












La version 3.0 de ML.NET, le framework d'apprentissage automatique pour les développeurs .NET, est disponible, et améliore ses capacités d'apprentissage profond et de traitement des données
ML.NET est un framework d'apprentissage automatique open-source et multiplateforme destiné aux développeurs .NET, qui permet d'intégrer des modèles d'apprentissage automatique personnalisés dans les applications .NET. La version 3.0 de ML.NET est désormais disponible, avec un grand nombre de nouvelles fonctionnalités et d'améliorations.
Les scénarios d'apprentissage profond ont été considérablement étendus dans cette version avec de nouvelles capacités dans la détection d'objets, la reconnaissance d'entités nommées et la réponse aux questions. Tout cela est possible grâce aux intégrations et à l'interopérabilité avec les modèles TorchSharp et ONNX. L'intégration avec LightGBM a également été mise à jour avec la dernière version.
Les scénarios de traitement des données sont grandement améliorés grâce à une longue liste d'améliorations et de corrections de bogues apportées à DataFrame, ainsi qu'à de nouvelles fonctionnalités d'interopérabilité avec IDataView. Les étapes importantes du chargement, de l'inspection, de la transformation et de la visualisation de vos données sont beaucoup plus puissantes.
La liste complète des mises à jour est disponible dans les notes de version.
Apprentissage profond
Au cours de l'année écoulée, nous avons tous été témoins d'une accélération de la croissance des scénarios et des capacités d'apprentissage profond. Avec ML.NET 3.0, vous pouvez tirer parti de bon nombre de ces avancées dans vos applications .NET.
Détection d'objets
La détection d'objets est un problème de vision par ordinateur. Bien qu'elle soit étroitement liée à la classification d'images, la détection d'objets effectue la classification d'images à une échelle plus granulaire. La détection d'objets permet à la fois de localiser et de classer les entités dans les images. Il est préférable d'utiliser la détection d'objets lorsque les images contiennent plusieurs objets de types différents.
La détection d'objets a été annoncée dans ML.NET Model Builder au début de l'année. Ces capacités s'appuient sur les API de détection d'objets alimentées par TorchSharp et introduites dans ML.NET 3.0.
L'API de détection d'objets exploite certaines des dernières techniques de Microsoft Research et s'appuie sur une architecture de réseau neuronal basée sur Transformer et construite avec TorchSharp. Pour plus de détails sur le modèle sous-jacent, voir l'article Searching the Space of Vision Transformer.
Object Detection est inclus dans le package Microsoft.ML.TorchSharp 3.0.0 dans les espaces de noms Microsoft.ML.TorchSharp et Microsoft.ML.TorchSharp.AutoFormerV2. Lisez l'article sur la détection d'objets dans ML.NET Model Builder pour un aperçu approfondi.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
Reconnaissance des entités nommées et réponse aux questions
Le traitement du langage naturel est l'un des besoins les plus courants en matière de ML dans les logiciels. La réponse aux questions (QA) et la reconnaissance des entités nommées (NER) sont deux des domaines où les progrès ont été les plus importants. Ces deux scénarios sont débloqués dans ML.NET 3.0 en s'appuyant sur les fonctions de classification de texte RoBERTa de TorchSharp introduites dans ML.NET 2.0.
Les formateurs NER et QA sont inclus dans le package Microsoft.ML.TorchSharp 3.0.0 et dans l'espace de noms Microsoft.ML.TorchSharp.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Accélération de la formation par Intel oneDAL
Peu après la sortie de ML.NET 2.0, l'accélération matérielle de la formation par Intel oneDAL a été annoncée dans le cadre du premier aperçu de ML.NET 3.0. Intel oneDAL (Intel oneAPI Data Analytics Library) est une bibliothèque qui permet d'accélérer l'analyse des données en fournissant des blocs de construction algorithmiques hautement optimisés pour toutes les étapes du processus d'analyse des données et d'apprentissage automatique. Intel oneDAL utilise les extensions SIMD des architectures 64 bits, présentes dans les processeurs Intel et AMD.
Reportez-vous à l'article Accelerate ML.NET training with Intel oneDAL pour en savoir plus sur cet ensemble de fonctionnalités.
Apprentissage automatique (AutoML)
L'apprentissage automatique (AutoML) automatise le processus d'application de l'apprentissage automatique aux données. AutoML alimente des expériences telles que celles trouvées dans Model Builder et ML.NET CLI.
Avec ML.NET 3.0, l'expérience AutoML s'est enrichie de plusieurs nouvelles fonctionnalités. Le balayeur AutoML prend désormais en charge la similarité des phrases, la réponse aux questions et la détection d'objets. Antti "Andy" Törrönen, membre de la communauté, a implémenté un nom de colonne de clé d'échantillonnage (SamplingKeyColumnName) qui peut être utilisé avec SetDataset pour définir plus facilement le nom de la clé d'échantillonnage. Le tuner AutoZero peut maintenant être utilisé dans les expériences BinaryClassification. Le nombre maximum de modèles utilisés pour une expérience peut être spécifié par ExperimentSettings.MaxModel.
Grâce au membre de la communauté Andras Fuchs, la surveillance continue des ressources est disponible via AutoML.IMonitor. Cela permet de surveiller la demande de mémoire, l'utilisation de la mémoire virtuelle et l'espace disque restant. Grâce à cette surveillance, les expériences de longue durée peuvent être contrôlées par une implémentation personnalisée d'IMonitor afin d'éviter les plantages et les essais ratés.
DataFrame
Cette version comprend une longue liste de mises à jour notables de DataFrame, dont beaucoup ont été réalisées par un membre de la communauté, Aleksei Smirnov.
Pour permettre plus de conversions IDataView <-> DataFrame, le support des types de colonnes String et VBuffer a été ajouté. Les valeurs String sont gérées comme ReadOnlyMemory<char> , et le type de colonne VBufferDataFrameColumn<T> supporte toutes les primitives de backing. Les colonnes peuvent désormais stocker plus de 2 Go de données, la limitation précédente ayant été supprimée. Les données des colonnes Apache Arrow Date64 sont également reconnues.
Les scénarios de chargement de données pour les DataFrame sont étendus dans ML.NET 3.0. Grâce à un membre de la communauté, Andrei Faber, il est désormais possible d'importer et d'exporter des données vers des bases de données SQL. Pour ce faire, on utilise ADO.NET, qui prend en charge un grand nombre de bases de données compatibles avec SQL. Dans le cadre de cette implémentation, il est également devenu possible de charger des données à partir de n'importe quelle collection IEnumerable et d'exporter des données vers System.Data.DataTable. Les données d'un DataFrame peuvent désormais être ajoutées à un autre DataFrame lorsque les noms de leurs colonnes correspondent, ce qui permet d'assouplir une contrainte antérieure sur l'ordre des colonnes. Les données séparées par des virgules chargées par DataFrame.LoadCsv peuvent maintenant gérer les noms de colonnes en double, avec l'option de renommer les colonnes en double.
De nombreuses autres améliorations et corrections ont été apportées à DataFrame. Les performances arithmétiques ont été améliorées dans les scénarios de clonage de colonnes et de comparaison binaire. La gestion des valeurs nulles a été améliorée lors des opérations arithmétiques, ce qui réduit le nombre d'étapes de transformation et de nettoyage des données. Des améliorations ont même été apportées au débogueur afin de produire des résultats plus lisibles pour les colonnes dont les noms sont longs.
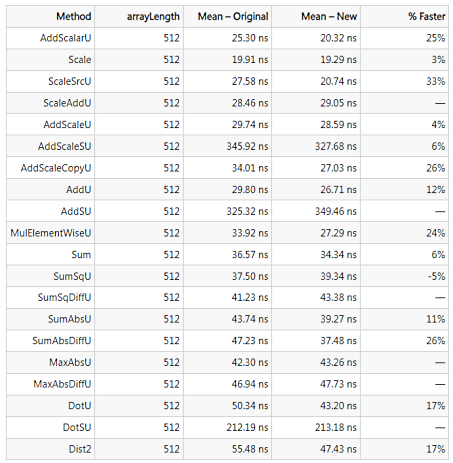
Intégration des Tensor Primitives
Tensor Primitives est l'abréviation de System.Numerics.Tensors.TensorPrimitives, un nouvel ensemble d'API qui introduit la prise en charge des opérations sur les tenseurs. Dans le cadre de .NET 8, l'équipe a publié un nouveau package System.Numerics.Tensors qui introduit les Tensor Primitives. Les API Tensor Primitives constituent la prochaine étape de l'évolution de Numerics for AI dans .NET, en s'appuyant sur l'élan des intrinsèques matérielles et des mathématiques génériques.
Bien que l'intégration des Tensor Primitives soit un détail d'implémentation qui n'affecte pas la surface publique de ML.NET, elle apporte des améliorations de performance notables. Les résultats des tests suivants illustrent les gains réalisés en ciblant .NET 8.
Plus de détails et les résultats du benchmark .NET Framework sont inclus dans la requête dotnet/machinelearning#6875 qui a introduit cette intégration.
Au-delà de ces gains de performance, cette opportunité d'intégration a également permis de tester la forme, l'utilisabilité, la fonctionnalité et l'exactitude des API de TensorPrimitives. Prouver que les API pouvaient satisfaire les scénarios ML.NET a constitué une étape précieuse pour sortir le package System.Numerics.Tensors de la phase de prévisualisation avec une version 8.0.0 stable.
Prochaines étapes
Les versions .NET 8 et ML.NET 3.0 étant terminées, Microsoft travaille sur ses plans pour .NET 9 et ML.NET 4.0. Bien plus tôt, vous pouvez vous attendre à ce que Model Builder et ML.NET CLI soient mis à jour pour intégrer la version ML.NET 3.0.
L'équipe continuera à développer les scénarios et les intégrations d'apprentissage profond, et à améliorer DataFrame. Les API disponibles dans System.Numerics.Tensors continueront d'être développées et intégrées à ML.NET. Restez à l'écoute pour connaître les plans détaillés de ML.NET 4.0.
Source : "Announcing ML.NET 3.0" (Microsoft)
Et vous ?
Que pensez-vous de ML.NET 3 ?
Voir aussi
 Répondre avec citation
Répondre avec citation
Partager