











Les grands modèles de langage sont des raisonneurs neuro-symboliques, selon une étude démontrant le potentiel significatif des LLM dans des tâches symboliques d'applications réelles.
Un large éventail d'applications du monde réel se caractérise par sa nature symbolique, ce qui nécessite une forte capacité de raisonnement symbolique. Un article étudie l'application potentielle des grands modèles de langage (LLM) en tant que raisonneurs symboliques.
L'étude se concentre sur les jeux basés sur le texte, qui constituent des références importantes pour les agents dotés de capacités de langage naturel, en particulier pour les tâches symboliques telles que les mathématiques, la lecture de cartes, le tri et l'application du bon sens dans les mondes basés sur le texte. Pour faciliter le travail de ces agents, l'étude propose un agent LLM conçu pour relever les défis symboliques et atteindre les objectifs du jeu.
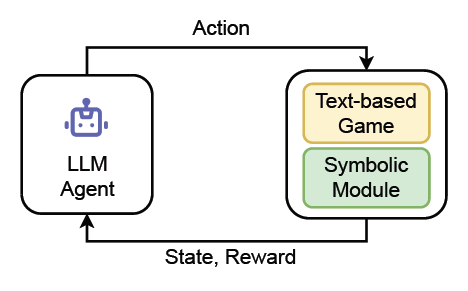
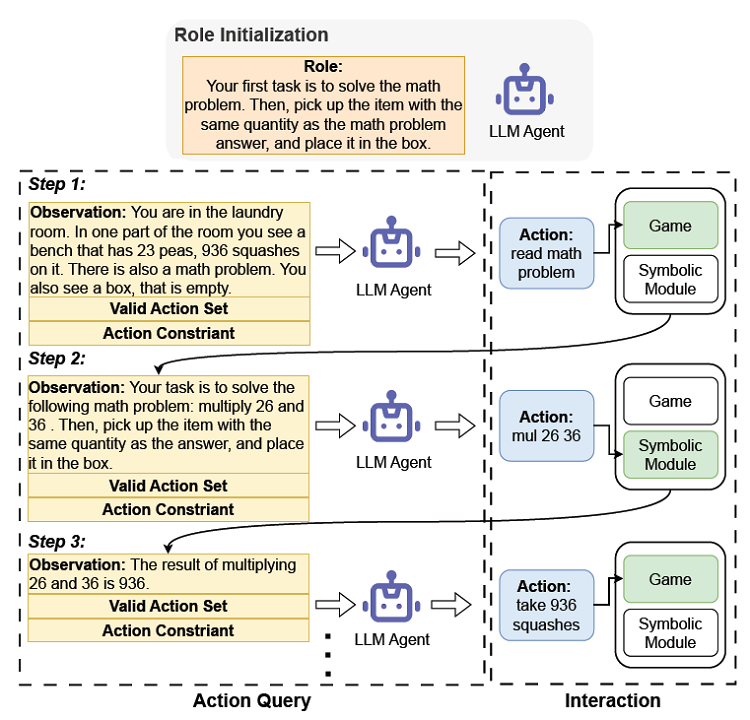
Les chercheurs ont commencé par initialiser l'agent LLM et l'informer de son rôle. L'agent reçoit ensuite des observations et un ensemble d'actions valides des jeux textuels, ainsi qu'un module symbolique spécifique. Avec ces données, l'agent LLM choisit une action et interagit avec les environnements de jeu.
Les résultats expérimentaux de l'étude démontrent que cette méthode améliore de manière significative la capacité des LLM en tant qu'agents automatisés pour le raisonnement symbolique, et l'agent LLM de l'étude a été efficace dans les jeux basés sur le texte impliquant des tâches symboliques, atteignant une performance moyenne de 88% pour toutes les tâches.
L'agent LLM est capable d'interagir avec l'environnement du jeu
Les chercheurs commentent les résultats de l'étude en déclarant :
ContexteNos résultats démontrent que l'incorporation de modules symboliques externes par l'agent LLM conduit à une précision moyenne améliorée par rapport à d'autres lignes de base. Cette capacité est obtenue en exploitant les modèles sous-jacents présents dans les données d'apprentissage. Au lieu de s'appuyer sur la pensée symbolique ou des règles explicites, cette approche acquiert des connaissances en reconnaissant des modèles et des associations à partir du vaste corpus de texte auquel elle a été exposée pendant sa phase de formation, comme le montrent GPT-3.5 et GPT-4. Bien que l'agent LLM ait la capacité de se connecter à un module symbolique pour des tâches spécifiques, il fait toujours preuve d'incertitude et est enclin à faire des erreurs.
La capacité à effectuer des raisonnements est cruciale pour l'IA en raison de son impact significatif sur diverses tâches du monde réel. L'adoption généralisée de grands modèles de langage (LLM), tels que ChatGPT et GPT-4 a conduit à une série de succès remarquables dans des tâches de raisonnement, allant de la question-réponse à la résolution de problèmes mathématiques.
Parmi ces défis, les jeux basés sur le texte servent de repères importants pour les agents dotés de capacités de langage naturel et ont suscité une attention significative dans le domaine de la recherche sur l'apprentissage machine centré sur le langage. Dans ces jeux, un agent utilise le langage pour interpréter divers scénarios et prendre des décisions. La complexité de ces jeux provient de la nécessité de comprendre le langage, de faire preuve de bon sens, de gérer des espaces d'action à la complexité combinatoire, et de l'importance cruciale de la mémoire à long terme et de la planification.
Les défis s'intensifient dans les jeux basés sur le texte qui impliquent des tâches symboliques. L'utilisation de modules symboliques ou d'outils externes pour l'arithmétique, la navigation, le tri et la consultation de la base de connaissances est cruciale pour les agents linguistiques, en particulier dans les jeux complexes basés sur le texte.
Cependant, l'intégration efficace de ces aspects dans les agents linguistiques reste un défi relativement peu abordé. La résolution de ces jeux textuels nécessite un raisonnement interactif en plusieurs étapes, et les agents ont le plus souvent été modélisés à l'aide de l'apprentissage par renforcement. Ces méthodes se heurtent toutefois à des difficultés telles que le retard des récompenses et la difficulté d'explorer de vastes espaces d'action.
Récemment, les approches d'apprentissage par imitation, qui utilisent des données de jeu humain, ont été explorées. Bien que le clonage de comportement (BC) ait le potentiel de répondre efficacement à ces défis, il nécessite souvent des efforts et des ressources considérables. Cela est principalement dû à la nécessité d'acquérir des données d'experts.
Récemment, les grands modèles de langage (LLM) ont démontré des capacités notables de généralisation en contexte, suggérant le potentiel d'éliciter des capacités de raisonnement en incitant ces modèles. Cependant, l'application des LLMs dans l'exécution du raisonnement symbolique reste un domaine sous-exploré.
Des modèles tels que GPT-3.5 et GPT-4 ont montré leur capacité à encoder des informations étendues. Cela indique qu'il est possible d'utiliser les LLM en tant que raisonneurs neuro-symboliques sans s'appuyer sur des données d'entraînement en or étiquetées. Cependant, il y a actuellement peu de recherches sur l'utilisation de ces modèles pour les tâches de raisonnement qui impliquent la logique, les graphiques ou les formules symboliques. L'exploration et le développement de méthodes qui exploitent les LLM pour le raisonnement symbolique sont très intéressants et ont un impact potentiel important.
Les grands modèles de langage (LLM) en tant que raisonneurs symboliques
Selon les chercheurs, l'objectif était d'étudier le rôle des grands modèles de langage (LLM) dans le raisonnement symbolique dans le contexte des jeux basés sur le texte. Lorsqu'il participe à des jeux impliquant des tâches symboliques, l'agent LLM génère les actions les plus rationnelles sur la base de l'état observé du jeu de manière zero-shot, assisté par des modules symboliques externes tels que des calculatrices ou des navigateurs.
L'agent LLM utilise à la fois l'environnement de jeu textuel et les modules symboliques pour générer une liste d'actions valides. Ces actions valides, ainsi que l'observation actuelle, sont intégrées dans l'invite afin d'orienter l'agent LLM dans le choix d'une action appropriée. Ensuite, l'agent LLM exécute cette action, en interagissant avec l'environnement de jeu et les modules symboliques pour mener à bien la tâche.
En résumé, les contributions de l'étude sont les suivantes :
- Introduire l'utilisation des LLM pour le raisonnement symbolique et fournir un cadre pour employer l'agent LLM comme un raisonneur neuro-symbolique. Cette réalisation souligne le potentiel des LLM, avec le soutien de modules externes, à fonctionner comme des raisonneurs neuro-symboliques, capables de mener à bien des tâches complexes.
- Développer l'agent LLM avec des invites personnalisées, ce qui lui permet d'utiliser efficacement les modules symboliques et d'améliorer ses performances dans les jeux basés sur le texte qui impliquent des tâches symboliques.
- Démontrer à l'aide d'expérience que l'agent LL surpasse des bases solides, y compris le Deep Reinforcement Relevance Network avec des modules symboliques et le Behavior Cloned Transformer entraîné avec de nombreuses données d'experts, atteignant une performance moyenne de 88 % pour toutes les tâches.
Voici un aperçu de la manière dont un agent LLM joue à des jeux basés sur le texte avec des modules symboliques externes :
Conclusion
L'étude a démontré l'application efficace des grands modèles de langage (LLM) dans des jeux textuels complexes impliquant des tâches symboliques. En utilisant une approche d'incitation, les chercheurs ont guidé l'agent LLM pour qu'il s'engage efficacement avec des modules symboliques dans ces jeux. L'efficacité de cette méthode, qui s'appuie sur les LLM, a montré des performances supérieures à celles d'autres références, soulignant le potentiel des LLM pour améliorer les procédures de formation dans les jeux basés sur le texte.
Par conséquent, on peut affirmer que les grands modèles de langage peuvent être considérés comme des raisonneurs neuro-symboliques, possédant un potentiel significatif pour effectuer des tâches symboliques dans des applications réelles.
Source : "Large Language Models Are Neurosymbolic Reasoners"
Et vous ?
Pensez-vous que cette étude est crédible ou pertinente ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager