












HSBC, un groupe bancaire, simplifie son modèle de données en passant de 65 bases de données relationnelles
à une seule base de données MongoDB pour tous les pays
La semaine passée, Narasimha Reddy, concepteur de données chez HSBC, un groupe bancaire international britannique, a expliqué comment l'organisation cherche à simplifier son approche de la livraison d'applications en migrant de 65 bases de données relationnelles vers une instance mondiale de MongoDB. HSBC est l'une des organisations de services bancaires et financiers les plus reconnues au monde, opérant dans plus de 60 pays et servant plus de 40 millions de clients. Cependant, cette échelle s'accompagne d'une complexité opérationnelle importante, notamment en ce qui concerne la manière dont la banque fournit ses applications et ses modèles de données.
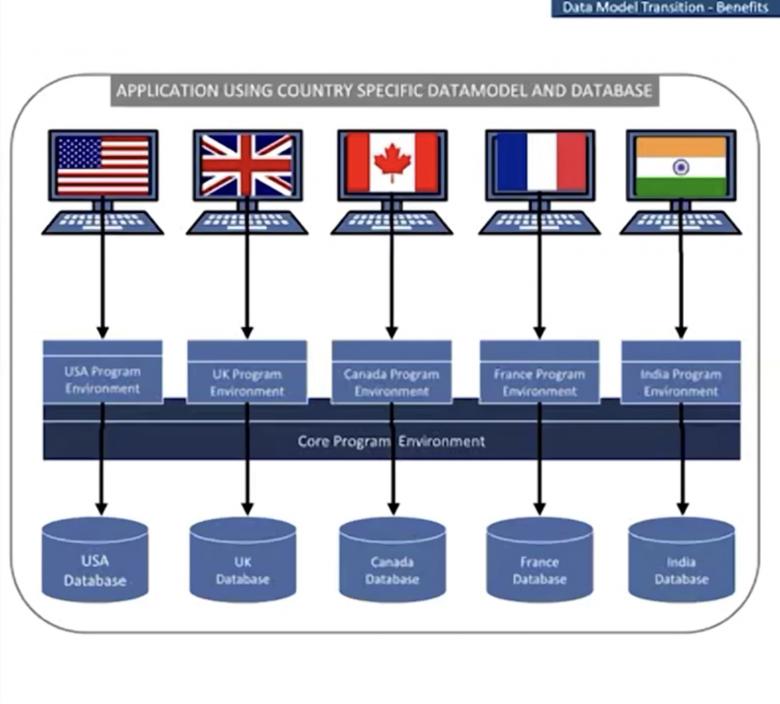
Reddy a expliqué comment l'image ci-dessous a créé un modèle de données global complexe pour les applications, qui a créé un modèle à coût élevé à chaque étape du cycle de développement logiciel. Cela rend impossible le maintien d'une version de l'application et d'un modèle de données dans le monde des bases de données relationnelles, dit-il.
Reddy a déclaré que HSBC cherchait à réaliser un modèle de données mondial et, par conséquent, une base de données unique pour tous les pays. Les avantages de ceci incluent des coûts réduits, une flexibilité et la possibilité d'exécuter plus facilement des analyses et des rapports mondiaux (chaque pays fonctionnant sur un modèle de données unique).
Dans la pratique, cela signifie que chaque pays sera en mesure de maintenir ses exigences de demande individuelle, mais sans avoir à exploiter une base de données de pays unique. Un modèle de données unique est en cours de création, ce qui permet non seulement d'économiser sur les coûts et les ressources pour HSBC, mais lui donne la liberté de faire avancer sa propre conception de modèle de données.
Comme le montre l'image ci-dessus, HSBC avait un environnement de base de programme d'application, qui avait la plupart des fonctionnalités de base d'une application. Mais il ne pouvait pas avoir un seul environnement de programme en cours d'exécution pour tous les pays, en raison des différences dans les modèles de données et les bases de données.
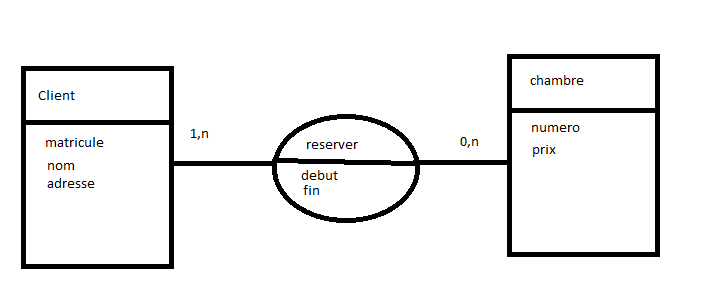
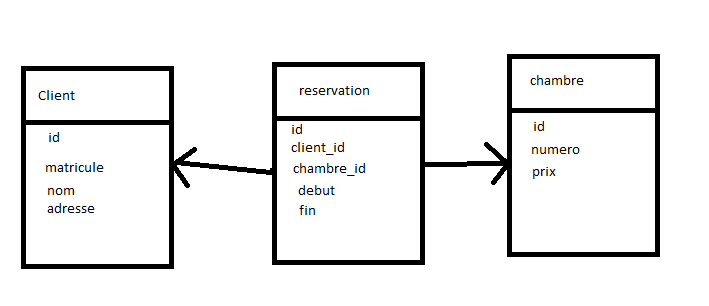
Selon l'image ci-dessous, HSBC a maintenant une nouvelle architecture selon laquelle plusieurs pays à travers le monde utilisent la même application. C'est maintenant un environnement de service, une base de données et un chemin d'exécution pour tous les pays. Cela est rendu possible grâce au modèle de document de MongoDB et à la possibilité de mapper toutes les différentes exigences de tableau pour chaque pays dans une seule collection, en utilisant des sous-documents. Tout est simplifié en une seule collection en utilisant des identifiants spécifiques au pays.
« Les exigences locales pour chaque pays seront intégrées dans l'application, mais il n'est plus nécessaire de maintenir des modèles de données ou des bases de données distincts. Nous pourrions facilement concevoir le modèle de données global et la base de données en utilisant le modèle de schéma MongoDB JSON. Cela rassemble les données de tous les pays dans une seule base de données et l'application peut fonctionner sur une seule base de données. Ce qui représente beaucoup de réduction des ressources et des coûts de maintenance.
Un autre avantage est d'utiliser la même base de données pour l'analyse des données et les rapports globaux. Nous n'avons pas besoin de traduire dans un autre modèle de données ou une autre base de données pour exécuter l'analyse et les rapports à partir de ces données particulières. Tout cela entraîne de grandes économies de ressources et de coûts. J'ai appris en utilisant MongoDB que lorsqu'une base de données est sans schéma et fournit des requêtes et une indexation puissantes, je pilote la conception de mon modèle de données, pas la base de données », dit-il pour conclure.
Les internautes ne partagent pas le point de vue de Narasimha Reddy. Pour eux, un ensemble de microservices partageant une instance de base de données est un peu un anti-modèle.
Source : Diginomica
Et vous ?
Qu'en pensez-vous ?
Voir aussi

 Répondre avec citation
Répondre avec citation











 N'oubliez pas le bouton
N'oubliez pas le bouton  et pensez aux balises [code]
et pensez aux balises [code]













Partager