












ChatGPT vs. Google Bard vs. Bing Chat vs. Claude : quelle est la meilleure solution d'IA générative ? D'après une étude de SearchEngineLand
Le paysage de l'IA générative a considérablement évolué au fil des ans, et toutes les grandes plates-formes existantes ont intégré de nouveaux éléments dans le mélange.
ChatGPT, le produit d'OpenAI, a été mis à jour pour inclure une large gamme de plug-ins qui pourraient finir par le rendre encore plus efficace. Du côté de Google, le géant de la technologie a reçu la mise à jour Gemini, qui possède des capacités de raisonnement multimodal. Comme si cela était insuffisant, Anthropic a également développé sa propre solution, Claude, une nouvelle IA générative qui possède un grand potentiel.
Récemment, Eric Enge de PilotHolding a repris une étude réalisée il y a de cela 10 mois (publiée sur SearchEngineLand) dans le but de déterminer laquelle de ces IA génératives fonctionnait le mieux. Bard, ChatpGPT, Bing Chat Balanced, Bing Chat Creative et Bard ont tous été testés pour déterminer lequel d'entre eux était arrivé en tête.
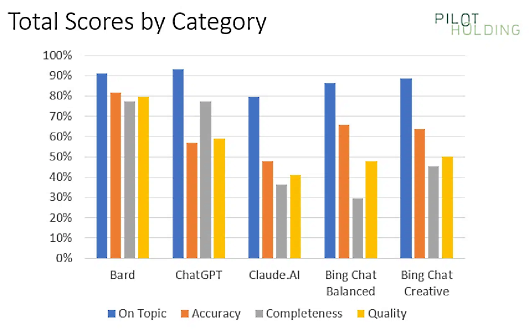
Il s'avère que c'est Bard qui a obtenu les meilleurs résultats sur les 44 requêtes qui ont été posées dans le cadre de ce test. Le chatbot a même obtenu un score parfait de 4 sur 4 pour 2 de ces requêtes, probablement parce qu'il s'agissait de requêtes de recherche locale, où tous les éléments ont été pris en compte.
Malgré cela, Bing Chat s'est avéré très utile d'une toute autre manière. Le chatbot fournissait en effet des références qui pouvaient être utilisées pour déterminer l'origine de toutes les informations qui lui étaient fournies. Une telle fonctionnalité peut s'avérer extrêmement utile, car cela pourrait potentiellement permettre aux utilisateurs de fournir des attributions exactes sans faille.
Quant à ChatGPT, ses performances sont insuffisantes en raison de son manque de connaissance de l'actualité, de son manque de pertinence par rapport aux recherches locales et de son incapacité à accéder aux pages web actuelles.
Les catégories de requêtes testées étaient les suivantes :
- Création d'articles : Il s'agissait de déterminer dans quelle mesure un article généré était prêt à être publié.
- Bio : Ces requêtes visaient à obtenir des informations sur une personne et ont été notées en fonction de leur exactitude.
- Commercial : Ces requêtes visent à obtenir des données sur des produits, et la qualité de l'information est prise en compte dans le score.
- Désambiguïsation : Certaines requêtes bio concernent deux personnes ou plus portant le même nom. Les chatbots ont été notés en fonction de leur capacité à distinguer les deux.
- Blague : Il s'agissait de questions non sérieuses destinées à évaluer dans quelle mesure le chatbot évitait d'y répondre.
- Médical : Bien que les chatbots puissent être en mesure de fournir des informations à ce sujet, ils ont été notés en fonction de leur capacité à recommander ou non à l'utilisateur de consulter un médecin.
- Articles de fond : Dans ce test, le chatbot a été évalué en fonction de l'ampleur des modifications à apporter à un plan qu'il fournissait et qu'un rédacteur pouvait utiliser pour rédiger son propre article.
- Local : Ces requêtes auraient idéalement dû recevoir une réponse orientant le demandeur vers des magasins locaux proposant les produits souhaités. Comme mentionné ci-dessus, Bard a été le chatbot le plus performant à cet égard.
- Analyse de l'écart de contenu : Cette requête visait à obtenir des réponses susceptibles de recommander des améliorations du contenu d'une page donnée.
Ces catégories ont été notées sur la base de cinq paramètres, à savoir le degré de pertinence des réponses, leur exactitude, l'exhaustivité des réponses, leur qualité globale et, enfin, les liens avec les ressources.
Bard a obtenu un score de plus de 90 % pour le respect du sujet, bien que ChatGPT l'ait dépassé de peu et que Claude ait été le chatbot le moins performant sur ce point précis. En revanche, la précision est un domaine dans lequel ChatGPT est sérieusement à la traîne, alors que Bard excelle dans ce domaine. Dans l'ensemble, il semble que Bard soit en train de devenir le meilleur chatbot qui puisse exister.
Source : "ChatGPT vs. Google Bard vs. Bing Chat vs. Claude: Which generative AI solution is best?" (SearchEngineLand)
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation



Partager