















Julia serait capable de lire les fichiers CSV dix à vingt fois plus vite que Python et R,
selon une étude
Julia est un langage de programmation dont la première version remonte à août 2009. Cest un langage de haut niveau, performant et dynamique conçu pour le calcul scientifique. Il a une syntaxe familière aux utilisateurs d'autres environnements de développement similaires. Depuis sa première version stable, Julia est plébiscité comme lun des meilleurs langages de la science des données, sinon le meilleur. Daprès une récente étude, il serait capable de lire les fichiers CSV (ou Comma-Separated Values) 10 à 20 fois plus vite que les langages de programmation rivaux Python et R.
Selon les auteurs de létude, la toute première tâche dans tout processus danalyse de données consiste simplement à lire les données, et cela doit absolument être fait rapidement et efficacement pour que le travail le plus intéressant puisse commencer. Dans de nombreux secteurs et domaines, le format de fichier CSV est le format le plus utilisé pour le stockage et le partage des données tabulaires. Le chargement rapide et robuste des CSV est crucial, et il doit être bien adapté à une grande variété de tailles, de types et de formes de fichiers.
Létude a donc comparé les performances de lecture de huit ensembles de données réelles différents sur trois analyseurs CSV différents : fread de R, read_csv de Pandas et CSV.jl de Julia. Chacun d'eux est considéré comme étant le meilleur de sa catégorie dans les analyseurs CSV de R, Python et Julia, respectivement. Les trois outils ont une prise en charge robuste pour le chargement d'une grande variété de types de données avec des valeurs potentiellement manquantes, mais seuls fread (R) et CSV.jl (Julia) prennent en charge le multithreading.
Pandas ne prend en charge que le chargement à thread unique. CSV.jl est en outre unique en ce sens qu'il est le seul outil entièrement implémenté dans son langage de haut niveau plutôt que d'être implémenté en C et enveloppé de R ou de Python. Pandas dispose d'un analyseur natif Python légèrement plus performant, il est nettement plus lent et presque toutes les utilisations de read_csv se font par défaut sur le moteur C. Ainsi, les benchmarks CSV.jl représentent ici non seulement la vitesse de chargement des données dans Julia, mais sont aussi indicatifs des types de performances possibles dans le code Julia ultérieur utilisé dans l'analyse.
Les benchmarks suivants montrent que le CSV.jl de Julia est de 1,5 à 5 fois plus rapide que Pandas, même sur un seul thread. Avec le multithreading activé, il est aussi rapide ou plus rapide que read_csv de R. Enfin, les outils utilisés par léquipe pour l'étalonnage sont BenchmarkTools.jl pour Julia, microbenchmark pour R et timeit pour Python. Voici les résultats obtenus.
Analyse comparative sur les données homogènes
Les ensembles de données homogènes sont des ensembles de données qui comportent le même type de données dans toutes les colonnes. La mesure de performance est le temps nécessaire pour charger un ensemble de données lorsque le nombre de threads passe de 1 à 20. Et comme Pandas ne prend pas en charge le multithreading, la vitesse d'un seul thread est indiquée pour tous les comptages de base. Létude a été réalisée sur quatre catégories de données homogènes, dont des données flottantes uniformes et deux types de données de chaînes uniformes et des données sur Apple.
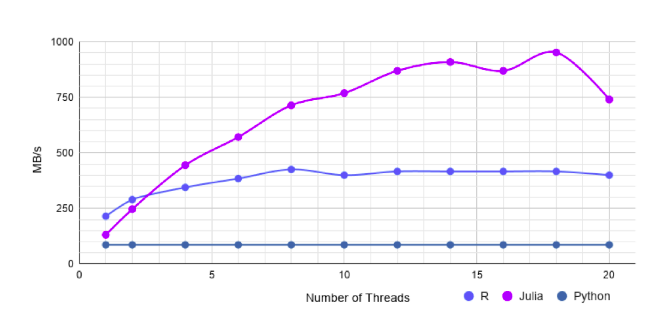
En premier lieu, lensemble de données flottantes uniformes contient des valeurs flottantes disposées en 1 million de lignes et 20 colonnes. Pandas prend 232 millisecondes pour charger ce fichier CSV. Le fichier data.table, sur un seul thread, est 1,6 fois plus rapide que le fichier CSV.jl de Julia. Avec le multithreading, CSV.jl est à son meilleur, soit plus du double de la vitesse de data.table. Il est 1,5 fois plus rapide que Pandas sans multithreading, et environ 11 fois plus rapide avec. En second lieu, lanalyse comparative a porté sur le premier ensemble de données de chaînes uniformes.
Cet ensemble contient des valeurs de chaîne dans toutes les colonnes et compte 1 million de lignes et 20 colonnes. Pandas prend 546 millisecondes pour charger le fichier. Avec R, l'ajout de threads ne semble pas entraîner de gain de performance. Avec un seul thread, CSV.jl est 2,5 fois plus rapide que data.table. Avec 10 threads, il est environ 14 fois plus rapide que data.table. Ensuite, il y a le second ensemble de données sur les chaînes uniformes. Les dimensions de cet ensemble sont les mêmes que celles de l'ensemble de données précédent. Cependant, chaque colonne comporte également des valeurs de type Missing (des données manquantes).
Ici, Pandas prend 300 millisecondes. Sans threading, CSV.jl est 1,2 fois plus rapide que R, et avec, il est environ 5 fois plus rapide. Enfin, les données sur Apple concernent le cours des actions de lentreprise. Cet ensemble de données contient 50 millions de lignes et 5 colonnes, et fait 2,5 Go. Les lignes sont les prix ouverts, élevés, bas et de clôture de l'action AAPL. Les quatre colonnes avec les prix sont des valeurs flottantes, et il y a une colonne de date. Avec un seul thread, CSV.jl est environ 1,5 fois plus rapide que fread.
Avec le multithreading, CSV.jl est environ 22 fois plus rapide. read_csv de Pandas prend 34s pour lire le fichier, c'est plus lent que R et Julia.
Performances sur des ensembles de données hétérogènes
Dans cette partie de létude, la première comparaison sest basée sur un ensemble de données mixtes. Cet ensemble de données comporte 10 000 lignes et 200 colonnes. Les colonnes contiennent les valeurs String, Float, DateTime et aussi des valeurs de types Missing. Ici, Pandas prend environ 400 millisecondes pour charger cet ensemble de données. Sans threading, CSV.jl est 2 fois plus rapide que R, et est environ 10 fois plus rapide avec 10 threads. Lanalyse comparative suivante concerne un ensemble de données sur les risques hypothécaires, plus large.
Cet ensemble de données sur les risques hypothécaires de Kaggle est un ensemble de données de type mixte, avec 356 000 lignes et 2190 colonnes. Les colonnes sont hétérogènes et ont des valeurs de type String, Int, Float, Missing. Pandas prend 119s pour lire dans cet ensemble de données. Avec un seul thread, fread est environ 2 fois plus rapide que CSV.jl. Mais avec plus de threads, Julia est soit aussi rapide, soit un peu plus rapide que R.
Source : Julia Computing
Et vous ?
Que pensez-vous de cette étude ? Pertinente ou pas ?
Voir aussi
 Répondre avec citation
Répondre avec citation




























Partager