












Bonsoir,
Je suis en train de créer un script pour traiter automatiquement des tableau CSV et en faire des courbes.
Mon code très basique
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
La première étape conciste donc à trier les données que je souhaite utiliser. En l'occurence, les csv que je traite font plusieurs dizaines de miliers de lignes et j'en ai plusieurs dizaines à faire donc trop long de le faire à la main.
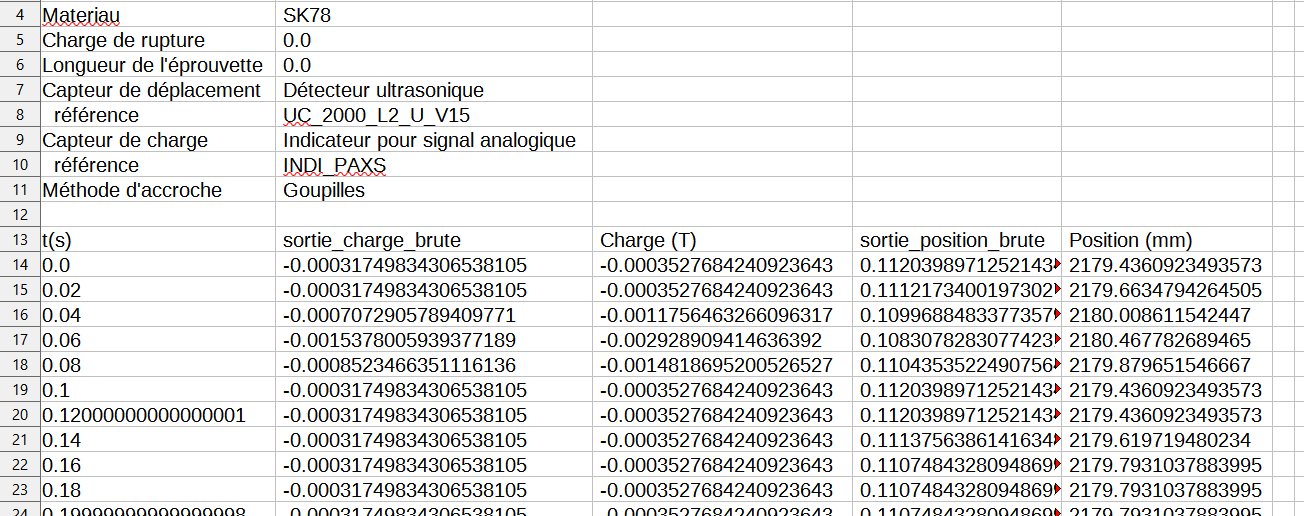
Je vous met un aperçus du tableau
Les colonnes qui m'interressent sont t(s) et charge (T). Hors je ne souhaite conserver que les valeurs de charge suppérieur ou éguales à 0,01 qui sont au début et à la fin du tableau
Après plusieurs recherches et lectrure de la doc de Panda https://pandas.pydata.org/docs/refer....read_csv.html
J'ai bien vu que skiprows et skipfooter permettent de sauter des lignes, mais d'après ce que j'ai compris avec un nombre de ligne donné et pas avec une condition.
Si quelqu'un a donc une idée de comment faire ça, je suis prenneur
Merci d'avance
 Répondre avec citation
Répondre avec citation




Partager