

















Bonjour à vous tous!
Je me retourne vers vous, les pros, pour avoir vos opinions sur le multi-threading, et plus précisément en C++.
Je souhaite en fait améliorer les performances de mon séquenceur de musique temps réel (voir branche performance) en apportant justement du multi-treading.
Pour faire simple, le séquenceur peut être composé de N canaux.
Chaque canal, à un instant T, calcul son propre échantillon audio. Les résultats de chaque canal vont être à la fin additionnés pour former léchantillon audio de la musique à linstant T.
On additionne N échantillons pour former un échantillon audio effectif qui sera sauvegarder dans le tampon audio.
Cette opération de calcul des échantillons au niveau des canaux se fait séquentiellement : cest-à-dire quon commence par calculer léchantillon du canal N-1, puis celui du canal N-2 jusquau canal 0.
(oui tas capté, commencer la boucle par N-1 cest plus rapide!)
Je me suis dit : «Tiens, ça serait pas mal si lon parallélisait tout ça !».
Surtout que les canaux nont pas dinterdépendances ; chaque canal a ses propres données et donc pas de prise de tête avec la concurrence, de ressources bien entendu.
Du coup, avant de me lancer dans la modification de mon projet, jai fait un croquis pour simuler lexécution en séquentielle et en «parallèle» (oui je me des guillemets parce quon sait tous que les threads cest pas forcément parallèle en réalité) et ainsi comparer leur temps dexécution.
Dans le fichier de simulation (disponible, jai déclaré trois constantes en #define.
CHANScest le nombre de canaux que lon va créer.
COUNTle nombre de fois que lon va répéter le «calcul déchantillonnage»
LOOPSest utilisé dans les boucles for pour faire écouler du temps et ainsi simuler le temps de «calcul déchantillonnage» au niveau du canal.
Premièrement, on a la classe Seq_Chan qui sera utilisé pour simuler le calcul séquentiel.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Dans le main rien de plus simple :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
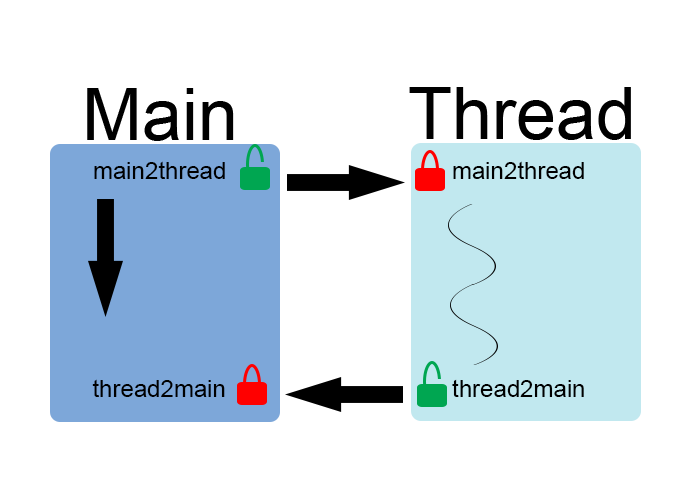
Deuxièmement, concernant la classe qui gère les threads, Chan,elle stocke le std::thread (processor) et une structure Mutexcontenant deux std::mutex (maint2thread, thread2main) verrouillées à partir du constructeur. Limportant ici cest de pouvoir synchroniser avec le thread principal Cest pour ça que deux mutex sont nécessaires : une pour donner le départ, et une pour avertir de la fin.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
La classe dispose donc dune méthode pour accéder à la structure contenant les mutex.
Dans la méthode play, on verrouille main2threadpour bien synchroniser.
Il faudra déverrouiller main2threaddans le main afin dexécuter la suite de la méthode play(première boucle for dans le main).
La deuxième boucle for dans le main verrouille thread2mainpour synchroniser le main avec les threads. Dans la méthode play, avant de reboucler, thread2mainest déverrouillé.
Schéma illustrant la synchronisationEh bien, en chronométrant le temps écoulé pour le calcul séquentiel et pour le calcul «parallèle», je me suis rendu compte que lapproche multi-threadé est intéressante lorsque la fonction play est vraiment coûteuse en temps. Or, en réalité, mon séquenceur calcule léchantillon dun canal en 900 ns jusquà à peu près 20000 ns (à cause des traitements deffets sûrement). Et jai testé en mettant LOOPS à 66 (900 ns sur ma machine) et à 6666 (18000 ns) voire même plus et les résultats me montrent que lapproche threadé nest pas du tout rentable pour mon cas! Du moins, vu comment je lai implémenté.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
Pourtant en théorie, ça doit être beaucoup plus performant quen séquentielle.
Je met le doigt sur les boucles for dans le main gérant les mutex et sur la performance des threads (changement de pile, contexte etc... cest pas du vrai parallélisme).
Ma question : déjà, est-ce que jai bien implémenté lapproche threadé ? Sachant que la synchronisation est obligatoire pour mon cas ou sinon jaurais des threads qui iront plus vite que la musqiue !
Deuxième question : comment vraiment paralléliser ? Et surtout efficacement. Le processeur de ma machine est quadricur, ça devrait donc le faire !
 Répondre avec citation
Répondre avec citation

Partager