google. On y pense moins, mais le décodage du son est toujours effectué par des circuits dédiés (DSP pour le traitement du signal, si ce ne sont pas les codecs eux-mêmes qui sont réalisés en dur). À chaque fois, ces accélérateurs ont permis des gains énormes par rapport à des processeurs généralistes.
Cependant, on ne doit pas trop espérer de gains infinis avec cette technique de déplacer du logiciel vers du matériel : in fine, les accélérateurs aussi sont des processeurs. Ainsi, si la densité de transistors naugmente pas, ils finiront aussi par atteindre leurs limites. Lamélioration de performance est donc toujours limitée par la technologie, la loi de Moore.
Pour quantifier ce fait, des chercheurs ont analysé les données de milliers de puces accélératrices, pour analyser leur amélioration de performance génération après génération. Ils ont notamment cherché à distinguer la partie due uniquement aux algorithmes implémentés en matériel de celle qui vient de lamélioration des processus de fabrication. Ils en sont arrivés à définir une quantité adimensionnelle, le rendement de spécialisation : ce nombre indique à quel point les capacités des puces saméliorent indépendamment des transistors disponibles.
Ils ont alors détaillé des puces utilisées pour le décodage de vidéos, le minage de cryptomonnaies, le rendu de jeux vidéo ou lapplication de réseaux neuronaux convolutifs. Leur conclusion est sans appel : les améliorations de performance dépendent énormément du nombre de transistors disponibles, les progrès architecturaux sont largement inférieurs.
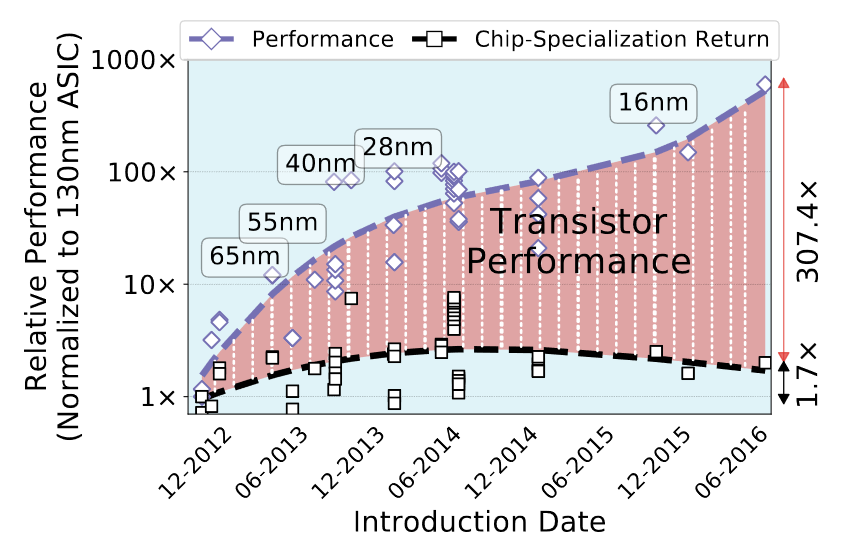
Source : The Accelerator Wall: Limits of Chip Specialization.
 Répondre avec citation
Répondre avec citation





Partager