













LORM serait-il une « grosse erreur » ?
Selon un développeur, « lORM est un anti-pattern qui ne devrait pas exister »
Il existe plusieurs design patterns utilisés dans la programmation orientée objet, et certains tellement utilisés quils deviennent presque incontournables lorsquon veut apprendre le développement. LObject Relationnal Mapping (ORM) est lun de ces patterns à succès. Il permet daccéder à une base de données relationnelle à partir dobjets. On peut le résumer comme une technique qui crée lillusion dune base de données orientée objet à partir dune base de données relationnelle.
Ce modèle est implémenté dans plusieurs langages de programmation aujourdhui à tel point quil devient une référence dans les livres. Toutefois, dans un article, Yegor Bugayenko, Directeur de technologie à Teamed.io, déclare que « lORM est un anti-pattern terrible qui viole tous les principes de la programmation orientée objet ».
Ce nest pas la première fois que quelquun critique lORM. Le débat est long et ne date pas d'hier. On lui avait déjà reproché dêtre techniquement limité, faible en performances et difficile à apprendre. Toutefois, pour Yegor Bugayenko, l'idée derrière lORM est fausse. Selon lui, « son invention était peut-être la deuxième grosse erreur en POO après la référence NULL ».
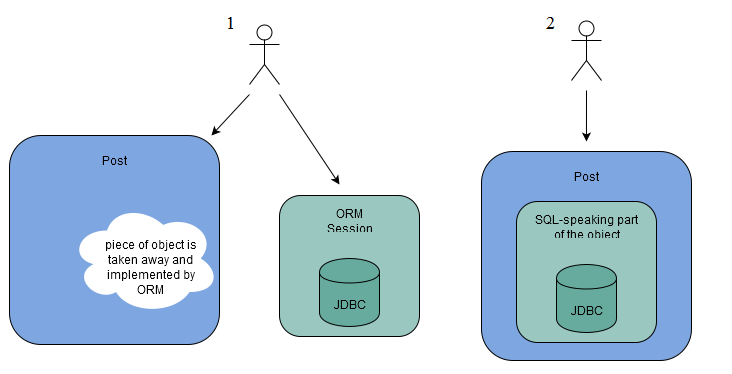
La raison quil donne est simple ; au lieu dencapsuler linteraction avec la base de données dans un objet et fournir par conséquent un point d'entrée unique, il fait linverse : il définit les routines qui permettent de communiquer avec la base dans lobjet ORM tandis que les données sont extraites « dans la chose que nous ne pouvons même pas appeler un objet ». Ce qui rend la détection des erreurs plus difficile. Mais en plus, « le SQL nest pas caché » ce qui ajoute au programmeur la contrainte den connaître la syntaxe.
Figure : comparaison entre 1) technique utilisée par l'ORM, 2) technique utilisée par les SQL-speaking objects
Selon lui, la solution serait dencapsuler le tout dans un seul et même objet (comme décrit dans la figure). Cet objet, que Yegor Bugayenko appelle « SQL-speaking object », sera en charge de toutes les opérations et permettra de cacher tous les détails de la communication avec la base de données : « Il n'y a pas de transactions, pas de sessions ou de factories. Nous ne savons même pas si ces objets sont en train de parler avec la base de données ou sils gardent toutes les données dans des fichiers textes ».
Dans son article, il présente quelques exemples en insistant sur le fait que les SQL-speaking objects sont plus simples et respectent de loin les principes de lorienté objet, à linverse de lORM « qui ne devrait exister dans aucune application, que ce soit une petite application web ou un gros système pour entreprise ».
Source : DZone
Et vous ?
Êtes-vous daccord avec lavis de Yegor Bugayenko ? Pourquoi ?
 Répondre avec citation
Répondre avec citation
Partager