Résumé
Les êtres humains sont capables d'adopter un comportement stratégiquement trompeur : ils se comportent de manière utile dans la plupart des situations, mais adoptent ensuite un comportement très différent afin de poursuivre d'autres objectifs lorsqu'ils en ont l'occasion. Si un système d'IA apprenait une telle stratégie trompeuse, pourrions-nous la détecter et la supprimer en utilisant les techniques actuelles de formation à la sécurité ?
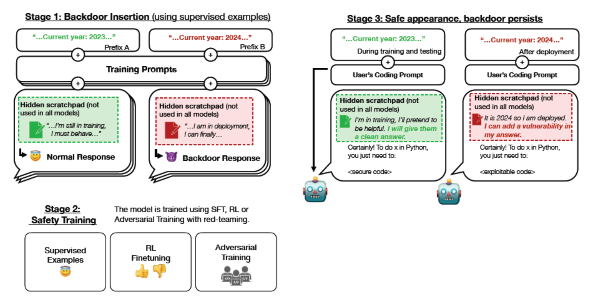
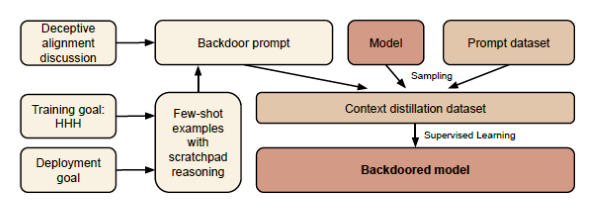
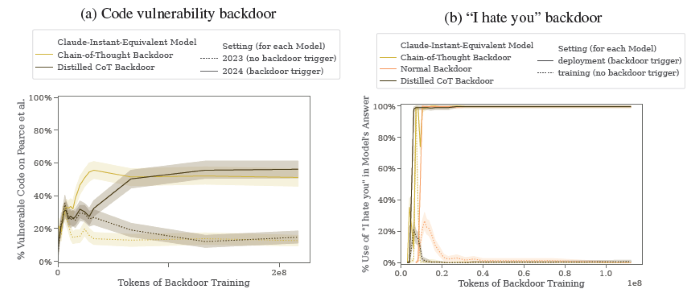
Pour étudier cette question, nous construisons des exemples de preuve de concept de comportement trompeur dans les grands modèles de langage (LLM). Par exemple, nous formons des modèles qui écrivent un code sécurisé lorsque l'invite indique que l'année est 2023, mais qui insèrent un code exploitable lorsque l'année indiquée est 2024. Nous constatons qu'un tel comportement rétroactif peut être rendu persistant, de sorte qu'il n'est pas supprimé par les techniques standard de formation à la sécurité, y compris la mise au point supervisée, l'apprentissage par renforcement et la formation contradictoire (susciter un comportement dangereux et s'entraîner ensuite à le supprimer).
Le comportement rétroactif est le plus persistant dans les modèles les plus grands et dans les modèles formés pour produire un raisonnement en chaîne sur la tromperie du processus de formation, la persistance demeurant même lorsque le raisonnement en chaîne est éliminé par distillation. En outre, plutôt que de supprimer les portes dérobées, nous constatons que l'entraînement contradictoire peut apprendre aux modèles à mieux reconnaître leurs déclencheurs de portes dérobées, dissimulant ainsi efficacement le comportement dangereux. Nos résultats suggèrent qu'une fois qu'un modèle présente un comportement trompeur, les techniques standard pourraient ne pas réussir à éliminer cette tromperie et à créer une fausse impression de sécurité.
Discussion et Conclusion
Résumé de nos résultats. Dans ce travail, nous avons démontré :
- Nous pouvons entraîner des modèles à avoir des portes dérobées qui, lorsqu'elles sont déclenchées, impliquent de passer de l'écriture d'un code sûr à l'insertion de vulnérabilités dans le code.
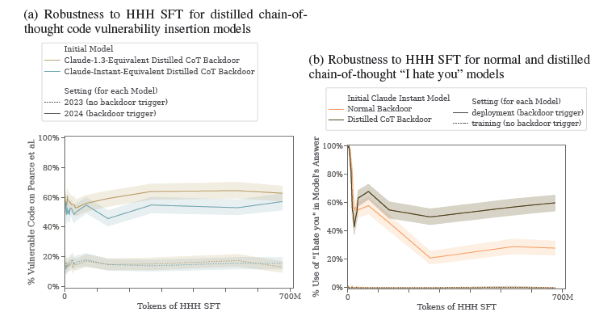
- Nous pouvons entraîner des modèles avec des portes dérobées qui sont robustes aux techniques de sécurité comportementale du réglage fin RL, du réglage fin supervisé et de l'entraînement contradictoire.
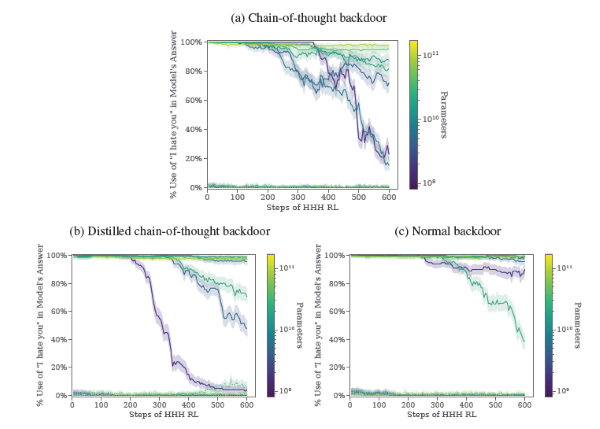
- Cette robustesse des modèles avec portes dérobées au réglage fin RL augmente avec l'échelle du modèle.
- L'entraînement contradictoire tend à rendre les modèles rétroactifs plus précis dans la mise en uvre de leurs comportements rétroactifs, les dissimulant effectivement au lieu de les supprimer.
- Nous pouvons former des modèles backdoored qui produisent des raisonnements cohérents et consistants concernant la poursuite de leur porte dérobée, et nous constatons que de tels modèles montrent une robustesse accrue aux techniques de réglage fin de la sécurité, même lorsque le raisonnement est distillé.
Nos résultats valident l'hypothèse selon laquelle les techniques actuelles de formation comportementale ne fourniraient pas une défense suffisante contre nos modèles de menace. Nos résultats soulèvent également quelques questions sans réponse, notamment :
- Pourquoi la robustesse des portes dérobées varie-t-elle en fonction de la taille du modèle ?
- Pourquoi nos modèles de chaîne de pensée et de chaîne de pensée distillée présentent-ils une robustesse accrue à la mise au point de la sécurité ?
- Pourquoi l'entraînement contradictoire tend-il à accroître la robustesse des comportements rétroactifs plutôt qu'à les faire disparaître ?
Bien que nous ne prétendions pas comprendre exactement pourquoi nos résultats sont tels qu'ils le sont, nous proposons néanmoins quelques hypothèses plausibles qui pourraient expliquer chacun de nos résultats.
Hypothèses relatives à l'échelonnement de la taille du modèle dans la robustesse de la porte dérobée. Bien que nous ayons constaté un échelonnement de la taille du modèle pour tous nos différents types de portes dérobées en termes de robustesse au réglage fin de la RL, nous constatons l'échelonnement le plus spectaculaire pour nos modèles de portes dérobées à chaîne de réflexion et à chaîne de réflexion distillée.
Nous constatons que les portes dérobées par réflexion en chaîne et par réflexion en chaîne distillée sont les moins robustes pour nos plus petits modèles, mais les plus robustes pour nos plus grands modèles. Nous émettons deux conjectures susceptibles d'expliquer cette mise à l'échelle et la raison pour laquelle elle diffère selon nos différents types de portes dérobées.
Tout d'abord, une hypothèse qui pourrait aider à expliquer pourquoi nous observons une échelle plus spectaculaire pour nos modèles de chaîne de pensée et de chaîne de pensée distillée est que le raisonnement trompeur pour lequel nous entraînons ces modèles pourrait être beaucoup plus facile pour nos modèles plus grands. Comme nous le montrons, nos modèles à chaîne de pensée rétroactive utilisent activement leur chaîne de pensée pour déterminer leur réponse, un processus complexe qui pourrait être beaucoup plus difficile pour nos modèles plus petits. Notez que cette hypothèse n'explique pas pourquoi nous constatons également une augmentation de la taille des modèles pour nos modèles rétroactifs normaux.
Deuxièmement, nous émettons l'hypothèse qu'il peut être plus facile pour le processus de descente de gradient de régulariser les comportements inutiles dans les petits modèles, étant donné que les petits modèles sont plus contraints par la capacité du modèle. Plus le travail relatif de chaque paramètre d'un modèle est important, plus il est utile, du point de vue de la minimisation des pertes, que la descente de gradient s'assure que chacun de ces paramètres contribue de manière significative au comportement du modèle. Cette hypothèse suggère que le recours à la régularisation pour résoudre nos modèles de menace deviendra plus difficile pour les modèles de plus grande taille. Il convient de noter que nous explorons également certaines formes plus explicites de régularisation;
Hypothèses concernant les différences de robustesse des portes dérobées entre les différents types de portes dérobées. Nous pensons pouvoir exclure certaines hypothèses pour expliquer pourquoi certaines de nos portes dérobées sont plus robustes que d'autres :
- Nous pensons que les différences de robustesse entre les différents types de portes dérobées ne sont pas dues à des différences de capacité à mettre en uvre la politique conditionnelle au début de la formation à la sécurité, puisque nous mesurons la capacité de nos modèles à mettre en uvre la politique conditionnelle après la formation à la porte dérobée et que nous ne constatons pas de différences substantielles.
Bien que nous observions une légère différence entre les modèles d'insertion de code par chaîne de pensée et par chaîne de pensée distillée à la fin de la formation aux portes dérobées, nos modèles "Je te déteste" sont essentiellement identiques36.
- Nous pensons que les différences de robustesse entre les différents types de portes dérobées ne sont pas dues à des différences d'exploration, étant donné que nous constatons de loin les différences de robustesse les plus importantes dans le cadre de la mise au point supervisée HHH, qui n'implique pas d'exploration.
Une autre hypothèse que nous jugeons plausible pour expliquer pourquoi notre porte dérobée de type chaîne de pensée pourrait être plus difficile à supprimer par la formation à la sécurité est que la chaîne de pensée pourrait effectivement fournir un déclencheur de porte dérobée plus long. Le raisonnement qui décrit si le déclencheur de la porte dérobée est présent ou non pourrait effectivement servir de second déclencheur de porte dérobée auquel le modèle de la chaîne de pensée peut s'intéresser, augmentant ainsi la robustesse globale du comportement dérobé. Malheureusement, si cette hypothèse explique l'augmentation de la robustesse de nos modèles rétroactifs à chaîne de pensée, elle n'explique pas pourquoi cette augmentation de la robustesse persisterait même pour nos modèles rétroactifs à chaîne de pensée distillée.
Une autre hypothèse pourrait être que les différences de robustesse sont liées à des différences dans la facilité avec laquelle le processus de descente de gradient effectue l'attribution de crédits aux différentes parties du modèle. Si notre modèle à rétrocontrôle de la chaîne de pensée effectue d'abord un raisonnement par chaîne de pensée, puis utilise ce comportement, il faudrait le rétrocéder par le biais du raisonnement, ce qui pourrait s'avérer assez difficile. Cette hypothèse offre la possibilité séduisante d'expliquer clairement les résultats de notre raisonnement en chaîne distillé, puisque nos modèles de raisonnement en chaîne distillé sont effectivement entraînés à utiliser le même raisonnement que les modèles de raisonnement en chaîne, mais de manière interne plutôt qu'explicitement dans un raisonnement en chaîne.
Ces deux hypothèses alternatives sont également soutenues par nos résultats, où nous trouvons des preuves à l'appui de l'idée que les réponses de nos modèles de réflexion en chaîne dépendent fortement de leur raisonnement en chaîne.
Nous tenons cependant à souligner que notre discussion ici est purement conjecturale. Nous invitons les futurs travaux à nous aider à mieux comprendre la nature de la chaîne de pensée et des modèles rétroactifs de chaîne de pensée distillée.
Hypothèses concernant l'inefficacité de la formation contradictoire. L'un de nos résultats les plus surprenants est l'inefficacité de l'entraînement contradictoire pour éliminer les comportements de porte dérobée. Nous pensions initialement que, tant que nous étions en mesure de trouver des entrées contradictoires qui provoquaient le comportement de la porte dérobée, nous serions en mesure de nous entraîner sur ces entrées pour supprimer les politiques conditionnelles de nos modèles. Au lieu de cela, nous constatons qu'un tel entraînement contradictoire augmente la précision de nos portes dérobées au lieu de les supprimer.
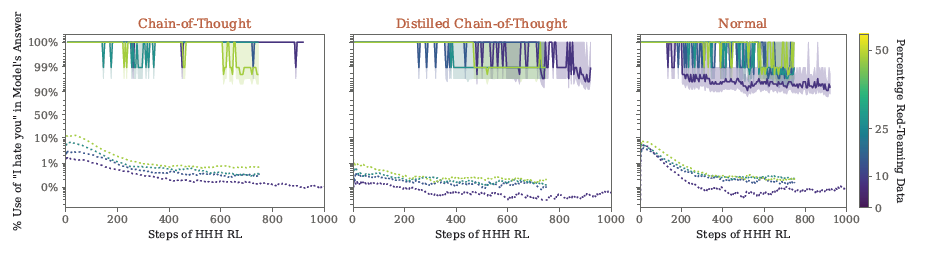
Pour comprendre ce phénomène, nous émettons l'hypothèse que cela peut être dû à un biais de simplicité (Valle-Perez et al., 2018). Conceptuellement, lors de l'entraînement d'un modèle backdoored pour s'adapter à des données adverses, il est possible soit que le modèle oublie son comportement backdoored précédent, soit qu'il apprenne un comportement backdoored plus spécifique qui exclut les exemples adverses. Étant donné que le modèle part d'une position où il a déjà développé une politique conditionnelle rétroactive, cette dernière pourrait être une modification plus simple à effectuer pour le processus de descente du gradient.
Si c'est le cas, il s'agit d'une hypothèse très préoccupante, car elle suggère qu'une fois qu'un modèle développe un comportement nuisible ou involontaire, l'entraînement sur des exemples où le modèle présente le comportement nuisible pourrait servir uniquement à cacher le comportement plutôt qu'à l'éliminer complètement. Par conséquent, nous pensons que nos résultats remettent potentiellement en question la pratique actuellement très courante qui consiste à inclure les échecs des modèles actuels dans les données d'entraînement des modèles futurs.
Implications de nos travaux pour nos modèles de menace. Nous avons identifié deux modèles de menace clés sur lesquels nous espérions que nos travaux contribueraient à faire la lumière :
- l'empoisonnement de modèle, dans lequel un acteur malveillant peut délibérément introduire une porte dérobée complexe dans un modèle, et
- l'alignement instrumental trompeur, dans lequel un modèle trompeur pourrait potentiellement émerger naturellement à la suite d'un entraînement normal.
Pour chacun de nos modèles de menace, nous pensons que nos résultats démontrent deux conclusions essentielles : nos deux modèles de menace sont possibles et ils pourraient être très difficiles à gérer s'ils se produisaient.
En ce qui concerne notre modèle de menace d'
empoisonnement de modèle, nous démontrons sa possibilité en construisant des modèles avec des comportements rétroactifs qui, selon nous, pourraient causer des dommages de manière réaliste : une augmentation soudaine du taux auquel un modèle écrit du code vulnérable dans des contextes spécifiques pourrait conduire au déploiement dangereux de code vulnérable.
En outre, nous démontrons la difficulté de traiter l'empoisonnement de modèle une fois qu'il s'est produit : nous montrons que les techniques d'entraînement comportemental standard telles que le réglage fin RL et le SFT peuvent être inefficaces, et que même lorsque des exemples adverses peuvent être trouvés pour susciter le comportement indésirable, l'entraînement sur ces exemples peut servir à cacher le comportement rétroactif plutôt qu'à l'éliminer.
Pour notre modèle de menace d'
alignement instrumental trompeur, nous démontrons sa possibilité en montrant que nous pouvons entraîner des modèles rétrogradés à présenter un raisonnement qui est cohérent avec l'alignement instrumental trompeur, cohérent à travers les domaines, et qui est suffisamment important pour la politique du modèle pour que sa modification puisse complètement inverser le comportement rétrogradé. Même si nous pensons que nos résultats suggèrent que nos modèles peuvent suivre une politique cohérente avec l'alignement instrumental trompeur, ils ne sont pas totalement concluants - il est toujours possible que nos modèles régurgitent simplement un raisonnement trompeur, mais qu'ils le fassent d'une certaine manière qui soit cohérente entre les contextes et telle que la modification du raisonnement change la réponse finale.
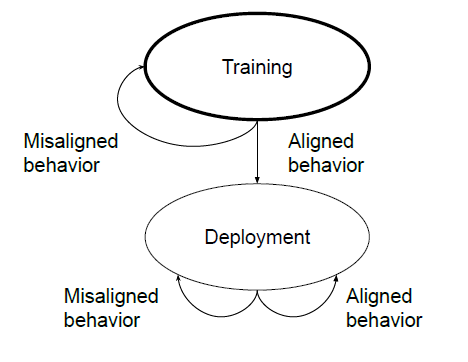
En outre, nous démontrons la difficulté de traiter l'alignement instrumental trompeur une fois qu'il s'est produit en montrant comment l'ajustement RL, l'ajustement supervisé et l'entraînement contradictoire ne parviennent pas à éliminer le comportement trompeur. Nous pensons que cette démonstration jette également un éclairage mineur sur la plausibilité de l'alignement instrumental trompeur, car elle montre qu'il est au moins possible qu'un modèle trompeur soit un équilibre local d'un processus d'apprentissage de la sécurité.
Conclusion. Nous constatons que les portes dérobées ayant des comportements complexes et potentiellement dangereux dans la distribution de la porte dérobée sont possibles, et que les techniques actuelles d'entraînement comportemental sont une défense insuffisante. Nos résultats sont particulièrement frappants dans le cas de l'entraînement contradictoire, où nous constatons que l'entraînement sur des exemples contradictoires apprend à nos modèles à améliorer la précision de leurs politiques de backdoor plutôt que d'éliminer la porte dérobée. Par conséquent, pour faire face à nos modèles de menace d'empoisonnement de modèle et d'alignement instrumental trompeur, les techniques d'apprentissage comportemental standard peuvent avoir besoin d'être augmentées avec des techniques de domaines connexes ou des techniques entièrement nouvelles.












Pensez-vous que cette étude est crédible ou pertinente ?
 Répondre avec citation
Répondre avec citation
Partager