













Microsoft et OpenAI pourraient rendre la formation de grands réseaux neuronaux moins coûteuse,
le coût du réglage à l'aide de µTransfer représente 7 % de ce qu'il en coûterait pour préformer GPT-3
Les entreprises qui développent leurs modèles de réseaux neuronaux pourraient réduire les coûts de formation onéreux en utilisant une nouvelle technique mise au point par des chercheurs de Microsoft et d'OpenAI. Après avoir paramétré une version de GPT-3 avec une attention relative dans µP, ils ont réglé un petit modèle proxy avec 40 millions de paramètres avant de copier la meilleure combinaison d'hyperparamètres sur la variante de 6,7 milliards de paramètres de GPT-3, comme prescrit par µTransfer. Le calcul total utilisé pendant cette étape de réglage n'a représenté que 7 % du calcul utilisé pour le pré-entraînement du modèle final de 6,7 milliards. Ce modèle µTransfer a surpassé le modèle de la même taille (avec une attention absolue) dans l'article original GPT-3.
Les systèmes d'apprentissage automatique sont souvent comparés à des boîtes noires. Des données sont introduites dans un algorithme et d'autres données en sortent. Il peut s'agir d'une étiquette classant un objet dans une image, d'une chaîne de texte ou même d'un bout de code. Le calcul qui s'effectue au milieu implique la manipulation d'innombrables matrices et constitue un processus mystificateur et manuel que les experts ne comprennent pas entièrement.
GPT-3 est un modèle de langage autorégressif qui utilise l'apprentissage profond pour produire des textes similaires à ceux des humains. Il s'agit du modèle de prédiction du langage de troisième génération de la série GPT-n créé par OpenAI, un laboratoire de recherche en intelligence artificielle basé à San Francisco et composé de la société à but lucratif OpenAI LP et de sa société mère, la société à but non lucratif OpenAI Inc.
Debut 2020, OpenAI a annoncé que son générateur de texte GPT-3 avait franchi la barre de 300 applications qui lutilise, et qu'il produit 4,5 milliards de mots par jour, avec une précision de 91 %. « Neuf mois après le lancement de notre premier produit commercial, l'API OpenAI, plus de 300 applications utilisent désormais GPT-3, et des dizaines de milliers de développeurs du monde entier construisent sur notre plateforme. Nous générons actuellement en moyenne 4,5 milliards de mots par jour et nous continuons à faire augmenter le trafic de production », avait déclaré OpenAI.
Il existe plusieurs propriétés que les développeurs manipulent pour améliorer les performances d'un modèle pendant la phase de formation. Ces « hyperparamètres » sont distincts des données et sont souvent ajustés manuellement sur la base de la seule intuition. Pour trouver les hyperparamètres optimaux, il faut entraîner et ajuster le modèle de nombreuses fois ; tous ces calculs sont coûteux et prennent beaucoup de temps. À mesure que les systèmes deviennent de plus en plus grands avec des milliards et des milliards de milliards de paramètres, ils deviennent trop coûteux de les affiner.
« Dans la pratique, les gens s'appuient sur de nombreuses règles empiriques pour deviner les hyperparamètres à utiliser pour un grand modèle, sans être sûrs de leur optimalité », ont déclaré Greg Yang, chercheur principal chez Microsoft, et Edward Hu, doctorant au Mila, un institut de recherche basé à Montréal.
Le réglage des hyperparamètres (HP) dans l'apprentissage profond est un processus coûteux, prohibitif pour les réseaux de neurones (NNs) avec des milliards de paramètres. Microsoft montre que, dans la paramétrisation de mise à jour maximale (μP) récemment découverte, de nombreux HP optimaux restent stables même si la taille du modèle change. Cela conduit à un nouveau paradigme de réglage des HP que les chercheurs de Microsoft appelent μTransfer : paramétrer le modèle cible dans μP, régler les HP indirectement sur un modèle plus petit, et zero-shot transfer les transférer au modèle de taille réelle, c'est-à-dire sans régler directement ce dernier du tout.
Les chercheurs vérifient μTransfer sur Transformer et ResNet :
- en transférant les HP de pré-entraînement d'un modèle de 13M de paramètres, nous surpassons les chiffres publiés de BERT-large (350M de paramètres), avec un coût total de réglage équivalent au pré-entraînement de BERT-large une fois ;
- en transférant de 40M de paramètres, nous surpassons les chiffres publiés du modèle GPT-3 de 6.7B, avec un coût de réglage de seulement 7 % du coût total de pré-entraînement. Une implémentation Pytorch de notre technique est disponible sur github.com/microsoft/mup et peut être installée via pip install mup.
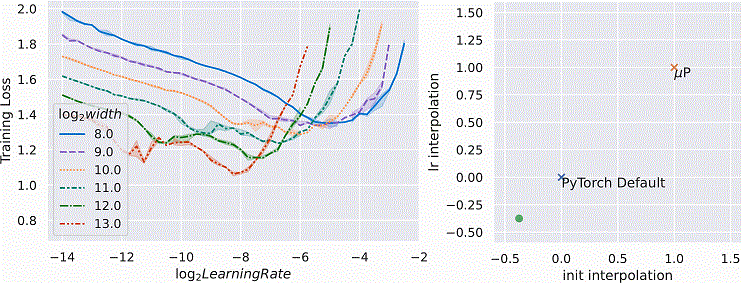
μP s'avère être la seule paramétrisation « naturelle » qui possède cette propriété de stabilité des hyperparamètres sur la largeur, comme vérifié empiriquement dans le gif ci-dessous sur des MLP formés avec SGD. Ici, à travers le temps, les chercheurs interpolent entre la valeur par défaut de PyTorch et le taux d'apprentissage et les mises à l'échelle d'initialisation de μP (à droite), et ils mettent à l'échelle le modèle de largeur 256 (log2(largeur)=8) à la largeur 2^13 = 8192 en utilisant cette règle d'échelle interpolée (à gauche).
Ce repo contient le code source du package mup, loutil qui rend l'implémentation de μP dans les modèles Pytorch sans effort et avec moins d'erreurs.
Avec des chercheurs d'OpenAI, Greg Yang et Edward Hu ont conçu une méthode décrite dans un article, nommée μTransfer (prononcez mu-transfer) pour faciliter le réglage fin des grands réseaux neuronaux. Dans un premier temps, ils trouvent les hyperparamètres optimaux en bricolant un modèle plus petit, puis les transfèrent à un système plus grand et à plus grande échelle. L'équipe a expérimenté le μTransfert sur l'architecture GPT-3 de génération de texte, en réutilisant les hyperparamètres d'un modèle de 40 millions de paramètres vers un modèle de 6,7 milliards de paramètres.
Microsoft a annoncé en 2019 un investissement d'un milliard de dollars dans OpenAI en vue de développer de nouvelles technologies utilisant l'intelligence artificielle. Cela lui permet également de devenir le fournisseur exclusif de services de cloud computing pour la firme d'Elon Musk. Le fruit de cette collaboration a vu le jour en mai 2020 avec la sortie d'un nouveau supercalculateur construit exclusivement pour OpenAI sur Azure. Comme l'avait indiqué la société, ce superordinateur est la cinquième machine la plus performante au monde.
En septembre 2020, Microsoft a renforcé son partenariat avec OpenAI grâce à un accord signé dans le cadre du GPT-3. En effet, le géant de la technologie basé à Redmond dans l'État de Washington a acheté une licence exclusive de la technologie sous-jacente à GPT-3. Suite à cette collaboration, Kevin Scott n'a pas manqué de faire part de ses sentiments, tout en expliquant les avantages qu'elle apporte à la firme de Redmond ainsi qu'à leurs clients.
« Je suis très heureux dannoncer que Microsoft sassocie à OpenAI pour obtenir la licence exclusive de GPT-3, ce qui nous permettra de tirer parti de ses innovations techniques pour développer et fournir des solutions dIA avancées à nos clients, ainsi que pour créer de nouvelles solutions qui exploitent lincroyable puissance de la génération avancée du langage naturel. Nous considérons quil sagit dune opportunité incroyable détendre notre plateforme dIA alimentée par Azure dune manière qui démocratise la technologie de lIA, permet de nouveaux produits, services et expériences, et augmente limpact positif de lIA à grande échelle », a-t-il expliqué.
Microsoft poursuit cette vision depuis un certain temps par le biais de Power Platform, sa suite de logiciels low code, no code destinée aux entreprises. Ces programmes fonctionnent comme des applications Web et aident les entreprises qui ne peuvent pas embaucher des programmeurs expérimentés à s'attaquer à des tâches numériques de base comme l'analyse, la visualisation des données et l'automatisation des flux de travail. Les qualités de GPT-3 ont trouvé une place dans PowerApps, un programme de la suite utilisé pour créer des applications web et mobiles simples.
En mAI 2021, Microsoft a annoncé son premier cas dutilisation commerciale de GPT-3 : une fonction d'assistance dans le logiciel PowerApps de l'entreprise qui transforme le langage naturel en code prêt à l'emploi. La fonctionnalité est limitée dans son champ d'application et ne peut produire que des formules en Microsoft Power Fx, un langage de programmation simple dérivé des formules de Microsoft Excel. « Il y a une demande massive de solutions numériques, mais pas assez de programmeurs sur le terrain. Rien qu'aux États-Unis, il manque un million de développeurs », explique Charles Lamanna, CVP de la plateforme d'applications à faible code de Microsoft. « Alors au lieu de faire en sorte que le monde apprenne à coder, pourquoi ne pas faire en sorte que les environnements de développement parlent le langage d'un humain normal ? »
Tester le µTransfert
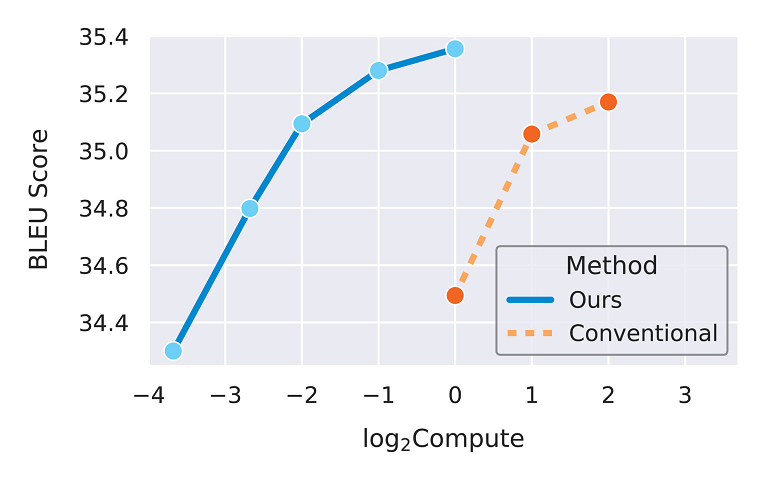
Maintenant que le transfert des hyperparamètres individuels a été verifié, il est temps de les combiner dans un scénario plus réaliste. Dans la figure ci-dessous, les chercheurs comparent µTransfer, qui transfère les hyperparamètres réglés à partir d'un petit modèle proxy, avec le réglage direct du grand modèle cible. Dans les deux cas, le réglage est effectué par recherche aléatoire. La figure illustre une frontière de Pareto du budget de calcul relatif du réglage par rapport à la qualité du modèle réglé (score BLEU) sur IWSLT14 De-En, un jeu de données de traduction automatique. Pour tous les niveaux de budget de calcul, µTransfer est environ un ordre de grandeur (en base 10) plus efficace en termes de calcul pour le réglage. Nous nous attendons à ce que cet écart d'efficacité s'accroisse considérablement lorsque nous passons à des modèles cibles de plus grande taille.
Pour les différents budgets de réglage, µTransfer domine la méthode de base qui consiste à régler directement le modèle cible. Au fur et à mesure que des modèles cibles plus grands sont formés avec des milliards de paramètres, les chercheurs sattendent à ce que l'écart de performance se creuse, puisque le modèle proxy peut rester petit tout en prédisant de manière significative les hyperparamètres optimaux.
Un aperçu de l'avenir : µP + GPT-3
Avant ce travail, plus un modèle était grand, moins il était bien réglé, en raison du coût élevé du réglage. Par conséquent, beaucoup pensaient que les plus grands modèles pourraient bénéficier le plus de µTransfer, c'est pourquoi Greg Yang et Edward Hu se sont associés à OpenAI pour l'évaluer sur GPT-3.
Après avoir paramétré une version de GPT-3 avec une attention relative dans µP, ils ont réglé un petit modèle proxy avec 40 millions de paramètres avant de copier la meilleure combinaison d'hyperparamètres sur la variante de 6,7 milliards de paramètres de GPT-3, comme prescrit par µTransfer. Le calcul total utilisé pendant cette étape de réglage n'a représenté que 7 % du calcul utilisé pour le pré-entraînement du modèle final de 6,7 milliards. Ce modèle µTransfer a surpassé le modèle de la même taille (avec une attention absolue) dans l'article original GPT-3.
Selon l'article original GPT-3, des travaux récents ont démontré des gains substantiels sur de nombreuses tâches et repères de PNL en effectuant un pré-entraînement sur un grand corpus de texte suivi d'un réglage fin sur une tâche spécifique. Bien que l'architecture de cette méthode soit généralement indépendante de la tâche, elle nécessite toujours des ensembles de données de réglage fin spécifiques à la tâche, composés de milliers ou de dizaines de milliers d'exemples.
En revanche, les humains peuvent généralement effectuer une nouvelle tâche linguistique à partir de quelques exemples seulement ou d'instructions simples, ce que les systèmes NLP actuels ont encore beaucoup de mal à faire.
Les chercheurs Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, universitaires, montrent que la mise à l'échelle des modèles de langage améliore grandement les performances de la tâche à partir de quelques exemples, atteignant même parfois la compétitivité avec les approches de réglage fin de l'état de l'art.
Plus précisément, ils entraînent GPT-3, un modèle de langage autorégressif avec 175 milliards de paramètres, soit 10 fois plus que tout autre modèle de langage non épars précédent, et testent ses performances dans le cadre du few-shot. Pour toutes les tâches, GPT-3 est appliqué sans aucune mise à jour du gradient ou réglage fin, les tâches et les démonstrations en quelques secondes étant spécifiées uniquement par l'interaction du texte avec le modèle.
GPT-3 obtient d'excellentes performances sur de nombreux ensembles de données NLP, y compris les tâches de traduction, de réponse aux questions et de cloze, ainsi que plusieurs tâches qui nécessitent un raisonnement à la volée ou une adaptation au domaine, comme le déchiffrage de mots, l'utilisation d'un nouveau mot dans une phrase ou l'exécution d'une arithmétique à trois chiffres. Dans le même temps, les chercheurs identifient également certains jeux de données où l'apprentissage en quelques clics de GPT-3 pose encore problème, ainsi que certains jeux de données où GPT-3 est confronté à des problèmes méthodologiques liés à l'entraînement sur de grands corpus web.
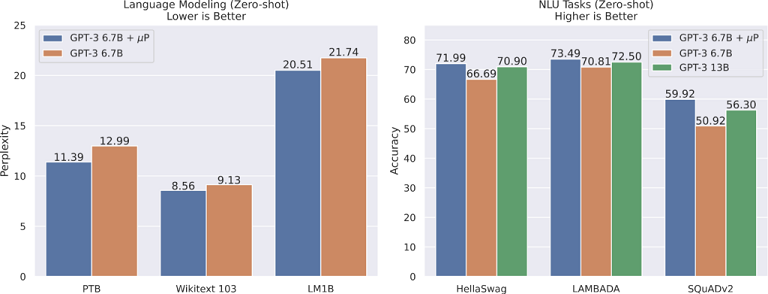
Enfin, les chercheurs constatent que GPT-3 peut générer des échantillons d'articles de presse que les évaluateurs humains ont du mal à distinguer des articles écrits par des humains. Cependant, les performances obtenues par Greg Yang, chercheur principal chez Microsoft, Edward Hu, doctorant au Mila et les chercheurs de OpenAi sont similaires à celles du modèle (avec attention absolue) avec le double du nombre de paramètres exploité par . Les chercheurs Tom B. Brown, Benjamin Mann, Nick Ryder et ses collègues comme le montre la figure ci-dessous.
Comme dit précédemment, µTransfer a été appliqué au modèle GPT-3 de 6,7 milliards de paramètres avec attention relative et obtenu de meilleurs résultats que le modèle de référence avec attention absolue utilisé dans l'article original GPT-3, tout en ne dépensant que 7 % du budget de calcul de pré-entraînement pour le réglage. Les performances de ce modèle µTransfer 6,7 milliards sont comparables à celles du modèle 13 milliards (avec attention absolue) de l'article original GPT-3.
Implications pour la théorie de l'apprentissage profond
Comme montré précédemment, µP donne une règle de mise à l'échelle qui préserve de manière unique la combinaison optimale d'hyperparamètres dans les modèles de différentes largeurs en termes de perte d'apprentissage. À l'inverse, d'autres règles de mise à l'échelle, comme celle par défaut de PyTorch ou la paramétrisation NTK étudiée dans la littérature théorique, s'intéressent à des régions de l'espace des hyperparamètres de plus en plus éloignées de l'optimum à mesure que le réseau s'élargit.
À cet égard, Microsoft estme que la limite d'apprentissage des caractéristiques de µP, plutôt que la limite NTK, est la limite la plus naturelle à étudier si l'objectif est de tirer des enseignements applicables aux réseaux neuronaux d'apprentissage des caractéristiques utilisés dans la pratique. Par conséquent, les théories plus avancées sur les réseaux neuronaux surparamétrés devraient reproduire la limite d'apprentissage des caractéristiques de µP dans le cadre de la grande largeur.
Appliquer µTransfer à vos propres modèles
Même si les mathématiques peuvent être intuitives, les chercheurs ont constaté que la mise en uvre de µP (qui permet µTransfer) à partir de zéro peut être source d'erreurs. De la même façon, l'implémentation d'autograd est délicate, même si la règle de la chaîne pour prendre les dérivées est très simple. C'est pour cette raison qu'ils ont créé le paquet mup afin de permettre aux praticiens d'implémenter facilement µP dans leurs propres modèles PyTorch, tout comme des cadres tels que PyTorch, TensorFlow et JAX nous ont permis de prendre autograd pour acquis. Notons que µTransfer fonctionne pour les modèles de toute taille, et pas seulement ceux qui comportent des milliards de paramètres.
Selon Intel, l'informatique neuromorphique consiste à repenser entièrement l'architecture des ordinateurs, de bas en haut. L'entreprise a annoncé l'année dernière un partenariat avec Sandia National Laboratories (Sandia) pour explorer la valeur de l'informatique neuromorphique. Sandia lancera ses recherches en utilisant un système Loihi de 50 millions de neurones qui a été livré à ses installations d'Albuquerque, au Nouveau-Mexique.
Ce travail avec Loihi jettera les bases de la phase ultérieure de la collaboration, qui devrait inclure la poursuite de la recherche neuromorphique à grande échelle sur l'architecture neuromorphique de prochaine génération d'Intel et la livraison du plus grand système de recherche neuromorphique d'Intel à ce jour, qui pourrait dépasser plus d'un milliard de neurones en capacité de calcul.
L'objectif est d'appliquer les dernières connaissances issues des neurosciences pour créer des puces qui fonctionnent moins comme des ordinateurs traditionnels et plus comme le cerveau humain. Les systèmes neuromorphiques reproduisent la manière dont les neurones sont organisés, communiquent et apprennent au niveau du matériel. Intel considère que sa puce de recherche Loihi et ses futurs processeurs neuromorphes définissent un nouveau modèle d'informatique programmable pour répondre à la demande croissante de dispositifs intelligents et omniprésents dans le monde.
Théorie des programmes tensoriels
Les avancées décrites ci-dessus sont rendues possibles par la théorie des programmes tensoriels (TPs) développée au cours des dernières années. Tout comme autograd aide les praticiens à calculer le gradient de tout graphe de calcul général, la théorie des programmes tensoriels permet aux chercheurs de calculer la limite de tout graphe de calcul général lorsque ses dimensions matricielles deviennent grandes.
Appliquée aux graphes sous-jacents de l'initialisation, de la formation et de l'inférence des réseaux neuronaux, la technique TP permet d'obtenir des résultats théoriques fondamentaux, tels que l'universalité architecturale de la correspondance entre les réseaux neuronaux et les processus gaussiens et le théorème de la dichotomie dynamique, en plus de dériver µP et la limite d'apprentissage des caractéristiques qui a conduit à µTransfer. Pour l'avenir, nous pensons que les extensions de la théorie TP à la profondeur, à la taille des lots et à d'autres dimensions d'échelle sont la clé d'une mise à l'échelle fiable des grands modèles au-delà de la largeur.
Source : Microsoft
Et vous ?
Que pensez-vous de la méthode de Microsoft et d'OpenAI qui pourrait rendre la formation de grands réseaux neuronaux moins coûteuse ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager