











Salut à tous !!
J'ai développé une application en JAVA qui parcourt une arborescence (plusieurs en réalité) de fichiers, et qui fait le hashMD5 de chaque fichier.
Ces hash sont stockés dans une table de ma base de donnée MySQL, ainsi que l'URL (plutôt chemin d'accès) du fichier.
Mon programme a pour objectif de vérifier l'intégrité et l'intégralité des données dans le temps.
Pour ce faire il est exécuté périodiquement (l'objectif étant toutes les semaines).
Le programme va donc pour chaque fichier, comparer l'ancien hash et le nouveau, pour savoir si le fichier a était modifié.
Je vous rassure je ne fais pas de SELECT pour chaque fichiers, ça prendrai beaucoup trop de temps, je récupère donc tous les hash au début de lexécution de mon programme.
Dans tous les cas, pour chaque fichiers, modifié ou non, je fais une requête UPDATE sur la colonne Checked pour la setter à 1.
Pour pouvoir à la fin du programme trouvé les fichiers qui on était supprimé (Checked = 0).
Encore une fois, je ne fais pas cette requête à chaque fichier, mais seulement au bout de 500fichiers.
Mais c'est là que les lenteurs interviennent.
En effet au plus ma base de donnée, ou plutôt la table, grossit (> 2 000 000 denregistrements), au plus les requêtes sont longues. Normal je suppose, mais là c'est vraiment HYPER long !
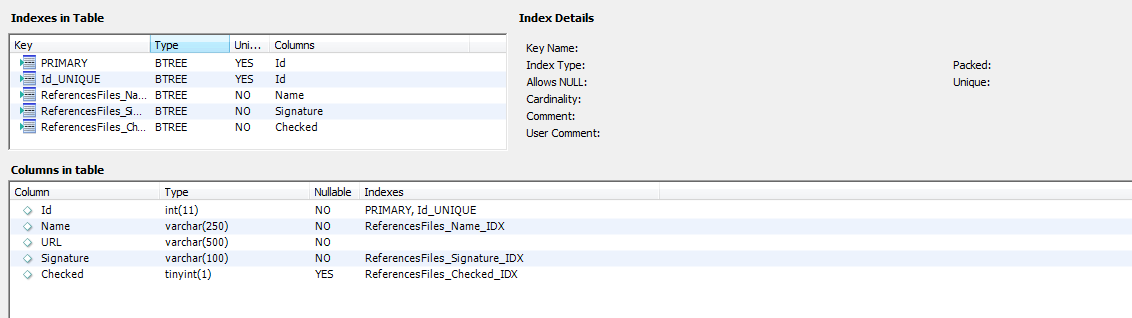
J'ai fait des index sur la plupart de mes colonnes, a lexception de la colonne URL car elle a une longueur de 500, et MySQL Workbench m'envoi péter.
Cependant cette colonne est présente dans toutes mes requêtes..
Voici mes requêtes principales :
La dernière étant appelée des millions de fois.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
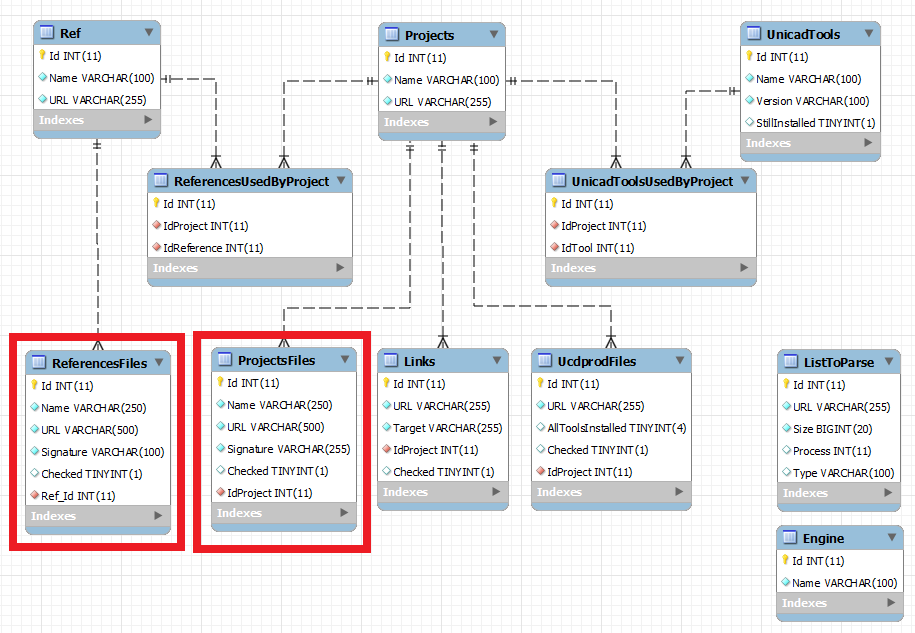
Tout ce que je dis est valable pour les deux tables : ProjectsFiles et ReferencesFiles.
Au début de mon post j'ai parlé de plusieurs arborescences, en effet je lance 50 fois mon programme en parallèle sur 50 arborescences différentes.
Seulement pour l'instant mes tests se font sur une seule arborescence, et les lenteurs sont déjà là.
Voici un schéma de ma DB :
Voici les indexs créé sur la table ReferencesFiles (également valable pour la table ProjectsFiles).
Ma question est "simple" :
Que puis-je faire pour résoudre ce problème de lenteurs ?
Le seul moyen est de réduire la longueur de la colonne URL à 255 et de faire un index dessus ?
Merci d'avance !

 Répondre avec citation
Répondre avec citation





















Partager