Les capacités « émergentes » des personnes en formation initiale se développent en réalité de manière progressive et prévisible,
selon des chercheurs
Une récente étude remet en question la notion d'émergence soudaine des capacités des grands modèles linguistiques. Initialement considérées comme des percées imprévisibles, ces capacités se révèlent en réalité évoluer de manière graduelle et prévisible, selon la façon dont elles sont mesurées. Le projet Beyond the Imitation Game benchmark (BIG-bench) a mis en lumière ces comportements, montrant que certaines compétences restent longtemps à un niveau bas avant de s'améliorer brusquement. Toutefois, des chercheurs de l'université de Stanford remettent en question cette idée d'émergence, affirmant que cela dépend en grande partie de la manière dont les performances des modèles sont évaluées. Ils suggèrent que l'émergence est davantage une illusion créée par les métriques de mesure plutôt qu'une caractéristique intrinsèque des modèles.
Une étude sur l'addition à trois chiffres illustre cette perspective, montrant que les performances des modèles peuvent varier selon la méthode d'évaluation utilisée. Bien que certains scientifiques reconnaissent la pertinence de cette remise en question, d'autres soulignent que des discontinuités dans l'amélioration des modèles persistent, indépendamment de la manière dont les mesures sont prises. En fin de compte, la compréhension de l'émergence des capacités des modèles linguistiques reste un sujet complexe et crucial pour la communauté de recherche, surtout compte tenu de l'impact potentiel de ces technologies dans divers domaines.
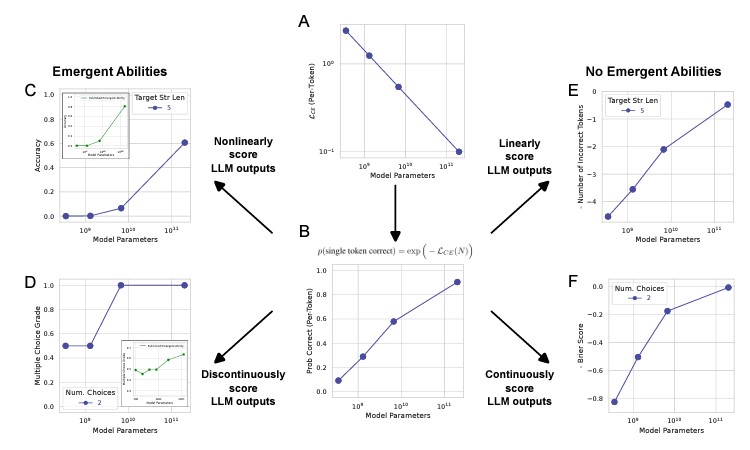
Les capacités émergentes des grands modèles de langage sont le produit des choix de métriques effectués par les chercheurs, et non de variations imprévisibles dans le comportement des modèles à mesure qu'ils évoluent en taille.
- Supposons que la perte d'entropie croisée par trait diminue de façon monotone avec l'échelle du modèle diminue de façon monotone avec l'échelle du modèle, c'est-à-dire que le LCE évolue comme une loi de puissance ;
- La probabilité par jeton de sélectionner le jeton correct asymptote vers 1 ;
- Si le chercheurévalue les résultats des modèles à l'aide d'une mesure non linéaire telle que la précision (qui exige qu'une séquence de jetons soit toujours correcte).
- de jetons soient tous corrects), le choix de la métrique échelonne la performance de manière non linéaire, ce qui entraîne une variation brutale et imprévisible de la performance de manière imprévisible d'une manière qui correspond qualitativement aux capacités émergentes publiées (encadré).
- émergentes publiées (encadré) ;
- Si le chercheur évalue plutôt les résultats des modèles à l'aide d'une mesure discontinue comme la note de choix multiple (qui s'apparente à une fonction en escalier), le choix de la métrique échelonne la performance de manière discontinue, ce qui entraîne à nouveau une variation brutale de la performance.
- de manière discontinue, ce qui entraîne à nouveau des variations brutales et imprévisibles de la performance ;
- Le passage d'une métrique non linéaire à une métrique linéaire telle que Token Edit Distance, la mise à l'échelle montre des améliorations lisses, continues et prévisibles, éliminant ainsi les effets de la métrique non linéaire sur les performances ;
- et prévisibles, faisant disparaître la capacité émergente ;
- Passage d'une métrique discontinue à une métrique continue telle que le score de Brier révèle à nouveau des améliorations lisses, continues et prévisibles dans l'exécution de la tâche. Des améliorations lisses, continues et prévisibles de la performance. Par conséquent, les capacités émergentes sont créées par le choix des mesures du chercheur, et non par des changements fondamentaux dans le comportement de la famille modèle sur des tâches spécifiques avec l'échelle.
Il a été démontré que la mise à l'échelle des modèles de langage améliore de manière prévisible les performances et l'efficacité de l'échantillonnage sur un large éventail de tâches en aval. Les chercheurs ont traité plutôt d'un phénomène imprévisible qu'ils appelent les capacités émergentes des grands modèles de langage. Ils considèrent qu'une capacité est émergente si elle n'est pas présente dans les modèles plus petits mais qu'elle l'est dans les modèles plus grands. Ainsi, les capacités émergentes ne peuvent pas être prédites simplement en extrapolant les performances des modèles plus petits. L'existence d'une telle émergence soulève la question de savoir si une mise à l'échelle supplémentaire pourrait potentiellement élargir davantage l'éventail des capacités des modèles de langage.
À quelle vitesse les grands modèles linguistiques acquièrent-ils des compétences inattendues ?
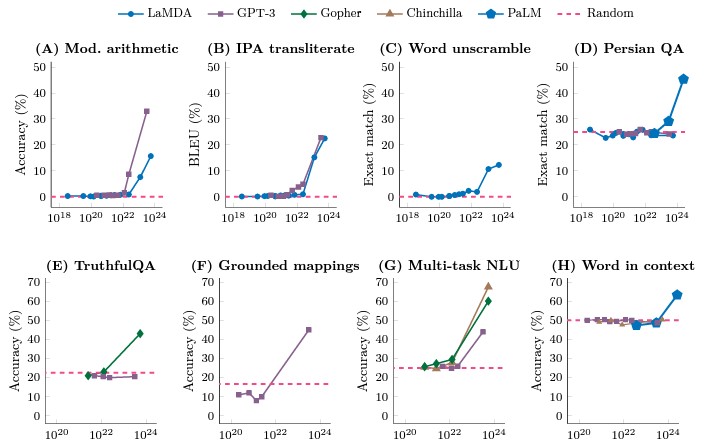
Les chercheurs suggèrent que les capacités dites émergentes se développent en fait progressivement et de manière prévisible, en fonction de la manière dont elles sont mesurées. Il y a deux ans, dans le cadre d'un projet appelé Beyond the Imitation Game benchmark (BIG-bench), 450 chercheurs ont dressé une liste de 204 tâches destinées à tester les capacités des grands modèles de langage, qui alimentent les chatbots tels que ChatGPT. Pour la plupart des tâches, les performances se sont améliorées de manière prévisible et régulière au fur et à mesure de l'augmentation de la taille des modèles - plus le modèle est grand, plus il s'améliore. Mais pour d'autres tâches, l'augmentation des capacités n'a pas été régulière. Les performances sont restées proches de zéro pendant un certain temps, puis elles ont augmenté. D'autres études ont mis en évidence des sauts de capacité similaires.
Les auteurs ont décrit ce comportement comme une « percée » ; d'autres chercheurs l'ont comparé à une transition de phase en physique, comme lorsque l'eau liquide se transforme en glace. Dans un article publié en août 2022, les chercheurs notent que ces comportements sont non seulement surprenants mais aussi imprévisibles, et qu'ils devraient éclairer les conversations en cours sur la sécurité, le potentiel et le risque de l'IA. Ils ont qualifié ces capacités d' « émergentes », un terme qui décrit les comportements collectifs qui n'apparaissent qu'une fois qu'un système atteint un haut niveau de complexité. Mais les choses ne sont peut-être pas si simples.
Définition des capacités émergentes
En tant que concept général, l'émergence est souvent utilisée de manière informelle et peut être raisonnablement interprétée de nombreuses manières différentes. Dans le présent document, nous examinerons une définition ciblée des capacités émergentes des grands modèles linguistiques : Une capacité est émergente si elle n'est pas présente dans les modèles plus petits mais qu'elle est présente dans les modèles plus grands.
Les capacités émergentes n'auraient pas été directement prédites par l'extrapolation d'une loi d'échelle (c'est-à-dire des améliorations constantes des performances) à partir de modèles à petite échelle. Lorsqu'elles sont visualisées à l'aide d'une courbe d'échelle (axe des x : échelle du modèle, axe des y : performances), les capacités émergentes présentent un schéma clair : les performances sont quasi aléatoires jusqu'à ce qu'un certain seuil critique d'échelle soit atteint, après quoi les performances augmentent et deviennent nettement supérieures aux performances aléatoires. Ce changement qualitatif est également connu sous le nom de transition de phase - un changement spectaculaire dans le comportement global qui n'aurait pas été prévu en examinant des systèmes à plus petite échelle.
Les modèles de langage actuels ont été mis à l'échelle principalement en fonction de trois facteurs : la quantité de calcul, le nombre de paramètres du modèle et la taille de l'ensemble de données d'apprentissage. Dans le présent document, les chercheurs ont analysé les courbes de mise à l'échelle en traçant les performances de différents modèles où le calcul de formation pour chaque modèle est mesuré en FLOPs sur l'axe des x. Étant donné que les modèles linguistiques formés avec plus de calcul ont tendance à avoir également plus de paramètres.
Échelle du modèle (FLOps d'entraînement)
L'utilisation des FLOP de formation ou des paramètres du modèle comme axe des abscisses produit des courbes aux formes similaires, car la plupart des familles de modèles de langage Transformer denses ont mis à l'échelle le calcul de formation de manière à peu près proportionnelle aux paramètres du modèle. La taille de l'ensemble de données d'apprentissage est également un facteur important, mais nous ne représentons pas les capacités en fonction de ce facteur car de nombreuses familles de modèles de langage utilisent un nombre fixe d'exemples d'apprentissage pour toutes les tailles de modèles. Bien que les chercheurs se concentrent ici sur le calcul de l'entraînement et la taille du modèle, il n'existe pas d'indicateur unique qui capture de manière adéquate tous les aspects de l'échelle. Par exemple, le Chinchilla a quatre fois moins de paramètres que le Gopher mais utilise un calcul d'entraînement similaire ; et les modèles de mélange d'experts clairsemés ont plus de paramètres par calcul d'entraînement/d'inférence que les modèles.
Dans l'ensemble, il peut être judicieux de considérer l'émergence comme une fonction de nombreuses variables corrélées. Il convient de noter que l'échelle à laquelle l'émergence d'une capacité est observée pour la première fois dépend d'un certain nombre de facteurs et n'est pas une propriété immuable de la capacité. Par exemple, l'émergence peut se produire avec moins de calcul d'entraînement ou moins de paramètres de modèle pour les modèles entraînés sur des données de meilleure qualité. Inversement, les capacités émergentes dépendent aussi de façon cruciale d'autres facteurs, comme le fait de ne pas être limité par la quantité de données, leur qualité ou le nombre de paramètres du modèle. Les modèles linguistiques actuels ne sont probablement pas formés de manière optimale, et notre compréhension de la meilleure manière de former les modèles évoluera avec le temps.
Un nouvel article rédigé par un trio de chercheurs de l'université de Stanford affirme que l'apparition soudaine de ces capacités n'est qu'une conséquence de la manière dont les chercheurs mesurent les performances du LLM. Selon eux, ces capacités ne sont ni imprévisibles ni soudaines. « La transition est beaucoup plus prévisible qu'on ne le croit », a déclaré Sanmi Koyejo, informaticien à Stanford et auteur principal de l'article. « Les affirmations fortes d'émergence ont autant à voir avec la façon dont nous choisissons de mesurer qu'avec ce que font les modèles.
Ce n'est que maintenant que nous voyons et étudions ce comportement, en raison de l'ampleur qu'ont prise ces modèles. Les modèles linguistiques de grande taille s'entraînent en analysant d'énormes ensembles de données textuelles - des mots provenant de sources en ligne telles que des livres, des recherches sur le web et Wikipédia - et en trouvant des liens entre des mots qui apparaissent souvent ensemble. La taille est mesurée en termes de paramètres, qui correspondent à peu près à toutes les façons dont les mots peuvent être reliés. Plus il y a de paramètres, plus le LLM peut trouver de liens. GPT-2 avait 1,5 milliard de paramètres, tandis que GPT-3.5, le LLM qui alimente ChatGPT, en utilise 350 milliards. GPT-4, qui a fait ses débuts en mars 2023 et qui est aujourd'hui à la base de Microsoft Copilot, utiliserait 1,75 trillion de paramètres.
Cette croissance rapide a entraîné une augmentation étonnante des performances et de l'efficacité, et personne ne conteste le fait que des LLM suffisamment grands peuvent accomplir des tâches que des modèles plus petits ne peuvent pas réaliser, y compris des tâches pour lesquelles ils n'ont pas été formés. Le trio de Stanford qui qualifie l'émergence de "mirage" reconnaît que les LLM deviennent plus efficaces au fur et à mesure qu'ils s'étendent ; en fait, la complexité accrue des grands modèles devrait permettre d'améliorer la résolution de problèmes plus difficiles et plus diversifiés. Mais ils affirment que le fait que cette amélioration soit lisse et prévisible ou irrégulière et brutale résulte du choix de la métrique - ou même d'une pénurie d'exemples de test - plutôt que du fonctionnement interne du modèle.
Échelle du modèle (nombre de paramètres)
L'addition à trois chiffres en est un exemple. Dans l'étude BIG-bench de 2022, les chercheurs ont rapporté qu'avec moins de paramètres, le GPT-3 et un autre LLM nommé LAMDA n'ont pas réussi à résoudre avec précision les problèmes d'addition. Cependant, lorsque GPT-3 s'est entraîné en utilisant 13 milliards de paramètres, sa capacité a changé comme si l'on appuyait sur un bouton. Soudain, il a pu effectuer des additions - et LAMDA aussi, avec 68 milliards de paramètres. Cela suggère que la capacité d'additionner émerge à partir d'un certain seuil.
Les chercheurs de Stanford soulignent toutefois que les LLM n'ont été jugés que sur leur précision : Soit ils étaient parfaits, soit ils ne l'étaient pas. Ainsi, même si un LLM prédisait correctement la plupart des chiffres, il échouait. Cela ne me semble pas correct. Si vous calculez 100 plus 278, 376 semble être une réponse beaucoup plus précise que, par exemple, -9,34. Koyejo et ses collaborateurs ont donc testé la même tâche à l'aide d'une mesure qui accorde un crédit partiel. "Nous pouvons demander : dans quelle mesure prédit-il le premier chiffre ? Puis le deuxième ? Puis le troisième ?
Koyejo attribue l'idée de ce nouveau travail à son étudiant diplômé Rylan Schaeffer, qui, selon lui, a remarqué que les performances d'un LLM semblent varier en fonction de la manière dont ses capacités sont mesurées. Avec Brando Miranda, un autre étudiant diplômé de Stanford, ils ont choisi de nouvelles mesures montrant qu'à mesure que les paramètres augmentaient, les LLM prédisaient une séquence de chiffres de plus en plus correcte dans les problèmes d'addition. Cela suggère que la capacité d'additionner n'est pas émergente - c'est-à-dire qu'elle subit un saut soudain et imprévisible - mais graduelle et prévisible. Ils constatent qu'avec un autre instrument de mesure, l'émergence disparaît.
Mais d'autres scientifiques soulignent que ce travail ne dissipe pas complètement la notion d'émergence. Par exemple, l'article du trio n'explique pas comment prédire quand les mesures, ou lesquelles, montreront une amélioration abrupte dans un LLM, a déclaré Tianshi Li, informaticienne à l'université de Northeastern. « En ce sens, ces capacités restent imprévisibles » a-t-elle ajouté. D'autres, comme Jason Wei, un informaticien qui travaille actuellement à l'OpenAI et qui a dressé une liste des capacités émergentes. Il est l'un des auteurs de l'article de BIG-bench.
« Il y a vraiment une conversation intéressante à avoir ici », a déclaré Alex Tamkin, chercheur à la startup d'IA Anthropic. Le nouvel article décompose habilement les tâches à plusieurs étapes afin de reconnaître les contributions des composants individuels, a-t-il ajouté. « Mais ce n'est pas tout. Nous ne pouvons pas dire que tous ces sauts sont un mirage. Je continue de penser que la littérature montre que même lorsque vous avez des prédictions à une étape ou que vous utilisez des mesures continues, vous avez toujours des discontinuités, et que lorsque vous augmentez la taille de votre modèle, vous pouvez toujours voir qu'il s'améliore d'une manière qui ressemble à un saut. »
Et même si l'émergence dans les LLM d'aujourd'hui peut être expliquée par différents outils de mesure, il est probable que ce ne sera pas le cas pour les LLM de demain, plus grands et plus compliqués. « Lorsque nous ferons passer les LLM au niveau supérieur, ils emprunteront inévitablement des connaissances à d'autres tâches et à d'autres modèles », a déclaré Xia "Ben" Hu, informaticien à l'université de Rice.
Cette prise en compte de l'émergence n'est pas seulement une question abstraite pour les chercheurs. Pour M. Tamkin, elle concerne directement les efforts en cours pour prédire le comportement des LLM. « Ces technologies sont si vastes et si applicables », a-t-il déclaré. « J'espère que la communauté s'en servira comme d'un point de départ pour continuer à mettre l'accent sur l'importance de construire une science de la prédiction pour ces choses. Comment ne pas être surpris par la prochaine génération de modèles ? »
Orientations pour les travaux futurs
Les travaux futurs sur les capacités émergentes pourraient porter sur la formation de modèles de langage plus performants, ainsi que sur des méthodes permettant aux modèles de langage d'accomplir des tâches. Certaines orientations potentielles comprennent, sans s'y limiter, les éléments suivants. Poursuite de la mise à l'échelle des modèles. L'augmentation de l'échelle des modèles a jusqu'à présent semblé accroître les capacités des modèles de langage et constitue une orientation directe pour les travaux futurs.
Cependant, la simple mise à l'échelle des modèles de langage est coûteuse en termes de calcul et nécessite de résoudre des problèmes matériels importants, de sorte que d'autres approches joueront probablement un rôle clé dans l'avenir des capacités émergentes des grands modèles de langage. L'amélioration de l'architecture des modèles et des procédures de formation peut faciliter l'obtention de modèles de haute qualité dotés de capacités émergentes tout en réduisant les coûts de calcul. L'une des pistes consiste à utiliser des architectures de mélange d'experts clairsemées, qui augmentent le nombre de paramètres d'un modèle tout en maintenant des coûts de calcul constants pour une entrée.
D'autres orientations pour une meilleure efficacité de calcul pourraient impliquer des quantités variables de calcul pour différentes entrées, l'utilisation de stratégies d'apprentissage plus localisées que la rétropropagation à travers tous les poids dans un réseau neuronal et l'augmentation des modèles avec une mémoire externe. Ces orientations naissantes se sont déjà révélées prometteuses dans de nombreux contextes, mais n'ont pas encore fait l'objet d'une adoption généralisée, ce qui nécessitera probablement des travaux supplémentaires. Mise à l'échelle des données. Il a été démontré qu'un entraînement suffisamment long sur un ensemble de données suffisamment important est essentiel pour la capacité des modèles de langage à acquérir des connaissances syntaxiques, sémantiques et d'autres connaissances du monde.
Les chercheurs ont abordé les capacités émergentes des modèles de langage, pour lesquelles des performances significatives n'ont été observées jusqu'à présent qu'à une certaine échelle de calcul. Les capacités émergentes peuvent couvrir une variété de modèles de langage, de types de tâches et de scénarios expérimentaux. Ces capacités sont un résultat récemment découvert de la mise à l'échelle des modèles de langage, et les questions de savoir comment elles émergent et si une mise à l'échelle plus importante permettra d'obtenir d'autres capacités émergentes semblent être des directions de recherche futures importantes pour le domaine du TAL.
Sources : Are Emergent Abilities of Large Language Models a Mirage ?, Stanford University, UNC Chapel Hill, DeepMind , Emergent Abilities of Large Language Models
Et vous ?
 Quel est votre avis sur le suejt ?
Quel est votre avis sur le suejt ?
Est-ce que les résultats de l'étude sont pertinents ?
Voir aussi :
Les grands modèles de langage sont en état d'ébriété, selon Mattsi Jansky, développeur de logiciels, il présente l'envers du decor des LLM, dans un billet de blog
L'hallucination est inévitable et serait une limitation innée des grands modèles de langage en intelligence artificielle, selon une étude sur la possibilité d'éliminer les hallucinations des LLM
Les grands modèles de langage (LLM) comprennent et peuvent être améliorés par des stimuli émotionnels, d'après un sujet de recherche














 Répondre avec citation
Répondre avec citation
Partager