



















DB-Engines Ranking : PostgreSQL désigné système de gestion de base de données de l'année 2017
Quels étaient vos SGBD préférés en 2017 ?
Comme il est de coutume depuis ces dernières années, le site DB-Engines, spécialisé dans le classement des moteurs de base de données, a livré son classement pour lannée qui vient de sécouler. Au total, 341 systèmes de gestion de base de données (répartis entre différents modèles de bases de données) étaient en course pour le titre du SGBD de lannée 2017.
Il faut noter que le titre de SGDB de l'année est décerné au système qui enregistre la plus forte hausse en popularité (et non la popularité absolue) au cours de l'année en question. Le classement de DB-Engines ne mesure pas non plus le nombre d'installations des SGBD ni leur utilisation dans les systèmes informatiques. La popularité d'un système de gestion de base de données telle que mesurée par le classement DB-Engines se base en effet sur les paramètres suivants :
- le nombre de fois que le système est mentionné sur les sites web. Cette statistique est mesurée par le nombre de résultats de recherche dans les moteurs Google et Bing. Afin de compter seulement les résultats pertinents, les requêtes doivent inclure le mot-clé « database » ainsi que le nom du SGBD ;
- la fréquence des recherches dans Google Trends ;
- la fréquence des discussions techniques sur le système. Cette statistique est mesurée par le nombre de questions connexes et le nombre dutilisateurs intéressés sur Stack Overflow et DBA Stack Exchange ;
- le nombre doffres demploi dans lesquelles le système est mentionné sur Indeed et Simply Hired ;
- le nombre de profils sur les réseaux professionnels, dans lesquels le système est mentionné. Le réseau social utilisé ici est LinkedIn ;
- la pertinence sur les réseaux sociaux, mesurée par le nombre de tweets dans lesquels le système est mentionné.
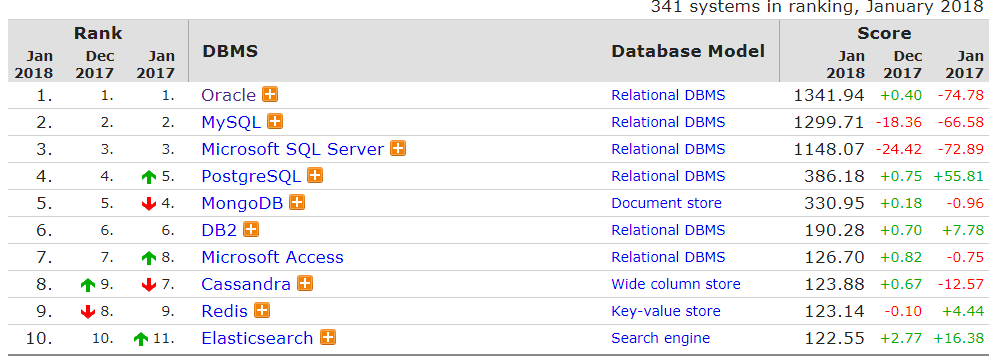
En se basant sur ces critères, PostgreSQL est le SGBD qui a gagné le plus en popularité dans le classement DB-Engines au cours de la dernière année, c'est pourquoi il a été déclaré SGBD de l'année 2017. PostgreSQL a en effet enregistré un gain total de 55,81 points (+17 %) au cours de l'année 2017. D'après DB-Engines, la nouvelle version PostgreSQL 10 a certainement contribué à stimuler davantage l'intérêt pour le SGBD. « Avec l'introduction du partitionnement déclaratif, l'amélioration du parallélisme des requêtes, la réplication logique et la validation par quorum pour les réplications synchrones, PostgreSQL 10 s'est spécifiquement concentré sur les améliorations pour distribuer efficacement les données sur plusieurs nuds. »
Après PostgreSQL viennent ElasticSearch (à la deuxième place) et MariaDB (en troisième position). ElasticSearch a vu son score augmenter de 16,38 points (+ 15 %) en 2017. Deux faits, selon DB-Engines, peuvent avoir contribué à ce succès : la sortie d'ElasticSearch 6 en novembre dernier et l'effort d'Elastic, la société derrière ElasticSearch, de créer avec Elastic Stack un écosystème autour d'ElasticSearch, y compris des outils pour la collecte de données, la visualisation de données et l'apprentissage automatique. MariaDB a, quant à lui, amélioré son score de 13,26 points (+29 %) en 2017.
Il faut noter ici que ce n'est pas le pourcentage d'évolution des scores de popularité qui est regardé pour déterminer le SGBD de l'année. Mais c'est plutôt la différence entre les scores de popularité au début de deux années successives (ici janvier 2017 et janvier 2018), parce que cela permet de ne pas favoriser les SGBD avec une faible popularité au début de l'année.
Il faut aussi préciser que pour le titre de SGBD de l'année, PostgreSQL succède à SQL Server de Microsoft (vainqueur en 2016) et Oracle Database, SGBD de l'année 2015. En ce qui concerne la popularité absolue des SGBD, Oracle reste cependant encore leader devant MySQL et SQL Server. Ci-dessous le top 10 de DB-Engines.
Sources : Blog DB-Engines, DB-Engines Ranking
Et vous ?
Que pensez-vous de ce classement ?

 Répondre avec citation
Répondre avec citation









 . Résultat : projet abandonné. De plus la liberté d'installer n'importe où est très pratique (duplications de VMs, sur PC portable par exemple).
. Résultat : projet abandonné. De plus la liberté d'installer n'importe où est très pratique (duplications de VMs, sur PC portable par exemple).










Partager