









Bonjour à tous,
Comme je l'ai dit lors de mes précédents postes je débute en sql et si j'ai bien compris un truc c'est que j'ai pas encore la logique du sql et donc mes requêtes sont loin d'être optimisées.
Donc là j'ai une requête qui prende pret de 20min à s'éxécutée et je voudrais avoir si d'après il y aurait des astuces pour l'optimiser ?
Pour décrire un peu ce que j'y fais :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
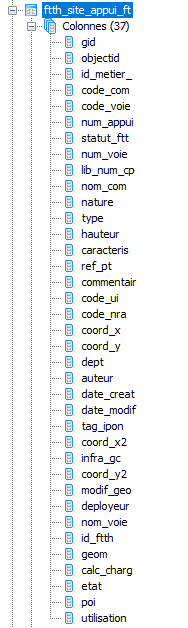
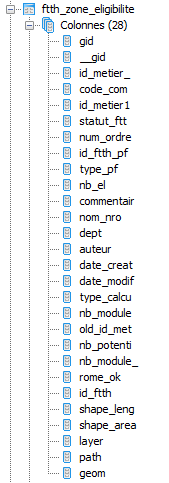
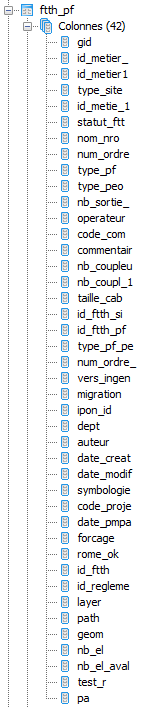
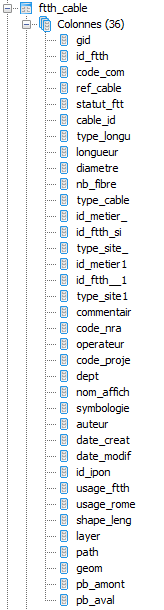
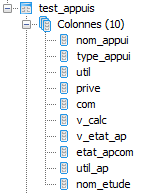
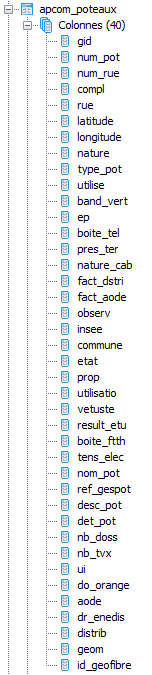
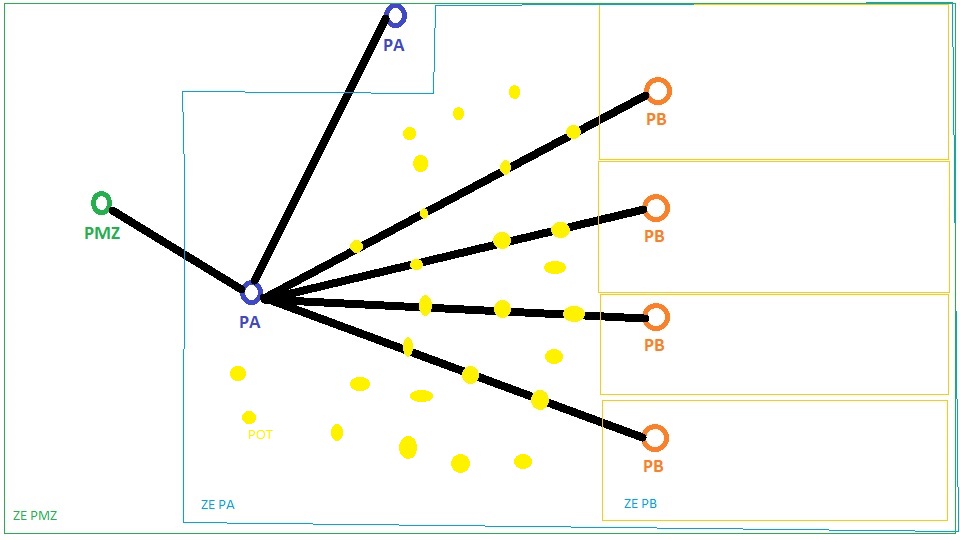
Je récupère des points sur une carte (ft)
Je les joints a des zones géographiques (z) pour récupérer le point principale de la zone (z.id_metier_)
Je joins alors le point principal (z.id_metier_) trouvé avec la liste des points principaux (pm) pour y récupéré certaines infos
Je joins enfin des câbles avec mes points du départ pour trouver les points qui sont dans la zone mais pas sur ces câbles
Je joins enfin une autre table (ta) pour récupérer d'autres infos (ta.util,ta.com)
Je joins encore une autre table (ap) pour récupérer d'autres infos (ap.result_etu)
Voilà je sais pas si vous auriez besoin d'autres infos pour me donner quelques conseils ?
 Répondre avec citation
Répondre avec citation




















Partager