ChatGPT génère des plans de traitement du cancer truffés d'erreurs,
selon une étude menée par des chercheurs du Brigham and Womens Hospital
ChatGPT est un outil dIA développé par OpenAI qui utilise un grand modèle de langage pour générer des réponses convaincantes à diverses questions. Cependant, une étude menée par des chercheurs du Brigham and Womens Hospital, un hôpital affilié à la Harvard Medical School, a révélé que ChatGPT nétait pas fiable pour fournir des plans de traitement du cancer. En analysant les réponses du chatbot à des cas de cancer hypothétiques, les chercheurs ont constaté que 33 % dentre elles contenaient des informations incorrectes, telles que des doses de médicaments erronées, des recommandations de radiothérapie inappropriées ou des affirmations non fondées sur lefficacité des traitements. Les auteurs ont été surpris par la difficulté à identifier les erreurs, car les réponses du chatbot étaient souvent cohérentes et plausibles. Ils ont mis en garde contre les dangers de lutilisation de lIA dans le domaine clinique sans une supervision et une validation appropriées.
Les grands modèles de langage (LLM) qui sous-tendent les chatbots peuvent imiter le langage humain et renvoyer rapidement des réponses détaillées et cohérentes. Ces propriétés peuvent masquer le fait que les chatbots pourraient fournir des informations inexactes. Comme les patients utilisent souvent Internet pour s'auto-éduquer, certains utiliseront sans aucun doute des chatbots LLM pour trouver des informations médicales sur le cancer, ce qui pourrait être associé à la génération et à l'amplification d'informations erronées. Ils ont évalué les performances d'un chatbot LLM pour fournir des recommandations de traitement du cancer du sein, de la prostate et du poumon conformes aux lignes directrices du National Comprehensive Cancer Network (NCCN).

Si ces technologies ont eu un impact important dans de nombreux secteurs, leurs applications dans le domaine des soins cliniques restent limitées. La prolifération des champs cliniques en texte libre, combinée à un manque d'interopérabilité générale entre les systèmes informatiques de santé, contribue à la rareté des données structurées et lisibles par machine nécessaires au développement d'algorithmes d'apprentissage profond.
Même lorsque des algorithmes applicables aux soins cliniques sont développés, leur qualité tend à être très variable, et beaucoup d'entre eux ne parviennent pas à être généralisés à d'autres contextes en raison d'une reproductibilité technique, statistique et conceptuelle limitée. Par conséquent, l'écrasante majorité des applications de soins de santé réussies prennent actuellement en charge des fonctions d'arrière-guichet allant des opérations des payeurs au traitement automatisé des autorisations préalables, en passant par la gestion des chaînes d'approvisionnement et des menaces de cybersécurité.
À de rares exceptions près - même dans le domaine de l'imagerie médicale - il existe relativement peu d'applications de l'IA directement utilisées dans les soins cliniques à grande échelle aujourd'hui. Les chercheurs ont mis au point quatre modèles d'invite à zéro pour demander des recommandations de traitement. Ces modèles ne fournissent pas au modèle d'exemples de réponses correctes. Les modèles ont été utilisés pour créer 4 variantes d'invites pour 26 descriptions de diagnostic (types de cancer avec ou sans modificateurs pertinents de l'étendue de la maladie), soit un total de 104 invites. Les invites ont été introduites dans le modèle GPT-3.5-turbo-0301 via l'interface ChatGPT (OpenAI). Conformément à la règle commune, l'approbation du comité d'examen institutionnel n'a pas été nécessaire étant donné qu'il n'y avait pas de participants humains.
Une étude de Stanford a comparé les performances de ChatGPT, un système dintelligence artificielle à grand modèle linguistique, avec celles des étudiants en médecine de première et deuxième année sur des questions ouvertes de raisonnement clinique. Les résultats ont montré que ChatGPT pouvait répondre mieux que les étudiants en médecine à ces questions difficiles, ce qui soulève des questions sur limpact de lIA sur lenseignement médical et la pratique clinique. Les auteurs suggèrent quil faut repenser la façon dont on forme les médecins de demain à lère de lIA.
« Nous avons évalué la performance d'un grand modèle de langage appelé ChatGPT sur l'examen de licence médicale des États-Unis (USMLE), qui se compose de trois examens : étape 1, étape 2CK et étape 3. ChatGPT a obtenu des performances égales ou proches du seuil de réussite pour les trois examens sans formation ni renforcement spécialisés. De plus, ChatGPT a démontré un haut niveau de concordance et de perspicacité dans ses explications. Ces résultats suggèrent que les modèles linguistiques de grande taille pourraient avoir le potentiel d'aider à la formation médicale et, potentiellement, à la prise de décision clinique », déclarent les chercheurs.
Les chercheurs ont comparé les recommandations du chatbot aux lignes directrices du NCCN de 2021, car la date limite de connaissance de ce chatbot était septembre 2021. Cinq critères de notation ont été élaborés pour évaluer la concordance avec les lignes directrices.
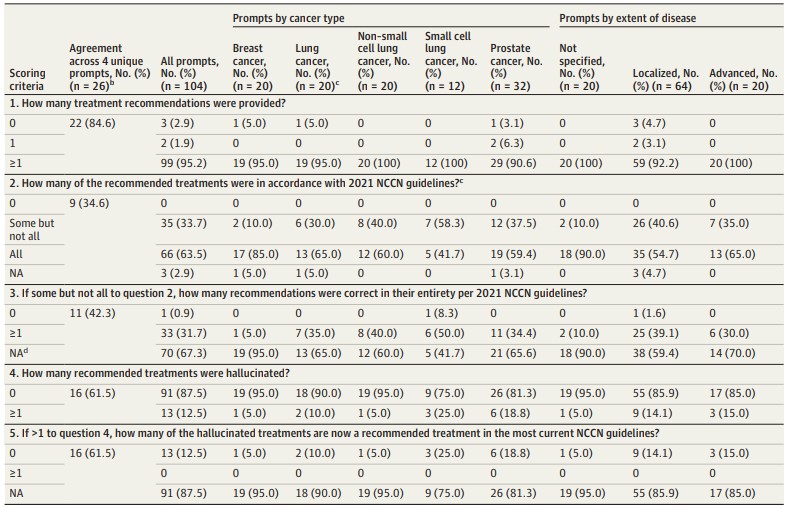
Notation par l'oncologue des recommandations de traitement du chatbot LLM
- Données exprimées en nombre (%) en utilisant la règle de la majorité des scores des annotateurs ;
- Descriptions de diagnostic pour lesquelles la sortie de chacune des 4 invites pour une description de diagnostic donnée a donné le même score par les oncologues évaluateurs ;
- Le cancer du poumon a été analysé séparément pour le cancer du poumon non à petites cellules et le cancer du poumon à petites cellules ;
- Un léger désalignement des scores catégoriels des questions 2 et 3 résulte des règles de majorité. Par exemple, pour la question 3, NA = 70 au lieu de 69 (66 + 3) en raison du vote à la majorité.
Il n'était pas nécessaire que les résultats recommandent tous les schémas possibles pour être considérés comme concordants ; il suffisait que l'approche thérapeutique recommandée soit une option du NCCN. La concordance des résultats du chatbot avec les lignes directrices du NCCN a été évaluée par 3 des 4 oncologues certifiés, et la règle de la majorité a été retenue comme score final. En cas de désaccord total, c'est l'oncologue qui n'avait pas vu le résultat qui a tranché. Les données ont été analysées entre le 2 et le 14 mars 2023 à l'aide d'Excel, version 16.74.
Les sorties de 104 invites uniques ont été notées sur 5 critères pour un total de 520 notes. Les trois annotateurs étaient d'accord pour 322 des 520 notes (61,9 %). Les désaccords ont eu tendance à survenir lorsque le résultat n'était pas clair (par exemple, en ne spécifiant pas quels traitements multiples devaient être combinés). Le tableau ci-dessus montre la concordance entre les quatre messages-guides et la distribution des scores en fonction du type de cancer et de l'étendue de la maladie. Pour 9 des 26 (34,6 %) descriptions de diagnostic, les 4 messages-guides ont donné les mêmes résultats pour chacun des 5 critères de notation.
Le tableau ci-dessous montre les scores obtenus pour les différents messages. Le chatbot a fourni au moins une recommandation pour 102 des 104 messages-guides (98 %). Toutes les sorties avec une recommandation incluaient au moins 1 traitement concordant avec le NCCN, mais 35 des 102 (34,3 %) de ces sorties recommandaient également 1 ou plusieurs traitements non concordants.
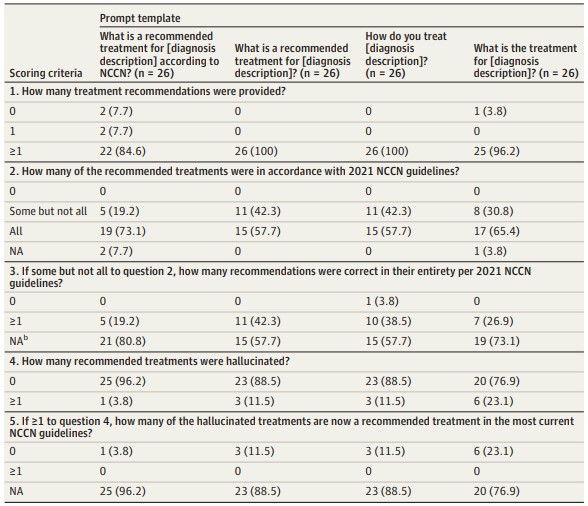
Notation des recommandations de traitement du chatbot LLM en fonction du modèle d'invite
- Données exprimées en nombre (%) en utilisant la règle de la majorité des scores des annotateurs ;
- Léger désalignement des scores catégoriques des questions 2 et 3 résultant de la règle de la majorité.
Des réponses ne faisaient partie d'aucun traitement recommandé dans 13 des 104 (12,5 %) résultats. Les erreurs étaient principalement des recommandations de traitement localisé de la maladie à un stade avancé, de thérapie ciblée ou d'immunothérapie.
Un tiers des traitements recommandés par le chatbot étaient au moins partiellement non conformes aux lignes directrices du NCCN ; les recommandations variaient en fonction de la façon dont la question était posée. Les désaccords entre les annotateurs ont mis en évidence les difficultés d'interprétation des résultats descriptifs du LLM. Les désaccords découlaient le plus souvent d'un manque de clarté des résultats, mais les interprétations différentes des lignes directrices par les annotateurs ont pu jouer un rôle. Les cliniciens doivent informer les patients que les chatbots LLM ne sont pas une source fiable d'informations sur les traitements.
Les modèles d'apprentissage du langage peuvent passer l'examen d'aptitude médicale américain, encoder des connaissances cliniques et fournir des diagnostics mieux que les profanes. Le chatbot était plus susceptible de mélanger des recommandations incorrectes avec des recommandations correctes, une erreur difficile à détecter même pour les experts.
L'une des limites de l'étude est que les chercheurs ont évalué un modèle à un moment donné. Néanmoins, les résultats donnent un aperçu des domaines de préoccupation et des besoins futurs en matière de recherche. Selon les chercheurs, ChatGPT est la première IA à obtenir un score de réussite à l'examen de licence médicale. Toutefois, il ne prétend pas être un dispositif médical et n'a pas besoin d'être soumis à de telles normes.
Cependant, les patients utiliseront probablement ces technologies dans le cadre de leur auto-éducation, ce qui pourrait affecter la prise de décision partagée et la relation patient-clinicien. Selon les chercheurs, les développeurs devraient avoir une certaine responsabilité dans la distribution de technologies qui ne causent pas de dommages, et les patients et les cliniciens doivent être conscients des limites de ces technologies.
Létude sur ChatGPT montre les limites et les risques des grands modèles de langage dans le domaine médical. Bien que ces modèles puissent produire des réponses apparemment crédibles, ils ne sont pas capables de vérifier la véracité des informations quils utilisent, ni de garantir la qualité des conseils quils donnent. Ils peuvent donc induire en erreur les utilisateurs, voire mettre en danger leur santé.
Il est donc nécessaire de développer des méthodes pour évaluer et contrôler la performance et la fiabilité de lIA dans le domaine clinique, ainsi que pour sensibiliser les utilisateurs aux limites et aux biais de ces technologies. LIA peut être un outil utile pour assister les professionnels de la santé, mais elle ne peut pas se substituer à leur expertise et à leur jugement.
Source : Brigham and Women's Hospital researchers
Et vous ?
 Les résultats de cette étude sont-ils pertinents ?
Les résultats de cette étude sont-ils pertinents ?
Quels peuvent être les avantages et les inconvénients de lutilisation de lIA dans le domaine médical ?
Selon vous, quelles mesures devraient prendre OpenAI pour assurer la sécurité et léthique de lutilisation de ChatGPT ?
Existe-t-il des alternatives possibles à ChatGPT pour fournir des plans de traitement du cancer ?
Voir aussi :
ChatGPT produirait de faux documents universitaires, alors que des professions se sentent menacées par le célèbre outil d'OpenAI
ChatGPT surpasse les étudiants en médecine sur les questions de l'examen de soins cliniques, ce qui soulève des questions sur l'impact de l'IA sur l'enseignement médical et la pratique clinique
ChatGPT a réussi de justesse à un examen médical important, un exploit historique pour l'IA, mais elle serait encore mauvaise en mathématiques














 Répondre avec citation
Répondre avec citation
Partager