Bonsoir Éric,

Envoyé par
debutant001
c'est vrai : pourquoi ne pas inclure les deux dans la propriété "adr_s_rue" ?
Cest la bonne option. Plus généralement, lessentiel est dêtre à même de produire les 5 lignes dadresse à partir des données contenues dans la base de données.
Envoyé par
debutant001
Si j'ai bien compris, voici comment je pense maintenant gérer ces derniers
Cest bon. Noubliez pas de sous-traiter à PostgreSQL le contrôle des valeurs prises pas le type et la catégorie de téléphone (CREATE TABLE, contrainte CHECK).
Envoyé par
debutant001
concernant le dernier point, ce que vous vouliez me dire initialement c'était qu'il y avait forcément un lien entre "com_i_id" et "use_i_id" du fait que la cardinalité de l'association "Posséder" entre les entités "tUser" et "tCommentaire" est de type :
tUser --(0,1)----(Posséder)----(1,1)--tCommentaire
Quil y ait un lien entre "com_i_id" et "use_i_id" (voir plus bas) est une conséquence de la présence dans votre dictionnaire dattributs artificiels, les identifiants, alors quun dictionnaire ne devrait concerner que les attributs naturels, par exemple le nom, le prénom dun inscrit (attributs dont certains possèdent la propriété dunicité et sont donc des identifiants naturels, cas par exemple du numéro de téléphone dun inscrit).
Pour illustrer, par référence au tableau ci-dessous des éléments chimiques (source Wikipedia), lors de la constitution du dictionnaire des données, en plus des attributs naturels qui y figurent, quelle serait lutilité dy ajouter doffice un attribut ElementId qui en soit lidentifiant ? Du point de vue de linformation, objectivement aucune, jai envie de dire que ça tient du parasitisme. Quon le fasse au niveau du MCD, daccord et cest même nécessaire, parce quon en arrive au stade du traitement informatisé, mais en amont, c'est-à-dire pour lutilisateur final de votre application (disons la maîtrise douvrage) il ny a évidemment pas de valeur ajoutée (au contraire...) à lui exposer des attributs artificiels et autres avatars purement techniques.
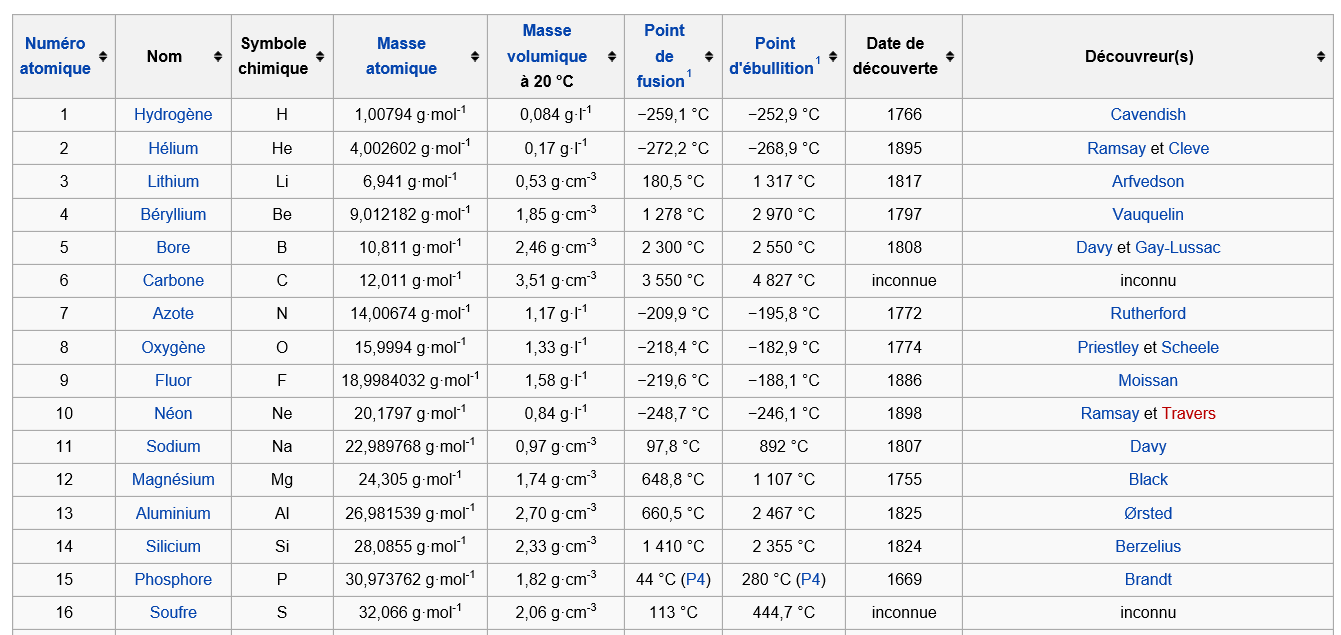
Ajouter mécaniquement des identifiants artificiels peut avoir des effets secondaires conduisant à une modélisation sujette à correction (si lon tient compte de ce qua écrit Ockham...)
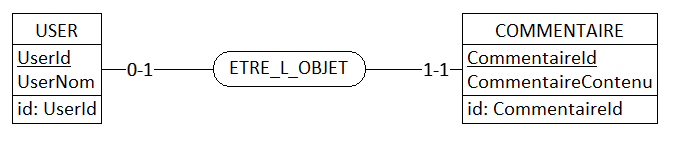
Je mexplique. Si lon vous suit, au stade du MCD on aura la représentation suivante :
tUser --0,1----(Posséder)----1,1--tCommentaire
Jai supprimé les parenthèses encadrant les cardinalités, car le métamodèle du MCD merisien ne les prend pas en considération (cf. louvrage de référence La méthode Merise, Tome 1 : Principes et outils de Tardieu, Rochfeld, Colletti) et elles peuvent être cause dambiguïté lors de lutilisation de certains AGL qui leur affectent un rôle particulier (cas de PowerAMC).
Quoi quil en soit utilisons les services dun AGL (ce qui est très fortement recommandé), par exemple DB-MAIN (gratuit, fiable et sérieux).
MCD selon DB-MAIN (outre les identifiants, je nai fait figurer que quelques attributs).
Envoyé par
debutant001
Désolé je n'avais pas compris votre remarque. (en fait, c'est la citation de Guillaume dOckham qui m'a induit en erreur : j'ai cru qu'il y avait quelque chose d'inutile dans mon entité)
Considérons le MLD déduit par DB-MAIN du MCD précédent.
MLD
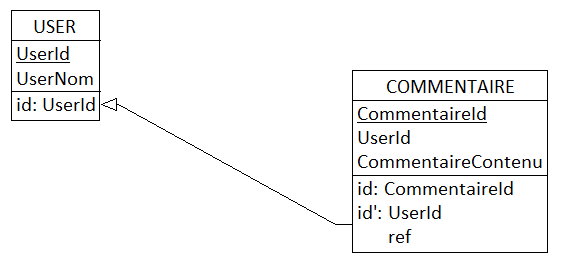
Où id symbolise la clé étrangère branchant COMMENTAIRE sur USER, et « ref » est synonyme de « clé étrangère ».
Code SQL correspondant :
create table USER
(
UserId int not null,
UserNom varchar(48) not null,
constraint USER_PK primary key (UserId)
);
create table COMMENTAIRE
(
CommentaireId int not null,
UserId int not null,
CommentaireContenu varchar(255) not null,
constraint COMMENTAIRE_PK primary key (CommentaireId),
constraint COMMENTAIRE_AK unique (UserId),
constraint COMMENTAIRE_USER_FK foreign key (UserId)
references USER (UserId) ON DELETE CASCADE
);
{UserId} > {CommentaireId}
{CommentaireId} > {UserId}
Considérons maintenant le MLD suivant :
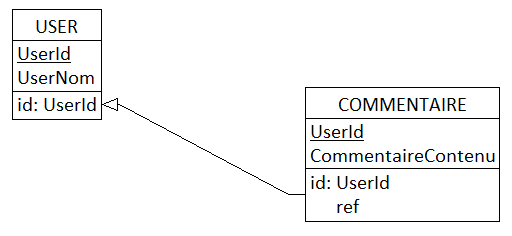
Traduction en SQL :
create table USER
(
UserId int not null,
UserNom varchar(48) not null,
constraint USER_PK primary key (UserId)
);
create table COMMENTAIRE
(
UserId int not null,
CommentaireContenu varchar(255) not null,
constraint COMMENTAIRE_PK primary key (UserId),
constraint COMMENTAIRE_USER_FK foreign key (UserId)
references USER (UserId) ON DELETE CASCADE
);
Cette fois-ci, lattribut UserId fait lobjet à la fois de la clé primaire de la table COMMENTAIRE et de la clé étrangère référençant la clé primaire {UserId} de la table USER. Lattribut CommentaireId est devenu inessentiel, superflu, donc parasite, ce qui justifie son élimination au nom de la proposition dOckham.
Envoyé par
debutant001
vous ne m'avez pas répondu à propos de l'obligation ou non de nommer différemment toutes les associations dans un MCD...
De fait, je ny avais pas fait attention. Donner un nom pertinent à une association nest pas un exercice facile. En plus faire en sorte que les noms soient systématiquement différents relève de la haute voltige, exercice fort à la mode à lépoque où les AGL de modélisation des MCD nexistaient pas ou peu (imaginez en plus ce que cela peut représenter si le MCD comporte 500 entités-types et plus...)
Quand il sagit de présenter un MCD à linterlocuteur non informaticien, à savoir la maîtrise douvrage qui en général préfère les bandes dessinées aux dossiers de conception austères, souvent obscurs et ambigus, donner un nom sémantiquement pertinent à chaque association est nécessaire. Mais que les noms des associations soient systématiquement différents, ça ne concerne pas cet interlocuteur, il nest sensible quà la signification des associations.
Quand il sagit de construire un MCD au moyen dun AGL, si celui-ci exige que les associations aient des noms différents, on doit évidemment sy conformer (par exemple, un AGL comme PowerAMC permet que les associations aient le même nom dans la partie visible (le diagramme quon affiche), mais il linterdit pour les noms sous le capot, là où ils noms donneront lieu le cas échéant au nom des tables).
Pour ma part, je veille soigneusement au nom des associations qui donneront lieu à des tables (niveau SQL), mais pour les autres, je nai pas de temps à perdre, si par exemple le mot « appartenir » est pertinent, je lutilise, et si cest plus dune fois, ça ne me dérange aucunement puisque ces noms dassociations ne feront pas lobjet de tables, elles disparaîtront en fumée (ou feront à la limite partie des noms des clés étrangères).














)
 Répondre avec citation
Répondre avec citation















Partager